
SimonMorris

ServiceNow Employee
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
09-21-2011
07:32 AM
One of the bloggers that I follow - the anonymous ITILGirl (follow her on Twitter) - posted an interesting account of a service failure, and the fallout between users, the servicedesk and externa...
It's worth remembering that although ITSM vendors aim their offering at the CXO level (CEO, CIO, CTO) the majority of users who live and die by the product are members of the Servicedesk and Technical Management teams.
They are the ones (She is the one...) at the sharp end of the situation between the customer and the service affecting issue. Reading her post I notice she highlights the lack of communication as the biggest problem...
So here, most of the issue was communication. I expect better communication. I had asked the external suppliers to wait for my command before I allowed them to reboot the server. This just made the customer more agitated, because they rebooted it when I gave the customer instructions to log back in. This made me look unprofessional.
I wrote a post a few months ago about the habits of successful infrastructure teams where I noted:
Bad news is better than no news.
Be happy to deliver bad news. Seek it out and enthuisastically deliver it to your customer or user. Firstly you'll quickly tire of the awkward conversations and find ways to avoid the causes of bad news. Secondly there is nothing more frustrating to a user than a lack of information.
Often the IT organisation is supporting the needs of it's customers to achieve their objectives. If we have failed to deliver... and then failed to deliver the bad news in a timely matter... it's no surprise that our credibility suffer. Bad news is better than no news.
From my experience in IT Operations users feel doubly frustrated when they get conflicting, vague, over-optimistic or perhaps no news at all from their IT department during an outage.
So reading about ITILGirls bad day I get the feeling that she would have had an easier ride with the benefit of 2 things:
- Better inter-personal communication: Between the Servicedesk and the vendor
- Better tools
The first one takes time to shift, and it's a cultural thing. She talks about her "fantastic" Service Desk Manager who will escalate the failings of the external support organisation. I don't think the problem with cross-organisational communication will ever be an easy thing.
I'm interested in exploring the second factor that ITILGirl was missing - Better tools.
It's interesting that she didn't mention Event Management in her post - perhaps it's a discipline that the Infrastructure team in her organisation doesn't do that well, or does it in a silo.
I've seen critical services be disrupted due to lack of disk space, and it's the most sickening of feelings. You can perhaps blame a blown network switch on "The Gods" or "Karma" or "Bad Luck". But to review a monitoring graph of a disk volume being eaten away over time, and knowing that the Event Management process didn't pick it up - not a good one.
Perhaps they do Event Management, but don't tie it into the Servicedesk in a useful way. If ITILGirl had the information pushed into her line of sight to highlight an event on a critical server she could have set user expectations better.
This blog post isn't about pimping ServiceNow as a solution, but it's easy to show screenshots from our product to explain the point.
ITILGirl should have access to information that helps her do her job - I don't think anyone would disagree here, but is it a lack of maturity in either the ITSM deployment in her organisation or her toolset that stops her from giving accurate information to her users.
The process should be....
So ITILGirl gets a call from a user complaining about a disruption in service.
She opens a new Incident form and logs the issue quickly, associating the issue with a Business Service (or perhaps Application) that has the issue. She saves the Incident record.

Before doing too much diagnosis on the issue she checks the Business Service for existing Incidents or Problems. In ServiceNow this is implemented as a Business Service Map accessible via this icon.

Looking at the downstream relationships (arrows flowing from left to right across the map) she can see which components might be contributing to a service impacting issue.

Hopefully her Infrastructure team is using Event Management to automatically raise Incident records when certain thresholds (disk space utilisation would be a good one) so she has all the information to hand.
And how long would all this take? Probably about 38 seconds if she had the toolset.
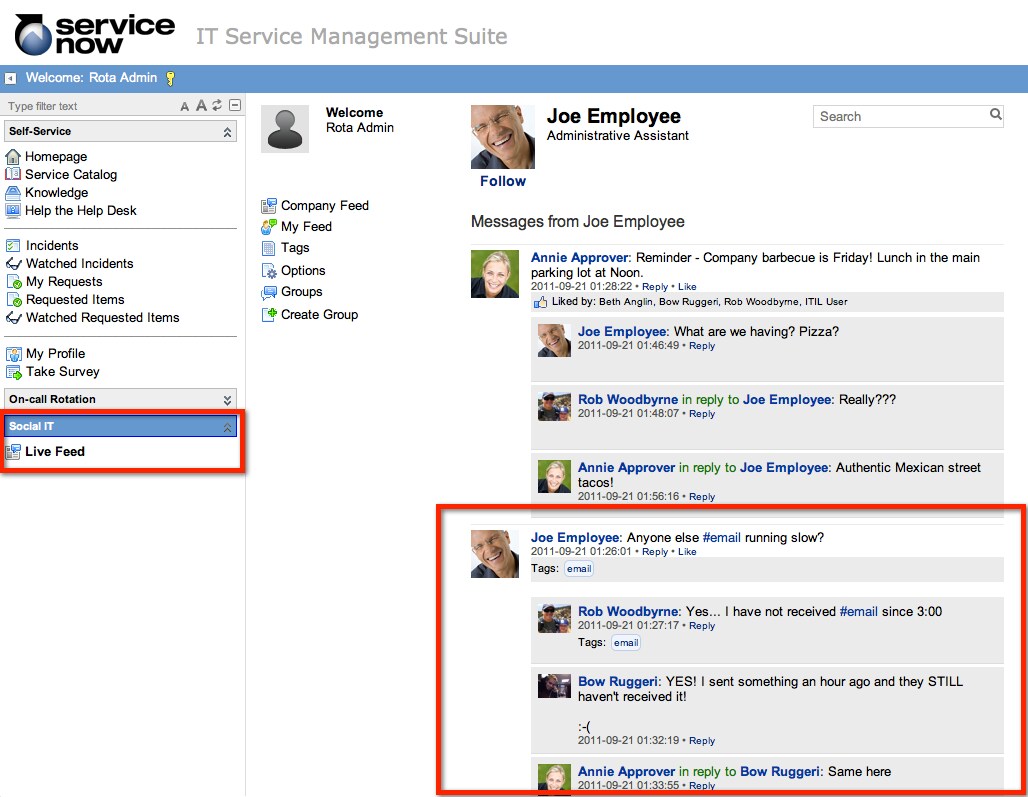
Lastly - how can she communicate this issue to users in an effective way. Tools like SocialIT help massively here. Giving users a central location to gather around, receive updates and discuss the issue. It might seem counter-intuitive to give users a platform to complain about IT problems, but it's also an opportunity to communicate "bad news" well

Communication is a cultural problem, but having the right tools to hand really help.
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}