

drjohnchun
Tera Guru
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
09-28-2016
10:30 AM
Last time, we saw how Data Certification and Independent Review/Audit are used to ensure CMDB data quality. We also saw how statistical sampling may be used for Data Certification and it can almost always be used for Independent Review/Audit. Let's now create a fictitious CMDB and start crunching numbers to see how statistical sampling works in practice. In all cases, we'll work with the margin of error of ± 5% at 95% confidence level.
Our fictitious CMDB contains the following CIs:
| CI Type | Count | Sample Size* | % Sample / Count |
|---|---|---|---|
| Services | 100 | 80 | 80% |
| Applications | 1,000 | 278 | 28% |
| Servers | 5,000 | 357 | 7% |
| Databases | 3,000 | 341 | 11% |
| Storage | 900 | 270 | 30% |
| Total | 10,000 | 370 | 4% |
* for ± 5% margin of error at 95% confidence level
Shown in the third column are the sample sizes for each CI Type when the CI Count is used as population. We can immediately see that the relative sample size compared to the population (Count) becomes larger as the population becomes smaller as shown in the last column; for Services, the sample size is 80% of the population whereas for Servers, it's only 7%. Let's see why below.
SAMPLE-SIZE CALCULATION
Sample size is calculated, at 95% confidence level, using
where Population is population size and Error is margin of error. When the result is in decimal, round it up to the nearest integer (ceiling). In Excel, using named cells Population and Error, this can be written as
=CEILING(1/(1/Population + (2*Error/1.96)^2),1)
and in JavaScript, it's
var sample_size = Math.ceil(1 / (1 / population + Math.pow(2 * error / 1.96, 2)));
A sample-size calculator based on this formula is available online at SurveyMonkey. When the population is huge, as we saw with the election poll example in Part 1, the term 1/Population is almost zero, resulting in the simple relationship between the Margin of Error and Sample Size we saw in Part 1. If we further assume 5% margin of error, this simplifies to

From this, we see that as Population increases, Sample Size increases only gradually, maxing out at 385 (384.16 rounded up); so no matter how large population size is, we need a sample size no more than 385 to get ± 5% margin of error at 95% confidence level.
DATA CERTIFICATION
Now that we know how to calculate sample size, let's look at some practical examples. Let's say we're performing data certification for applications, all 1,000 of them. There may be some fields and relationships that need to be manually verified, which add to the time and effort. Instead of tackling all records at once, it may be useful to get preliminary results by taking a random sample of 278 application CI records. This will give us a ballpark figure (within ± 5% margin of error) ahead of time; for example, are we looking at 90% pass rate? 80%? Perhaps even 70%? Knowing this may help us prepare for any actions that need to be taken later. When we're finished with all 1,000 CI records, we can further validate our statistical approach.
We can also take a hybrid approach as mentioned in Part 2; for critical applications, every single record is evaluated whereas statistical sampling is used for the rest. Let's say out of 1,000 applications, 200 are critical (SOX, GxP, security, etc.). We can evaluate the rest 800 applications using a sample size of 260.
INTERPRETING RESULTS
Let's review once again what statistical sampling results mean. From the above example, let's say we reviewed a sample of 278 application CI records out of the population of 1,000. Of the 278 CIs, 270 passed and 8 failed. This gives 97 ± 5% confidence interval, so we expect the true value to be somewhere between 92% and 100%, or as low as 92% (this is a conservative estimate). If the minimum threshold for passing is 90%, the results are acceptable; on the other hand, if the minimum threshold is 95%, then the results are unacceptable.
DEFINING POPULATION
Population must be defined based on the objectives. As we saw above, if we are to certify all applications, then the correct population to be used is 1,000. However, if we are to certify non-critical applications only, then the population is reduced to 800 and the results may read, for example, "of the 800 non-critical applications, at least 90% passed certification."
If we are to evaluate the entire CMDB, then the population to be used is 10,000, resulting in the sample size of 370. Let's say the results show at least 90% pass rate; this applies to the entire CMDB but not to the individual CI types that make up the CMDB. For example, due to the randomness of the sample, close to 50% (185) of the sample may be servers (since servers make up half of the entire CMDB). Here, we can't claim "at least 90% pass rate for servers"; for us to be able to do that, we'll have to evaluate 357 sample records just from 5,000 servers.
In ServiceNow, if a filter is used to reduce the number of target records, then, typically, the result set is the population.
ENSURING RANDOMNESS
For the statistical sampling techniques to work, sample must be drawn at random without any bias; "random" in this context means "every record has an equal probability of being selected." Some may choose to select an arbitrary 20% of the population as sample by taking every fifth record (this is called systematic sampling); this doesn't ensure randomness, although may be acceptable in some auditing practices. A better method for random selection is to assign a random number to a unique key (for example, sys_id) of each record and then to sort by the random numbers; the first n (sample size) records can then be used as sample. Most random number generators, such as those used in JavaScript, Excel, etc., are called "pseudo" random number generators because the results are not truly random. However, they're sufficient for most practical applications.
A "QUICK" CMDB ASSESSMENT
Let's apply what we've seen so far to a practical use case. Let's say you haven't assessed your CMDB for data quality in a while. You'd like to conduct an assessment and, based on the results, take actions. While there are some automated checks in place, some attributes can only be reviewed manually, such as CI ownership that is used in change management workflows. You'd like to assess the entire CMDB, with 100,000 CIs (this is 10 times the CIs we had above). This includes "inactive" CIs as well since you'd like to make sure the "inactive" status was set correctly by discovery tools. The population size then is 100,000.
The sample-size calculator tells you the sample size to be used is 383. You select random sample and assign them to several people to speed up the progress, with an instruction on what to review and clear definitions of pass/fail. The results are ready at the end of the day and they don't look good; 333 (87%) passed and 50 failed, below the minimum 90% threshold you were hoping for. The failed CIs were mostly in applications and servers; you decide to conduct assessments just for them the next day. You also found 3 "inactive" CIs that should've been "active"; you decide to conduct a separate assessment just on "inactive" CIs.
Manually reviewing 100,000 records would be challenging. On the other hand, 383 records are much more manageable. Although the results are only ballpark figures, statistical sampling provides a "quick" way to gain insights and draw conclusions. As we just saw above, the insights can be used to further refine the results.
Next time, we'll look at how some ServiceNow applications and features may relate to the techniques we have seen so far.
Please feel free to connect, follow, post feedback / questions / comments, share, like, bookmark, endorse.
John Chun, PhD PMP ![]()

Labels:
1 Comment
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.


{kind=link}
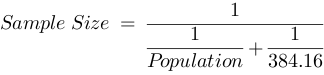{kind=link}