- Post History
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
05-15-2018 09:32 AM - edited 08-28-2023 12:08 PM
Introduction
This article is for customers setting up data archiving for the first time. The goal is to provide administrators confidence in their data archival policy and strategy. As time goes by, data in your tables grows and begins to slow your queries. This results in a less-than-optimal user experience. To help keep your tables performing well, archive inactive data to reduce the active table's size. The ServiceNow documentation site has an article on Data Archiving that should provide you with relevant information data archiving. The following steps will walk you through setting up archiving for the first time.
The benefits of archiving will be to have light-weight tables to maximize performance, provide a better user experience, and help make upgrades faster.
Step 1: Determine what tables to begin archiving
Start in a newly-cloned sub-prod instance. Ideally, you should set up an archival policy on all of your tables. The attachments, journals, and audit tables are managed separately for performance and will get cleaned up when destroy rules are run, so no need to setup archive rules for these. Some examples of tables to archive are Incident, Problem, Change, Knowledge, CMDB, Email (there is a separate plugin for email), etc. For most customers that have been using ITSM for a while, the Incident table is a good place to start because there is usually a constant stream of records being inserted. The table has most likely become large and showing signs of slowing down. Now that we've targeted the Incident table, lets move on to the next step of figuring out when we should archive a record.
Step 2: Determine when to archive a record
Using the Incident table, let's figure out your date ranges. The rule we will create will have a trigger based on a date field like Incident.Closed because we want to archive incidents closed before a certain time frame, like 350 days ago. For the Knowledge table, we might pick the Updated date field and in a Retired state to know when it can be archived.
Here are two ways to determine our total time period for Incidents.
1. Run a background script similar to this (more exact way).
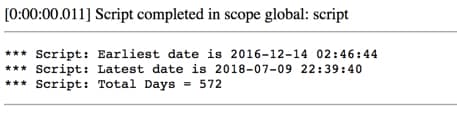
Here is a script to run in Scripts - Background to tell you how long Incidents have been in the table (earliest date until most recent):
var timeEarliest;
var timeLatest;
var grIncidents = new GlideRecord('incident');
grIncidents.addNotNullQuery('closed_at');
grIncidents.orderBy('closed_at');
grIncidents.setLimit(1);
grIncidents.query();
if (grIncidents.next()){
gs.print('Earliest date is ' + grIncidents.closed_at);
timeEarliest = new GlideDateTime(grIncidents.closed_at);
}
var grIncidents = new GlideRecord('incident');
grIncidents.addNotNullQuery('closed_at');
grIncidents.orderByDesc('closed_at');
grIncidents.setLimit(1);
grIncidents.query();
if (grIncidents.next()){
gs.print('Latest date is ' + grIncidents.closed_at);
timeLatest = new GlideDateTime(grIncidents.closed_at);
}
duration= GlideDate.subtract(timeEarliest, timeLatest);
gs.print('Total Days = ' + duration.getDayPart());With my demo data, I get this result. I have 572 days of closed incidents.

2. Find the total time for Incidents by using the list view (quick way).
Go to the Incident list, show all records, and sort by Closed date, ascending and then descending - note the earliest closed date and latest, and do the math in your head.
Once we know how many total days our incident records have been out there, let's try a small subset of records to archive.
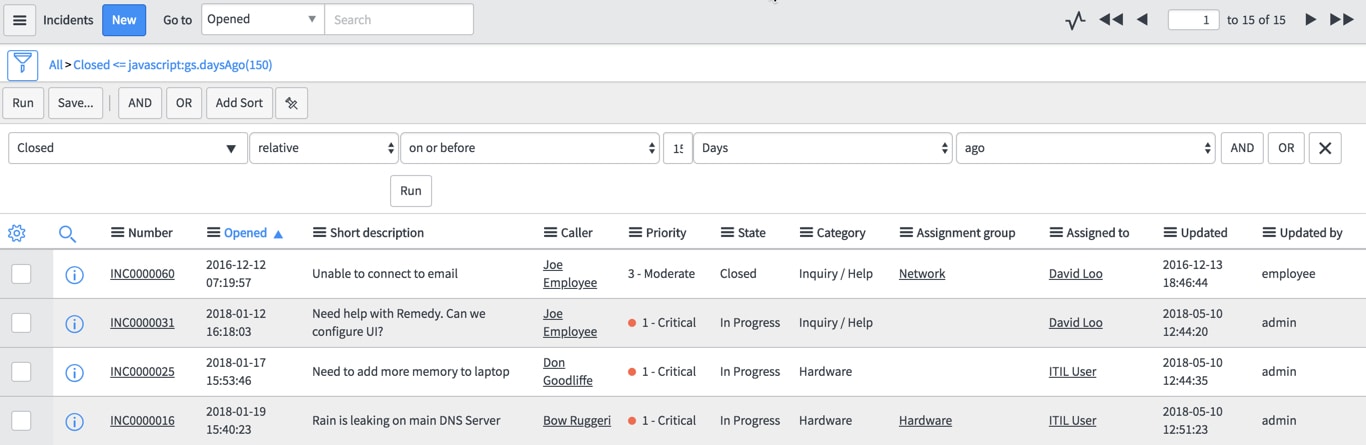
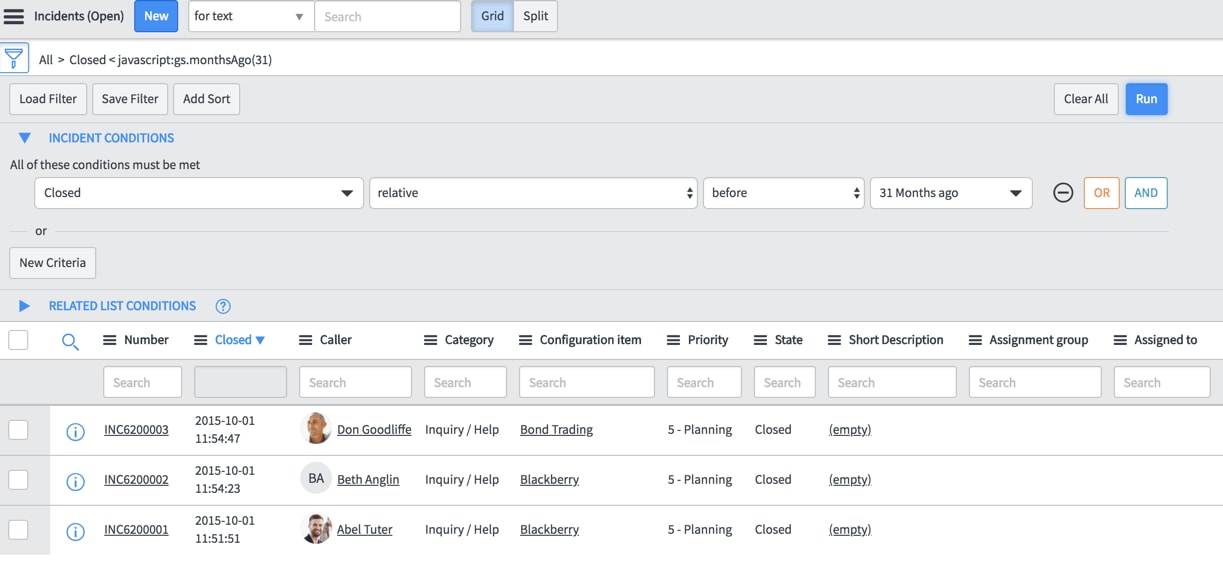
Create a filter to show what we want to archive. Sticking with our total days example, Expand the filter and add a condition where closed is relative, on or before a number of days (150) ago. Also make sure active = false to be very explicit. You should arrive at the exact list of what you expect to archive. If our total days is 572, then we want to archive anything older than a little less than this. If you don't see records, lower the date by a month at a time until you see some records.

With my demo data I had to set my starting point at 150, so I want to start archiving by just trimming off a handful of the earliest incident records. I'll explain why we want to do this later. Note there are 8 records eligible to be archived in the list.
Step 3: Capture current performance metrics
Determine your current table's performance by simply opening all records, then go to Transaction Logs and find the transaction where URL starts with "/incident_list.do?". Write down the performance numbers or take a screen shot. This is your starting performance that we can compare to later transactions to see performance improvements. Tip - have two tabs open; one for the list view, one for the transaction logs. Here are some links to other performance docs.
Check the client/server timings in the browser
Step 4: Create the archive rule
Note: Before turning on archiving, capture the current response times for the table (see Step 3). This will let you know how much archiving has actually helped performance!
Duplicate your tab so that you have the list view in one and the archive rule in another. In the new tab, navigate to Archive Rules and click on the existing incident table rule (there can only be one rule per table). Rename it to match what you conditions are. Set the condition to match the list view filter that you created earlier. Save the archive rule and confirm the record estimate matches the count in the list view on the other tab. Check the Active checkbox and Save. As soon as the rule becomes active, it will create an archive table and start archiving records the next time the Archive job runs. the default is every hour.
Step 5: Add a related record
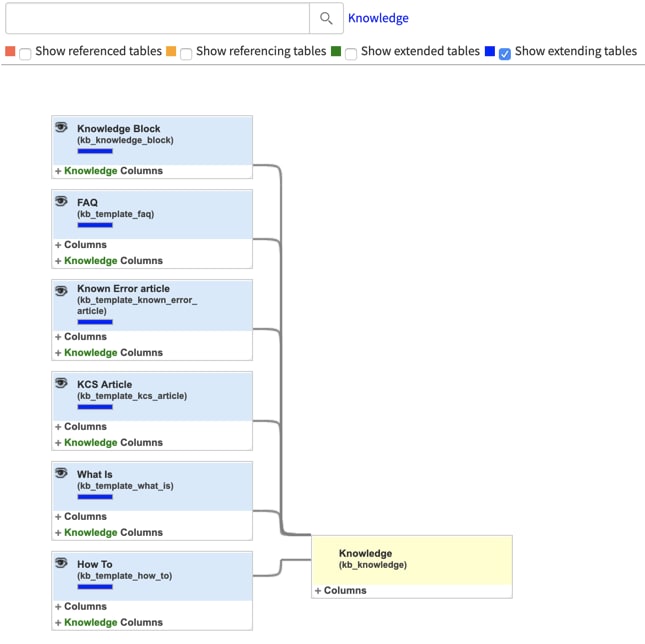
Adding related records required some investigation and thought. The Attachment, Audit, and Journal tables do not need to be archived. I'm going to switch over to the Knowledge table to use as an example in this step. I created an archive rule for knowledge (no related record yet), and when I activate it, I see several "ar_" tables being created.

Why did this happen? Looking at the table schema for kb_knowledge I can see these are all extending tables.

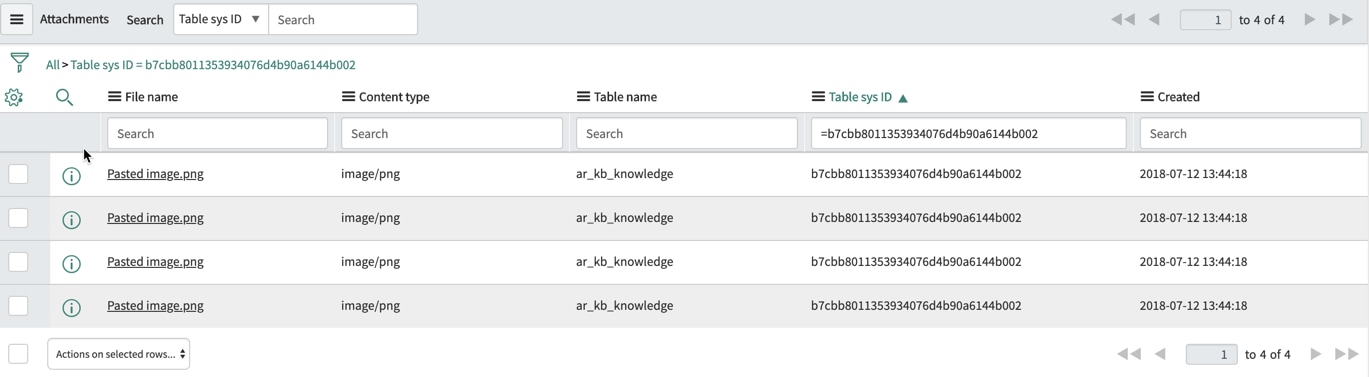
I also see that attachments were automatically handled and did not require me to create a related archive rule. When a record with attachments is archived, the the "Table name" and "Table sys_id" are changed in the attachment table to now point at the ar_kb_knowledge table. My example here shows the KB had four attachments. They all stay in the attachment table. When a record is restored, the pointers go back to the regular table This is automatic and is handled by the system, so no need to create a related archive rule for attachments. Nice!

But what about our related feedback records? I had two knowledge feedbacks that disappeared when I archived the article. They are orphaned when the knowledge article is archived.

I will create a rule to archive the feedback records as well.

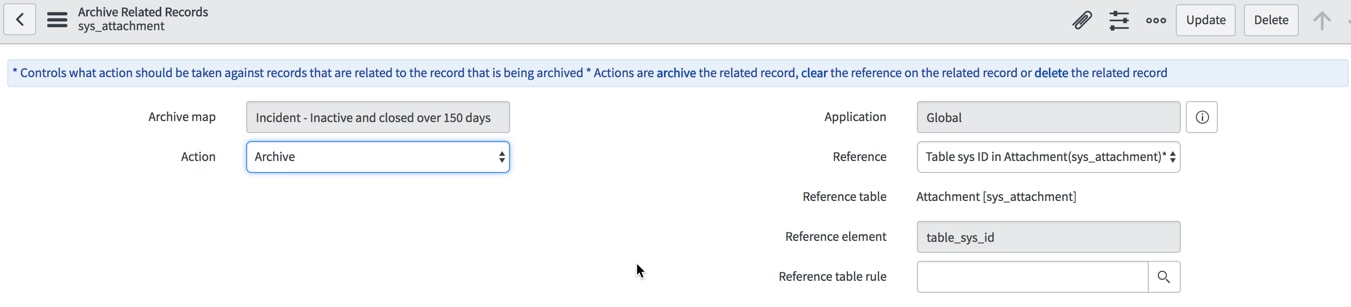
Select the correct action. I noticed once you save the record, the Action cannot be changed! When you save this record it will populate the reference table and element automatically.
On my archive rule I clicked Run Archive Now to kick off the archiving. I saw my knowledge article go to the archive table and also all the feedback records got archived to a newly created ar_kb_feedback. If I try and pull up the original knowledge article, I see this message:

The process for restoring is to go to each record and restore them individually. This is not something you are going to want to do very often. Once the Incident has been archived, it will not longer show up on related lists for Problem, for example.
Once a record has been restored, the archiving rule won't archive it again, however, the estimate count still includes it. The restore process only restores the current record. You must manually restore any related records you want to be active again.
In Summary, we covered:
Determining what to setup archive rules on (everything, but start small)
When to archive (set a starting time frame to do a small batch)
Create the archive rule (one per table) along with an Archive Related Record that is added to the rule.
Next Steps
You may want to publish a KB article outlining your ServiceNow data archiving strategy and policy. How do users request someone (usually the admins) to do some research on an archived record and possibly unarchive it? Create a Catalog Item for "Data Archiving Request" to allow users to create, update, delete?, and research data archives.
- 111,109 Views
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hello, thank you so much for this informative blog.
Could you tell me what happens to the audit and journal entries of each record that are being archived and then destroyed. Are these deleted as well? Or should we implement a separate process to delete audit entries.
Thanks,
Sherin
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
@Jay Freise , @Gaurav63 ,
We have a custom relationship created on interaction table wherein all records from task table gets listed based on opened by field of interaction table. When trying to add this custom related relationship in archive related records on archive rule created on interaction table. it lists only OOTB relationships in the reference field.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
I understand that I cannot write a Business rule against archived record. Is there a way to trigger a flow? My use case is every record that is written to a certain archive table should be triggered to be replicated in a data lake.
https://support.servicenow.com/kb?id=kb_article_view&sysparm_article=KB1639104
Thanks,
Harish
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
@Harish V No, there are simple no triggers on archive tables.
I do assume though that the sync to your data lake is not time critical - since it is archived data anyway. So why not create a scheduled flow - like once a day / week/ ... - which gets all newly added archived records and pushes them to your data lake?
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
@Daniel Draes, @Jay Freise , what really happens when I add "table sys id in attachment" for an sc_task archive rule?
Here is the behavior I noticed.
1. ar_sys_attahment is created with the same established pattern
2. sys_attachment_doc goes missing and I am unable to trace it with any SYS_IDs
3. on restore archive, the record on #2 does come back (but from where?)
Can you please help me here? we would like to move corresponding attachments to data lake as well.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi @Harish V , I did note in the article, "The Attachment, Audit, and Journal tables do not need to be archived." When I archived my test record, it went to the "ar_" table and the attachment is there. However, the attachment is still pointing to the sys_attachment table, so you can grab it from there in your flow.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hello @Jay Freise , Thank you for your response. However, I do not understand "the attachment is still pointing to the sys_attachment".
What I am looking for the sys_attachment_doc records for the sys_attachment record that was just archived using "Table sysid in sys_attachment". That seems to be missing.
I do see a corresponding record in ar_sys_attahment but the archive rule does not create a "ar_sys_attachment_doc" and the actual attachment files stored in the sys_attachment_doc goes to some other mystery spot. When I hit "restore" on the ar_sys_attachment record, the sys_attachment_doc comes back somehow.
Thanks,
Harish
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi @Harish V , I created a test table "Table to Archive" and one of the records has an attachment. I created an archive rule that targets a single record and when run, the record looks like this.

The attachment is still in sys_attachment, and sys_attachment_doc as seen here. But the record pointer has been updated to the archive table. The parent record pointer gets flipped back to the original table when un-archived.


There should not be an ar_sys_attachment or ar_sys_attachment_doc table. I only have the one table being archived.

I created an example flow that is triggered when a record is created on my "ar_x_snc_archiving_0_table_to_archive" table.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
From here you could copy the record to an external system using ServiceNow's Stream Connect for Apache Kafka, for example. Rather than the Move Attachment action, you could create a custom action to send the link to the attachment to an external system to be downloaded. Finally, if you want to reduce database footprint after sending data to an external data lake, add a destroy rule to remove the archived record right away.
Hope this gives you some ideas,
Jay
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hello @Jay Freise ,
Thank you so much for the response. Just to be clear, on your archive rule, you do not have any "archive related records" correct? and even if you did , you do not have anything for attachment tables.
Thanks,
Harish
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Correct!
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Thank you, Jay, for this article. It was very helpful for me to understand the Data Archiving process and how to use the archive rules correctly.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
How much time is records stored in ar_sys_email table before getting completely deleted from the instance?
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
@ey_dsingh This depends on your destroy rules. There is no automatic delete.
- « Previous
-
- 1
- 2
- Next »