

SimonMorris

ServiceNow Employee
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
09-08-2011
07:46 AM
As we revisit our core ITSM applications I've been diving back into the ITIL books, both version 3 and 2011.
We are all familiar with the ITIL "magic roundabout" - a visualisation that demonstrates how the 3 volumes - Service Operation, Transition and Design - rotate around Service Strategy with an outer crust of Continual Service Improvement keeping it all together.
It's a great data visualisation and emphasises the recursive nature of ITSM, and that there isn't really an end to an implementation (Great news for all of those ITSM consultants eh?)
Thinking about the relationships between the core processes - and thinking in terms of workflow rather than high level ITIL volumes, I ended up with a new process flow and a realisation that was new to me.
Maybe Incident Management and Change Management should never meet.
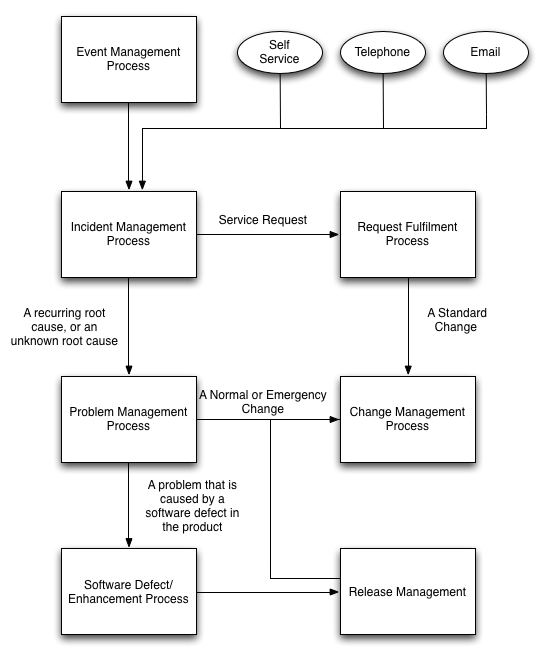
The process flow below shows how work moves between different processes - and it shows why generating a Request For Change (or Change Record) directly from an Incident might be a bad idea.
Firstly a quick confirmation of the characteristics of each process:
Incident Management
- A break in service.
- An outage, failure.
- A degradation in service.
- Aim is to restore service.
- Takes output from Knowledge Management.
- May provide input into the Request Fulfilment process.
- May provide input into the Problem Management process.
Request Fulfilment
- A service request.
- New Hardware, Software, access or feature.
- Joiners and Leavers.
- Request for Information.
- Feedback.
- Complaint.
- May provide input into the Change Management via a Standard Change.
Problem Management
- Known Errors and Workarounds.
- Root Cause Analysis.
- Takes input from Incident Management.
- May provide input into the Change Management process via Emergency and Normal Changes.
- Is a part of Knowledge Management by providing known errors.
Change Management
- Take output from Request Fulfilment via a Standard Change.
- Takes output from Problem Management via a Normal or Emergency Change.
- In advanced implementations can take automated output from Configuration Management.
So here is my process flow.

At the top it shows triggers inputting to the Incident Management process - An Event from a monitoring system, an IT engineer or a user via Telephone, Email or Self Service.
In the Incident Management process we can determine if we are looking at a Service Request (divert right into the Request Fulfilment process) or an Incident. Is something broken or not?
If this is a Service Request we are probably looking at something that is requested fairly routinely. A new DNS record, a new Virtual Server - maybe even a new instance of ServiceNow!
This can provide input into the Change Management process as a Standard Change with a pre-defined plan.
Let's rewind to the point where we decided the type of incident. If we are looking at something that is broken we can fix it straight away if it is minor.
If it is more serious - perhaps we've seen this a few times before, or perhaps we don't understand why this incident happened. We might want to raise a Request For Change to fix it.
Here is the realisation I came to - You shouldn't raise a Change straight from an Incident.
By doing that you skip past the Problem Management process, and you lose a lot of value.
In Problem Management we should be associating one or multiple Incident records to a Problem so that we can document the Known Error - We know that server X exhibits this problem - and hopefully a Workaround.
If we skip from Incident directly into Change Management we lose a valuable piece of information which may lead to rework if the same root cause generates more Incidents.
Imagine that you are an Server engineer. You get the first instance of a issue that affects users, maybe the server has a hardware fault and needs new memory. If you jump from Incident to Change there isn't a good place for other Incident analysts to check for issues. Another Server engineer might get a second instance of the issue and duplicate your effort.
If you don't log the Known Error and a Workaround you might expect other Support analysts to experience the same problem.
From the Problem Management process we can then move into Change Management via a Normal or Emergency Change depending on the urgency.
The whole point of the diagram I wrote was to explain how Defect management should work - but this blog post is probably long enough!
Lastly I realise that this is a very Utopian view, and that organisations might not have a strong Problem Management process - but hopefully the diagram explains how that might help.
- 15,035 Views
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.


{kind=link}
{kind=link}