- Post History
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
on 07-09-2021 09:19 AM
Introduction
One of the first use cases I set up in Health Log Analytics (“HLA”) was to ingest Linux system logs (e.g. “/var/log/*”) using Filebeat. As it happens, one of the more verbose services writing to /var/log/messages on a default CentOS server build is Filebeat itself. On my Quebec ServiceNow instance, the out-of-box (“OOB”) handling of the Filebeat syslog messages was to group them under a default “LinuxOS” component and source type. This treatment did not pull out the severity of the messages, which limited the AIOps engine’s ability to elicit useful insights. This article shows an example of how to further refine log entries from Filebeat in order to empower AIOps.
NOTE: This article assumes you have already provisioned your instance with HLA and all HLA-related services and facilities are functioning and healthy.
Data Input
I begin by following the guided setup to establish my Data Input, named “hallam-filebeat-1” (https://docs.servicenow.com/bundle/quebec-it-operations-management/page/product/health-log-analytics...). I choose the “Linux using Filebeat” type, with a path of “/var/log/*” and leave the “Component” field empty so it will auto-populate based on the built-in HLA file name and content parsing capabilities.

Data Input Mapping
The Data Input Mapping record for my Data Input is where I add JavaScript code to recognize the unique format of a Filebeat syslog record and set the Component and Source type values accordingly.
First, I load an example log entry, either via the samples HLA maintains automatically or manually copy/pasting a representative entry into the “Test a manual sample” field. Upon examining the sample, I see that the facility or service name appears in the fifth whitespace-separated field of the message payload. Based on that, I add JavaScript code to the “Custom JS function” field for the Data Input Mapping, for example:
function map(sample, metadata) {
var app = null,
cpt = null,
src = null;
// parse to json
sampleJson = JSON.parse(sample);
// extract value from "message" key
msg = sampleJson['message'];
// split the message on whitespace
msgList = msg.split(/\s+/);
// service/facility is fifth whitespace-separated field
if (msgList[4]) {
// remove any colons
evalCpt = msgList[4].replace(":", "");
// if the component matches one of our special cases, override the component and source type
if (evalCpt == "filebeat") {
cpt = evalCpt;
src = evalCpt;
}
}
return {
'applicationService': app,
'component': cpt,
'sourceType': src,
};
}
When I test my code, using the “Test” (for automatic samples) or “Go” (for manual samples) button, I can see that the function identifies the presence of “filebeat” in the sample and sets the Component and Source type to “filebeat” accordingly.

The Source type value is key because it is what allows me to tell HLA about the format of the Filebeat log entries. HLA will automatically create the “filebeat” Source type the first time it receives a live sample containing a Filebeat log entry.
Since I’m happy with the outcome of my test run, I click “Publish” to activate my new function and commit any other changes to the mapping.
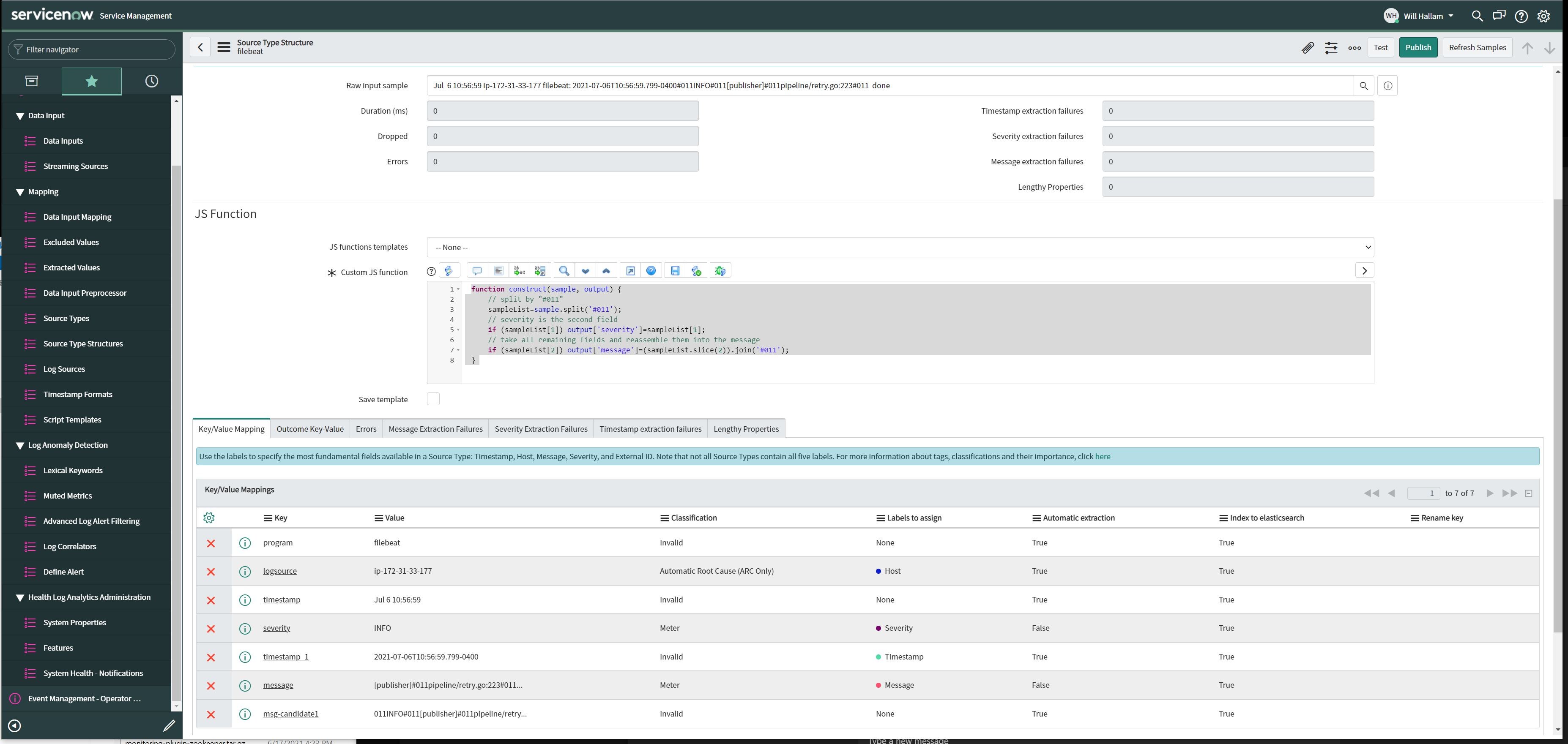
Source Type Structure
The Source Type Structure for “filebeat” appears automatically in my instance once a Filebeat log entry is received from any of my log sources. I can see it by navigating to Health Log Analytics->Mapping->Source Type Structures and searching for “filebeat”. Within this record is where I call out specific pieces of a sample message and tag them with the labels “Timestamp”, “Host”, “Message”, “Severity”, or “External ID”. This is the final piece which must be in place for the HLA machine learning to identify anomalous behavior in the service.
When opening the “filebeat” Source Type Structure for the first time, all the entries in the “Key/Value Mapping” related list will have a Classification of “Invalid” and a Label of “None”. Some of the initial entries can be used as-is, such as “logsource” and “timestamp” which can be labeled as “Host” and “Timestamp”, respectively. To extract the provided severity keyword, however, some more custom JavaScript is required. The following example will break out the severity from the larger message string:
function construct(sample, output) {
// split by "#011"
sampleList=sample.split('#011');
// severity is the second field
if (sampleList[1]) output['severity']=sampleList[1];
// take all remaining fields and reassemble them into the message
if (sampleList[2]) output['message']=(sampleList.slice(2)).join('#011');
}
Now that I’ve separated out the severity and message, I can label them accordingly. HLA automatically applies specific classifications to these four key values. By clicking “Publish” I commit these updates and subsequent Filebeat logs will be parsed into “Timestamp”, “Severity”, “Host” and “Message” components.

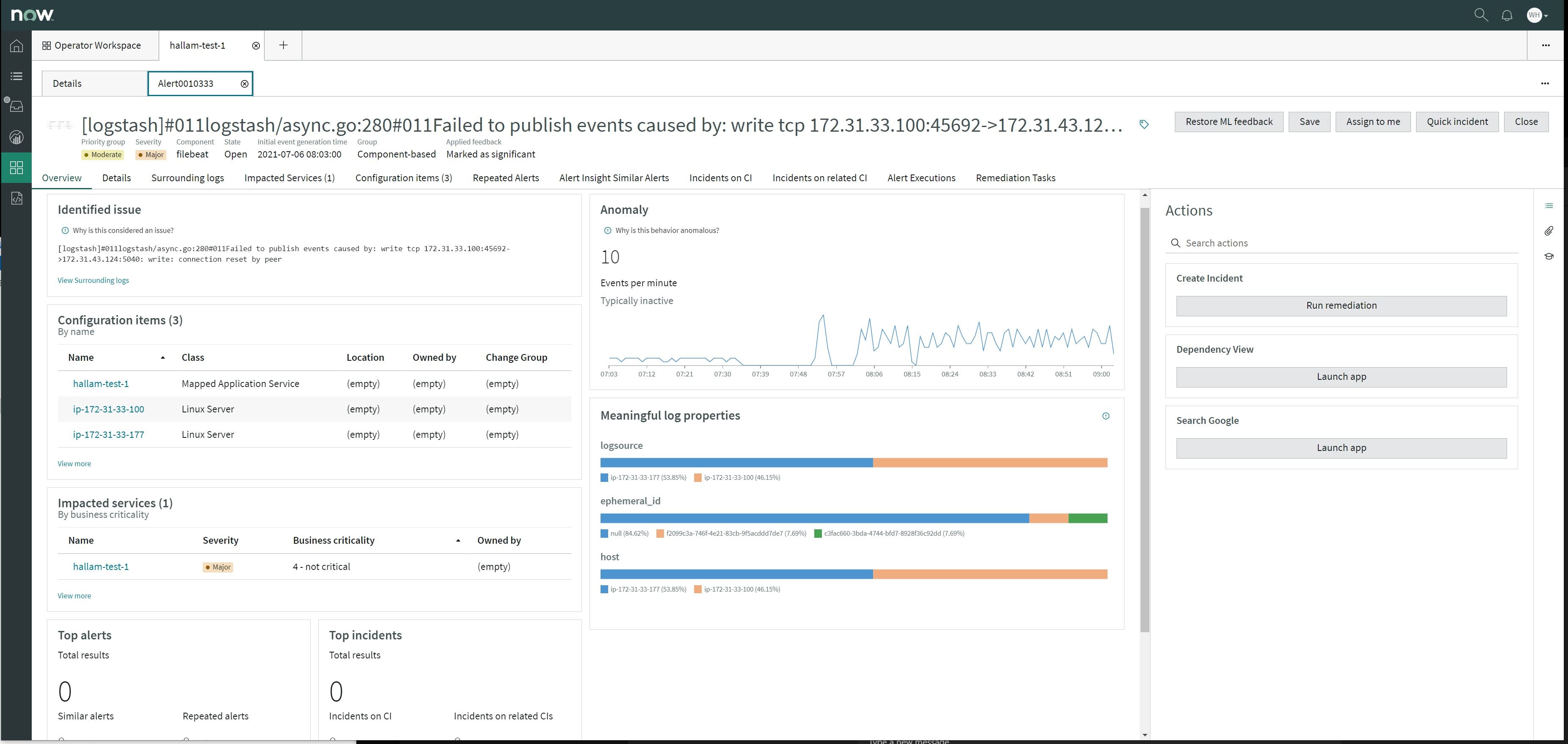
With that final piece configured, HLA can monitor the Filebeat service on any of my log sources and detect anomalous behaviors, displaying findings in the Operator Workspace.

- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Brilliantly done,
I have a few alternative suggestions on how this can be fixed, that might hopefully be a little easier and require less expertise.
- The actual challenge here in the first place is having "filebeat" logs mix-up with all the syslog messages under /var/log/messages, which HLA by default refers to as one pile of Linux System logs and doesn't care too much for the specific programs in it, that's why they get auto-classified to one Component/Source-type as "LinuxOS" (which BTW, can be altered and/or defined under the "Extracted Values" table, under Mapping).
One way to fix this would be to leverage Filebeat's configuration options in filebeat.yml to Configure logging to a dedicated file, for example: /var/log/filebeat.log (which would then continue to work for the input path you defined as it's under the same directory). Notice a working example of such configuration can be found at the top of the page in the link above. Once it's separated in the first place, you won't need to write any manual mapping script, and "filebeat" will automatically become the name for both the Component and the Source-Type. - Next up, an issue you were facing that denied the auto-extraction in the source-type from performing well was the problem of filebeat's logging encoding - where instead of getting actual tabs, you saw there unicode representation of "#011". The best way to fix it on HLA is in the Data-Input Preprocessor, where you can modify the logs before they undergo any processing. That way, we'll replace the "#011" phrases with actual tabs (\t) and then you'll see how the auto-extraction is suddenly working fine. Use the following script on the Data-Input PreProcessor:
function process(sample, metadata) { var modi = null; if (sample.indexOf('#011') >= 0) { modi = sample.replace(/#011/g,'\\t'); } return { 'modifiedInput': modi, // manipulated raw data 'splitEvents': null // an array of strings, treated as separate events }; }and then, for the source-type to restart learning based on the new modified samples, make sure to delete the source-type record itself and then it will get recreated properly.
See what it looked like after the change:
(notice the "Auto extraction" column on all fields is set to True, meaning no script was written!)


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Step 2 is recommended no matter what! As for step 1 however, if you wish to make do with filebeat being a part of /var/log/messages and not separating it - in addition to making it work with a Mapping script like you did, there's a slightly more complicated possibility that requires pretty high expertise with HLA - but could make this work in a more automated fashion. It is called "Recursive Header Detection", and it would allow you to auto extract the inner syslog-header that the syslog programs are wrapped by, as well as the filebeat logs... if you're interested in exploring that option, please reach out to me directly for now, until we publish some more formal KB article about it.
Thanks,
Netser.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi,
Were you able to get HLA installed on your PDI?
I don't find any way to actually enable that plugin on my PDI.