- Post History
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
on 11-04-2020 05:55 AM
Predictive Intelligence clustering is useful in identifying patterns in your data that you may not be able to see with analytics or reporting. Clustering works by grouping data points together that have similar features. Those datapoints can be knowledge articles, change requests, cases, or incidents. Clustering helps us identify automation opportunities and subscribe a value to automate those opportunities as seen in the Luca Morlupi’s Clustering Recommendations dashboard below (see fig1).

When you create a new clustering solution definition the default algorithm is K-means. In Paris, when you click the Advanced Solution Settings tab of your clustering solutions definition you will see a number of cluster parameters and different clustering algorithms such as HDBSCAN and DBSCAN. DBSCAN stands for Density-Based Spatial Clustering of Applications with Noise. DBSCAN differs from K-means in that you do not need to define the clusters K. The number of K clusters influences the patterns that you may see. DBSCAN also works well for datasets that are dense and not convex. There are a lot of great in-depth articles that you can google to read up on how the algorithm works.
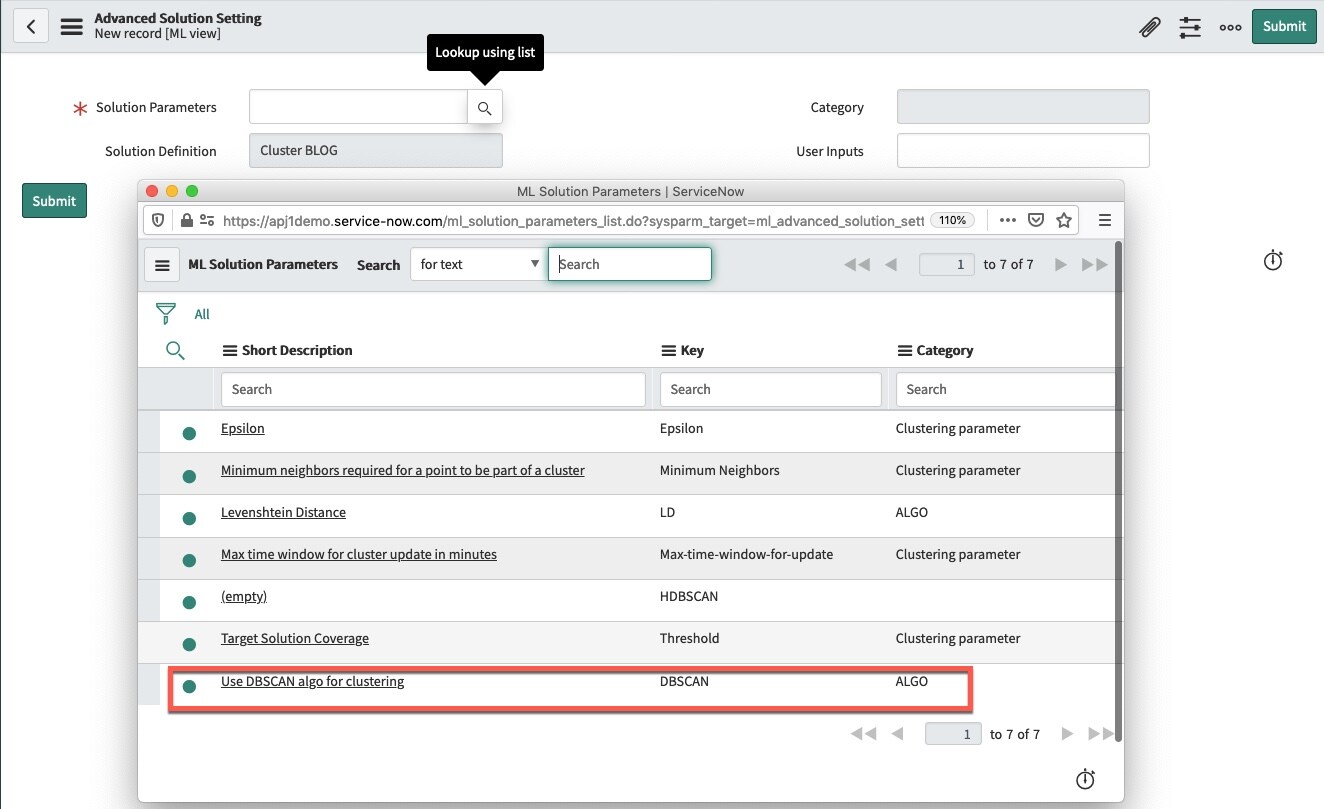
The purpose of this article is to show you a practical application of DBSCAN. Although DBSCAN was introduced in Orlando, by default it’s only visible in the Paris release. By clicking on DBSCAN you can switch from the default K-means clustering algorithm to the DBSCAN algorithm (see fig2). In order to enable DBSCAN in the Orlando release, you need to open a HI Ticket and ask them to reference KB0829924 to enable DBSCAN on your instance.

In the example below (fig3), a K-means cluster was created on the short_description field of the incident table. This diagram is using the new Paris cluster treemap plot to show cluster concept groupings of incident short_descriptions based on similar features. Cluster concepts are the top terms most common in the cluster.

Let’s focus on clusters 1 & 2 in (fig3). Cluster 1, indicates the incidents in this cluster have the word combinations “network access error poor time” in common. We could interpret Cluster 1 to mean we have an issue with poor network access times. But we’re guessing on the word combinations. Cluster 2 says “issue printer token rsa print” as the common terms for this group of incidents. We could also postulate that “printer issues” and “rsa token issues” are potential automation opportunities.
Let's experiment with a different clustering algorithm – specifically DBSCAN, to see if we can get tighter clusters. Below (fig4) is the cluster treemap plot for the same short_description incident data, the only difference is that we have used DBSCAN as our clustering algorithm.

Notice how the clusters are much clearer. We can clearly see the following:
• Network access error
• Poor time response from network
• Token RSA issue
• Printer Issue and print issue
• Request plan fidelity account termination
• Zoom fix and Zoom Help
In this case the DBSCAN allows me to clearly see the automation opportunity. I no longer have to decipher what “network access error poor time” means from the K-means cluster. Using DBSCAN it’s clear that there is pattern of incidents for “network access error” and “poor time response from network.”
If you’re not familiar with setting up clustering in Predictive Intelligence we have you covered. Go to https://nowlearning.service-now.com and search for the below K20 lab. Section 1.1.5 has a video and lab on how to configure clustering (fig5).

Now take everything that I’ve explained with a grain of salt, there is no one clustering algorithm that works well with all data. K-means may be better at showing clusters for one set of customer instance data while DBSCAN may work well for other customer instance data. My advice, have fun and experiment with all of the advanced setting algorithm options! We’ve made it really easy to put these powerful machine learning algorithms to work without having to be a data scientist.
- 8,998 Views
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Thanks Lener ,Great Information !
I have one question , I need to use affected service as input field for the Clustering model and I use affected_service.name but I get an error that it doesn`t have text values , I used DBSCAN but this not help , can you tell me a hint or a way to handle it ?
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Kusai, couple questions (1) this error occurs when training? (2) what is the data type for your affected_service.name column? (3) did you try adding a condition to your clustering solution definition where affected_service.name is Not Empty. -lener
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Yes the error occurs when training the solution , the data type should be a text ( String data type ) , and yes I added the condition affected_service.name is Not Empty , and I still have the same error .

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}