- Post History
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
01-04-2022 08:21 AM - edited 10-10-2024 05:44 AM
Clustering is a popular unsupervised machine learning algorithm that can help us find patterns in our data that aren’t obvious when using traditional analytics or reporting. Clustering allows us to unlock insights stored in the free form text fields such as short description or description of our incidents or requests.
Clustering moves beyond simple Word Clouds by mining the text and grouping together records using unsupervised machine learning algorithms such as K-means, DBScan, or HDBScan.
Below are a few common ITSM/CSM/HR use cases for clustering:
- Reduce the number of incidents/cases/requests by identifying potential areas for automation
- Identifying gaps in your Knowledge Base
- Understand the quality of your category or subcategories
- Find commonalities in failed changes in your change requests (ITSM)
- Find trending topics for product issues (CSM)
Using Predictive Intelligence (PI) clustering means you do not have to move data off the platform. PI handles the data pre-processing and leverages our GPU architecture all without needing specialized data science skills. Cluster model creation and training is accomplished with three simple steps:
- Define the Word Corpus
- Select the table and fields to cluster
- Hit submit and train
Predictive Intelligence supports K-means as the default clustering algorithm. You can switch to DBScan and HDBScan by going through the Predictive Intelligence > Clustering > Solution Definitions > New > Advanced Settings of the solution definition (see fig1).

I won’t get into the details of how the algorithms work as you can Google each of the algorithms and find a plethora of information on how they work and the benefits of each one. Many of the articles will discuss that you should select an algorithm based on the shape of the data; to do that data scientist will plot the PCA or t-SNE output to see the shape of the data. Unfortunately, we mere platform users can’t do that in Predictive Intelligence - so that means you will have to experiment with each of the algorithms to see which one will give you the desired cluster results. Because clustering on 100k-300k records can often take 30minutes to an hour my recommendation when experimenting with different algorithms is to start with smaller cluster sizes of 30-50k records and see which algorithm appears to be producing the best results.
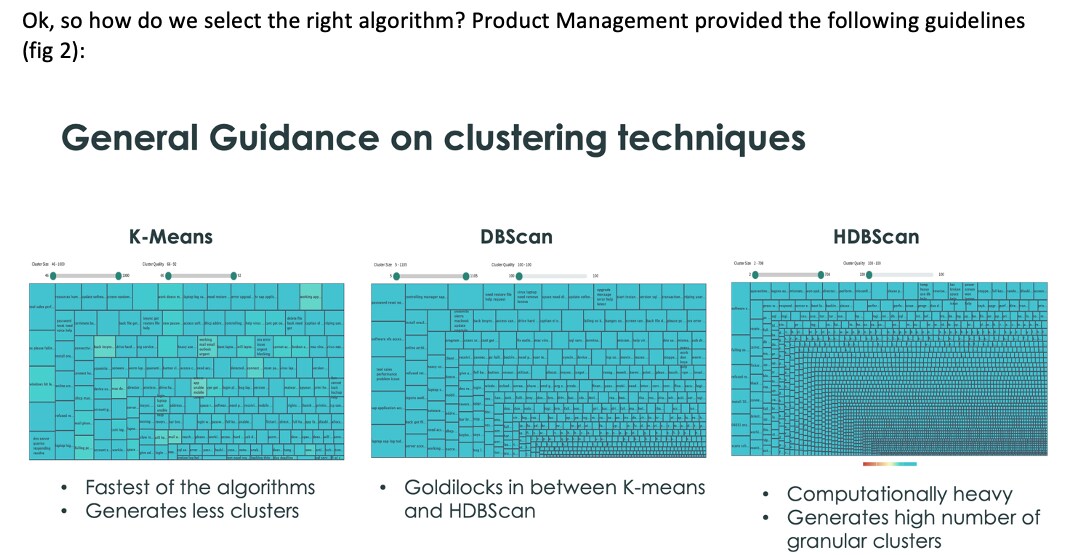
Selecting the correct clustering algorithm
Ok, so how do we select the right algorithm? Product Management provided the following guidelines (fig 2):

(fig2 – general cluster guidance)
Let’s take a hypothetical situation to see the differences between the different clustering approaches, say I am an analyst and I have been told by the ServiceDesk they would like to understand the type of issues users have with SAP. I will run clustering to identify potential automation opportunities for SAP issues and evaluate which clustering approach is most effective.
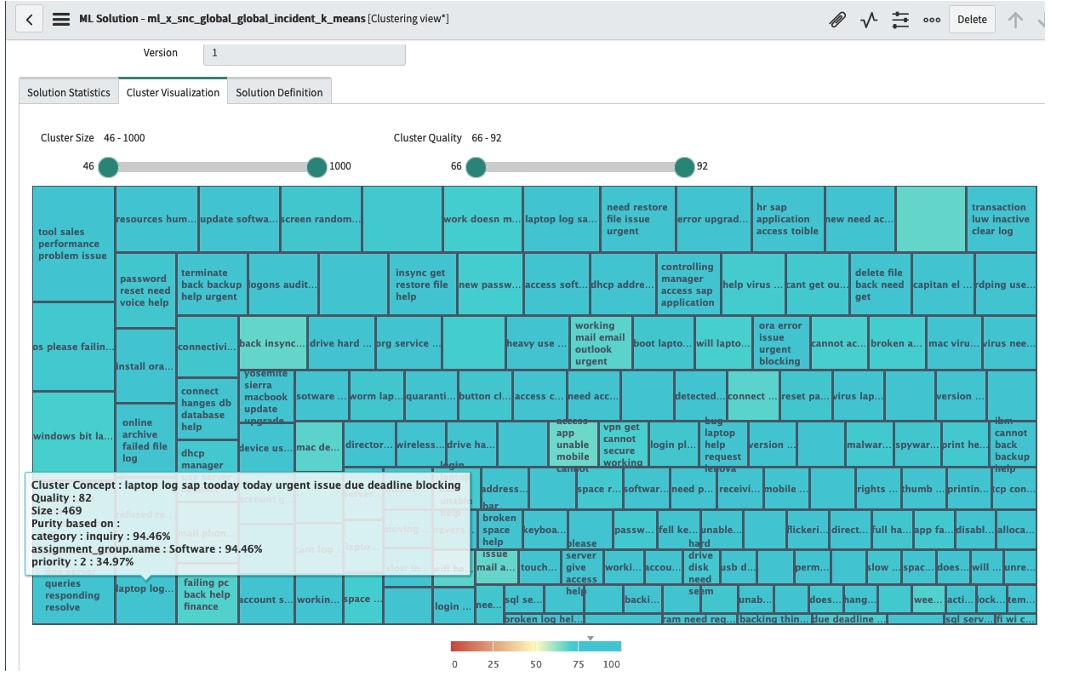
I start with a K-means cluster against my incident data and hover over the largest clusters (fig3). I see an SAP cluster that catches my interest. The cluster concept represents the top 10 words each record has in common, and I see “laptop – log – sap – issue”, there are 469 records in this cluster (fig3).

(fig3 K-means)
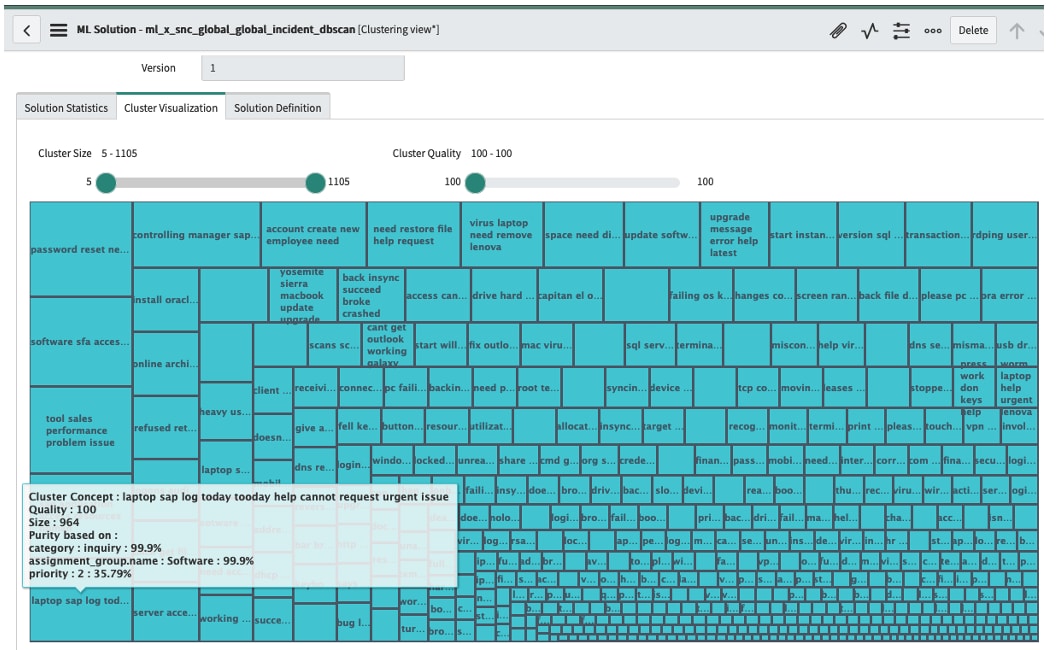
Let’s now take a look at the same data run through DBScan (fig4). Notice the DBScan algorithm has found a cluster of 964 records with the cluster concept “laptop – sap – issue” as top terms. DBScan has identified almost double the number of records that K-means identified.

(fig4 DBScan)
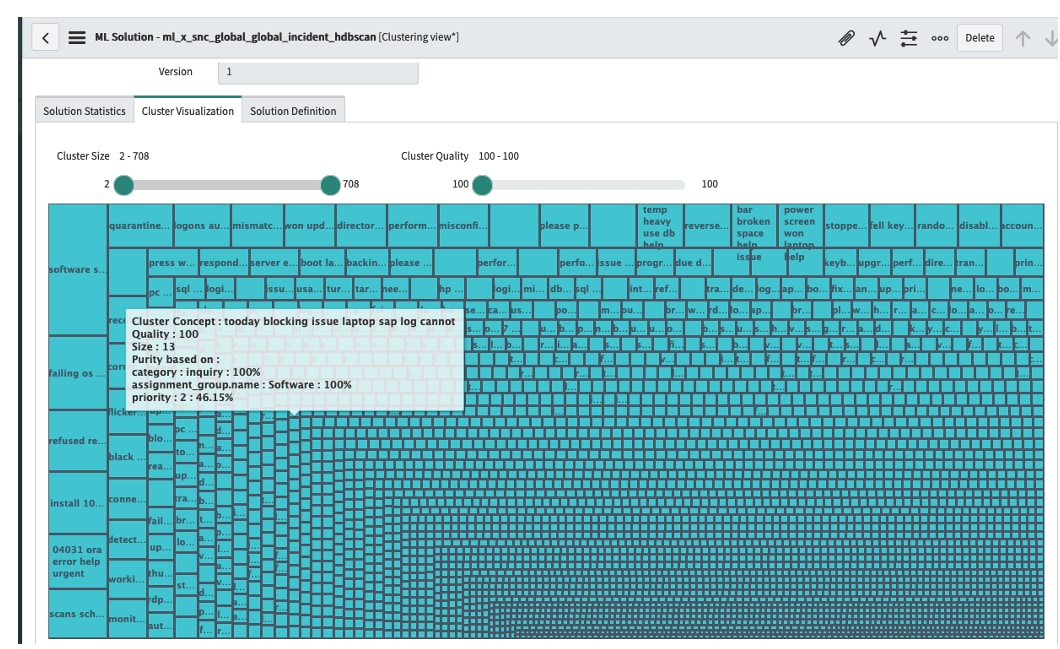
Finally, let’s look at the same data through HDBScan; notice the number of clusters is far greater than K-means or DBScan. HDBScan is computationally heavy and returns more granular clusters than both algorithms, this is useful when we need to isolate very specific patterns in our data. Hovering around the data I see many smaller clusters with cluster concepts of “sap laptop”. Examine the two clusters below. One cluster (fig5) says that I have an urgent SAP laptop issue today. Another cluster breaks it down even further into SAP blocking issue on laptop today (fig6).

(fig 5 – HDBScan – SAP urgent issues)

(fig6 – HDBscan – SAP Blocking issues)
In summary as an analyst the DBScan algorithm has identified a larger volume of SAP Laptop Issues, while HDBScan allows me to hone in on specific SAP laptop issues users are having. K-means is the fastest of the algorithms and may be good enough depending on your data. Using different clustering approaches allows me to look at the data in different ways to uncover automation opportunities.
For reference:
For those with data scientists in your organization, you have the ability to further tweak the clustering performance using advanced parameters such as Levenshtein distance, minimum neighbor, Epsilon, and more. KB1228391 provides guidance on some of these parameters, however if you are changing make sure to consult your data scientist.

- 10,146 Views
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
For reference

- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
for reference

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Labeled data means we have the answers (aka labels) when we build the ML model. For example when we use classification to predict the assignment group and our input is the short description our historical data will have an assignment group for each short description; meaning it is labeled. We use this to teach the model to recognize which short description goes to which assignment group.
Unlabeled Data means we don’t have the answers when we build the ML model. Clustering excels with unlabeled data. In this case the the labels are the clusters. When we feed our incident data into the clustering algorithm we don’t know what cluster each incident belongs to, it’s unlabeled. Clustering determines which incidents should be grouped together based on the inputs used.