- Post History
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
05-02-2022 04:48 AM - edited 12-23-2024 02:37 AM
Intro
ServiceNow Studio provides an Integrated Development Environment (IDE) interface for application developers to work on custom applications in one centralised location.
It offers a simple way to create, review, and update application files from a tabbed environment and enables application developers to integrate with a Git Source Control Repository. This functionality allows to saving and management of multiple versions of an application from a non-production instance.
Source Control enables all application developers on a non-production instance to:
- Import applications from a Git repository.
- Pull and apply remote changes from a Git repository.
- Commit all local changes on the instance to a Git repository.
- Create tags to link to a given version of an application permanently.
- Create branches to maintain multiple versions of an application simultaneously.
Note that developing a custom application requires a different strategy than the typical approach followed to implement new requirements in the global scope. This strategy applies to custom scoped applications, and ServiceNow official scoped applications (e.g. HR, CSM).
This article will present a repeatable method to develop and deploy a custom application leveraging a Git repository. A simple development use case will highlight the main differences between the classic approach used in ServiceNow projects and the importance of technical governance tailored around the implementation process.
DISCLAIMER
The approach will work well with small teams and must be considered a starting point in analysing a possible solution to a more complex problem. Each organisation is different, and each development team has its strengths and weaknesses. I expect each one of you (developer, developer lead, or architect) to adapt the method according to your real needs and necessities and not consider it a silver bullet for all your troubles.
Development Flow
Update Sets
ServiceNow supports different ways of deploying code from one environment to another.' Update sets are usually the preferred method when working in the global scope (e.g., ITSM implementation).
An 'update set' is a group of configuration changes that can be moved from one instance to another. This feature allows administrators to group a series of changes into a named set and then move them as a unit to other systems for testing or deployment.
An update set is an XML file that contains:
- A collection of record details that uniquely identify the update set.
- A list of configuration changes.
- A state that determines whether another instance can retrieve and apply configuration changes.
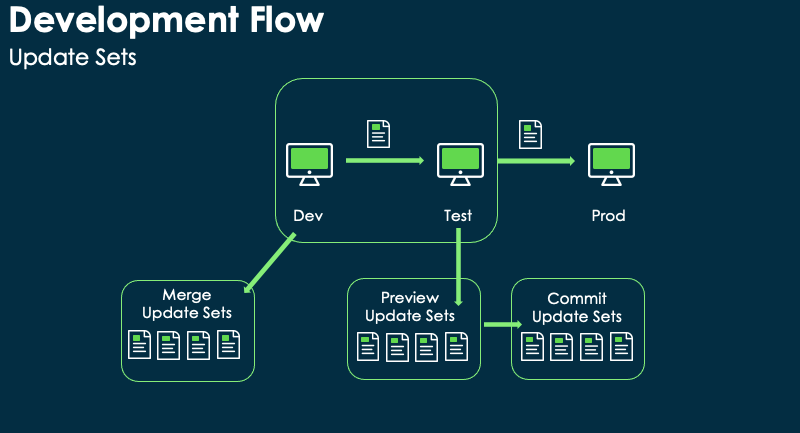
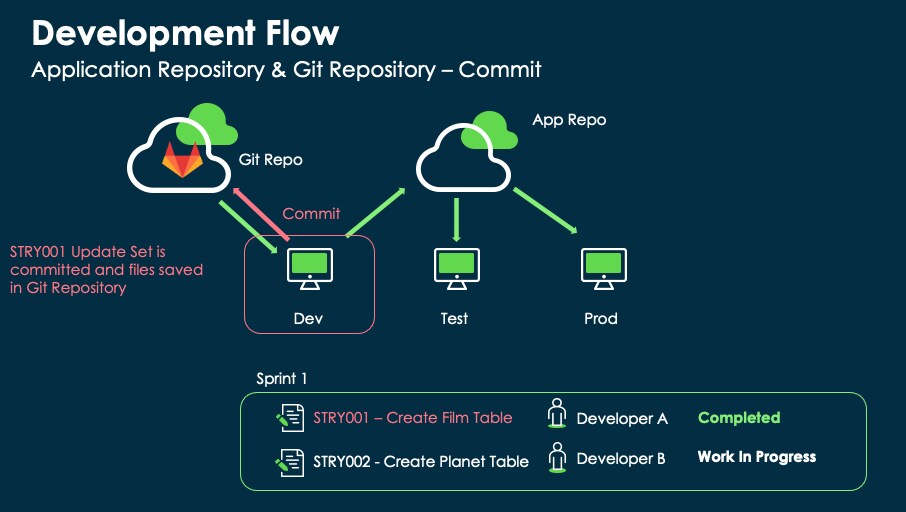
Update sets track changes to applications and system platform features. This allows developers to create new functionality on a non-production instance and promote the changes to another instance, as shown in the following image.

It is also possible to create a batch of update sets. This enables the developer to group update sets pre-viewed and committed in bulk. Dealing with multiple update sets can lead to problems, including committing update sets in the wrong order or inadvertently leaving out one or more sets. These problems can be avoided by grouping completed update sets into a batch.
The system organises update set batches into a hierarchy. One update set can act as the parent for multiple child update sets. A given update set can be both a child and parent, enabling multiple-level hierarchies. One update set at the top level of the hierarchy acts as the base update set.
Application Repository
Things are significantly different for developers working on a scoped application. They can use update sets, but it is a little counterproductive and time-consuming. After developing and peer-testing a custom application, they can make it available to company instances by publishing it to the ServiceNow application repository.
The ServiceNow application repository is a central repository for all scoped applications published by all ServiceNow customers. It allows ServiceNow customers to upload and distribute applications between their instances. When someone accesses the application repository, they can see and manage only the applications published by your organisation. Developers cannot see or manage applications that other organisations publish.
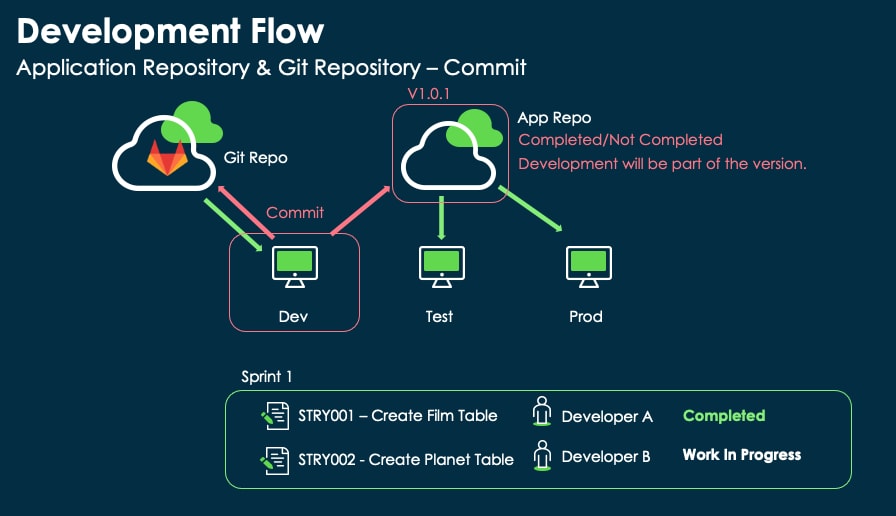
The following image shows that the content developed in DEV is published as a new version in the repo and can be deployed in any environment other than DEV.
It is impossible to publish to the application repository from different environments other than DEV.

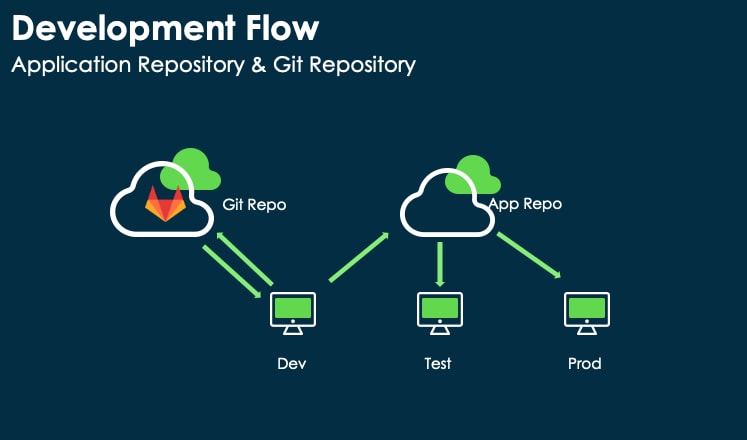
As already pointed out in the introduction, developers can also use a Git Repo to back up their work while implementing their applications. We will use this second scenario to support the use case in this article.
Introducing the use case. One App, Two Developers and One Initial Sprint.
Now imagine that we need to deliver a new project. The initial evaluation has been already executed, and it seems the only way to reach the organisation's desired outcome is through a custom app.
After a few internal workshops, we have a functional document explaining the process, a diagram showing the actual data model required for the new application and a list of requirements long enough to cover several rounds of development.
Following the usual Agile-oriented methodology suggested by ServiceNow, the requirements are transformed into stories. Their acceptance criteria are fine-tuned and optimised to support the delivery of the actual project. Points are provided to describe the complexity of the story's implementation.
The story backlog is ready, so we can start planning our sprints.
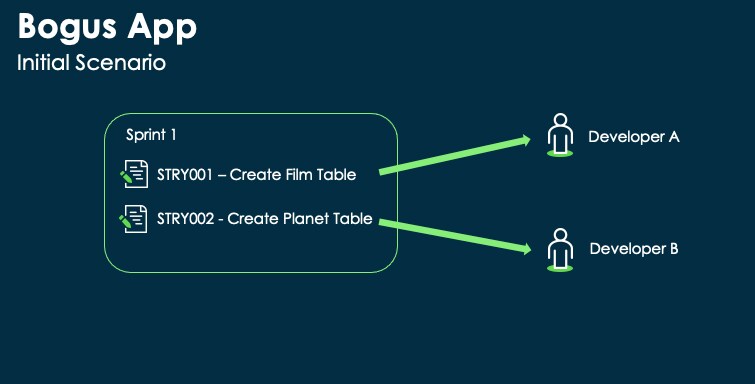
For this example, we will simplify the situation, creating a very basic initial sprint formed by only two stories. A team of two developers will work on the sprint stories.
Here is the distribution of the requirements

For simplicity, the stories are intended to be completely independent of each other; logically speaking, they are just a pretext to understand how to handle a custom app project using a Git repository.
One Branch = One Sprint.
A new developer instance has been requested to be ready for development. Two new users, 'Developer A' and 'Developer B', have been created, both with 'admin' credentials.
A new empty custom app called 'Bogus' has been created and linked with a project of the same name in an existing Git Repository.


To allow the developers to work on the sprint and the stories, we must set a common strategy for them. They will work on the same sprint, and we need to find a common development object between Git and the Custom Application. One thing that can help us here is the concept of the branch.
A branch is a unique set of code changes with a unique name. Each repository can have one or more branches. The main branch — the one where all changes eventually get merged back into - is called main (well, someone still calls it master but to cut a long story short, Git Repos renamed it).
Each custom application in ServiceNow can be set on one unique branch at a time, and if we think about the sprint as our unique set of code changes, the next step seems obvious.
|
We can create a new branch for each sprint and select it. The new branch will track all the work to implement the two stories. |
It is also essential to use a consistent naming convention internally, which the development team must follow every time it sets and executes a new sprint.
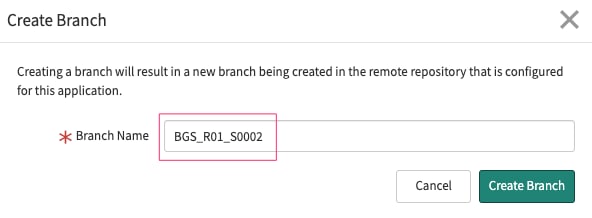
In our example, we will use
- three letters as project name acronyms [BGS]
- the letter R followed by two digits for the release [R01]
- the letter S followed by four numbers for the sprint. [S0001]

The new branch is created and selected as a common component for the developers.

Stories and Update Sets
Now that everything is set, Developers A and B are almost ready to go. In fact, before working on their stories, they set one update set each. I know that seems nonsense because of what was described in the introduction, but this extra step will make a big difference.
Logged as Developer A, after opening the 'Bogus' app in ServiceNow Studio, if we navigate back to the main UI, we can notice that the system automatically sets a default update set for the application.

|
The update set is consistently named after the actual user logged working on the application.
|
This means that 'Developer B' will have something similar, showing the correct user name.
If we go back to Developer A, the user can navigate to the list of available update sets and create a new one to cover the story previously assigned.
This example follows a fixed naming convention every time the developer implements a new story.
We will use the following convention.
- three letters as project name acronyms [BGS]
- the letter R followed by two digits for the release [R01]
- the letter S followed by four numbers for the sprint. [S0001]
- the acronym STRY followed by the story number for the story [STRY001]

The update sets are selected as current for each developer.

Developer B will execute the same operations. Simply, Developer B will work on the update set named after STRY002.
Commit and Stashing
Both developers will work on their requirements. In this case, we have just one story, but this is unimportant. However, it's essential to understand what the developers must do when they reach the end of the sprint, and we need to publish the application to the test environment.
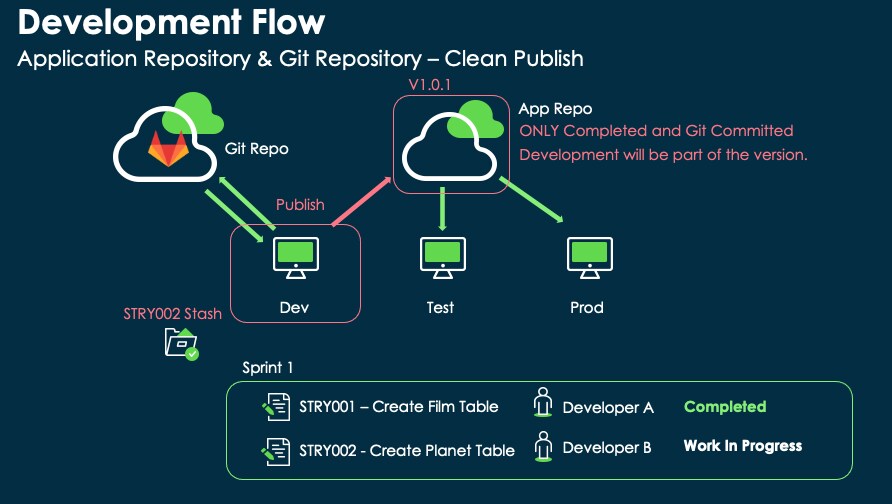
There is a small problem. Suppose we reach the end of the sprint, Developer A has completed his assignment, and the requirement is implemented, peer-tested, and ready to deploy.
However, Developer B did not complete his assignment, or for some reason, there was a delay in deploying what had been developed.
If we 'Publish' directly the app as it is, everything that has been developed will reach the application repository and the Git repository, bringing unwanted code and unfinished functionalities.

We need to use another piece of functionality available in Studio; we need to stash.
Stashing is the act of storing something in a safe place. In source control, stashing saves local changes for an application to be applied later. The local changes do not need to be committed to the remote repository. Stashing a change removes the change from the current application and saves it for a developer to apply later or delete.
You can use stashes to:
- Save uncommitted application changes to reapply later
- Save application changes to apply to other branches
- Remove undesired changes from a branch completely
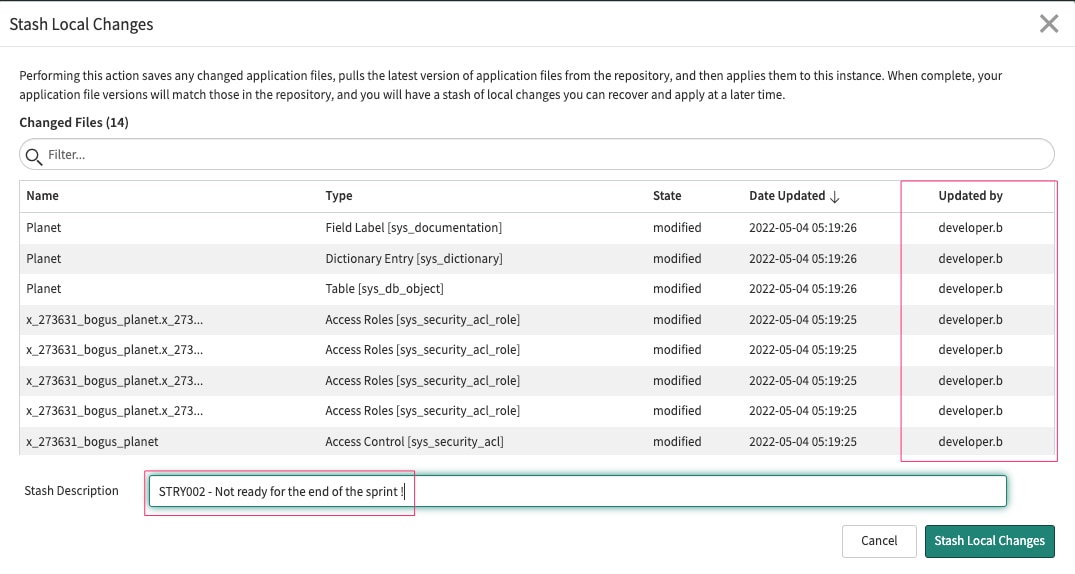
When we try to stash, the system will show all the files not yet committed and created by both Developer A and Developer B.

We want to stash only the work that has not been completed. In our example, these are the files created by Developer B.
If we try to 'Commit' the changes over the Git Repository, the system will show this.






Get Ready for the next sprint.
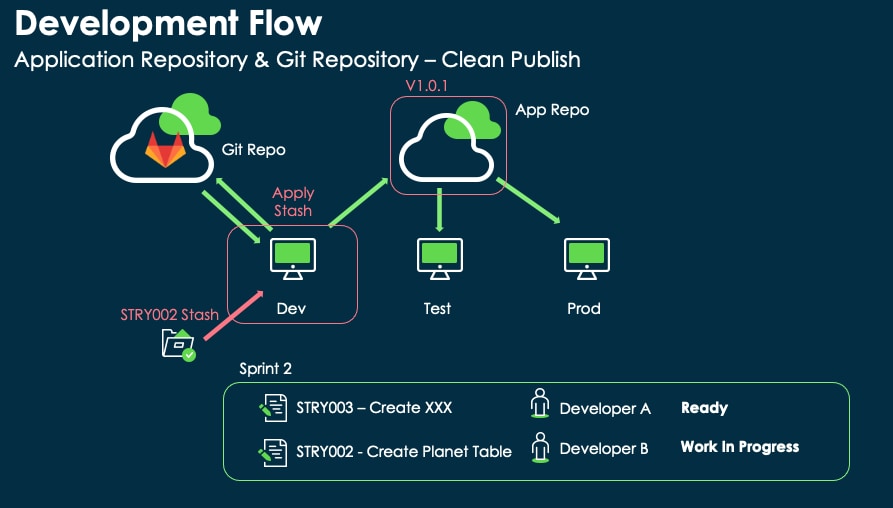
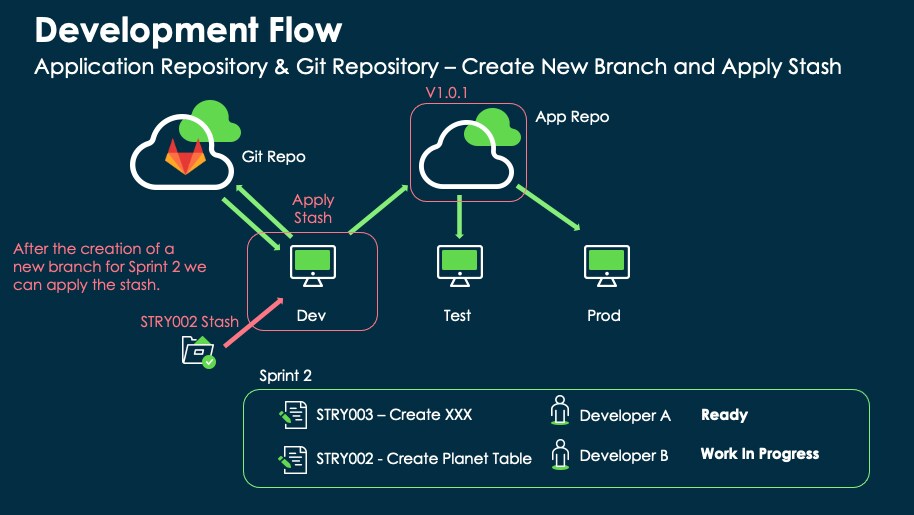
We are now ready to progress with our project. STRY002 will be carried over into sprint two and hopefully finally completed. Sprint 2 is shown in the following image.

Because we are starting a new sprint, we can repeat the step we made initially, creating a new branch to cover sprint 2.
In our example, we will use
- three letters as project name acronyms [BGS]
- the letter R followed by two digits for the release [R01]
- the letter S followed by four numbers for the sprint. [S0002]

After the new branch is created, we can deploy what was previously stashed. This means navigating to the 'Manage Local Stashes' list and re-applying the once-created stash, as shown in the following image.

This will complete the setup for Sprint 2 and enable both developers to continue their work.

Conclusion
The process illustrated in the previous sections can be repeated every time we progress into project implementation. The following image summarises this.

Cheers
R0b0
Kudos to Mr @Ermal Llanaj and Mr @Darren Halliday for their support in evaluating this interesting technical use case.
Kudos to Mr @saschawildgfor the useful suggestions.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- 32,439 Views
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Great article! Just some comments as I read through it:
Update Sets
ServiceNow supports different ways of deploying code from one environment to another. Usually, when working in the global scope (e.g. ITSM implementation), 'update sets' are the preferred method.I would rephrase and say Update Sets are the most commonly used method still, not necessary the preferred though from a ServiceNow point of view.
It is impossible to publish to the application repository from different environments other than DEV.
It is possible, but not from an instance where it is installed from the App Repo. If the application is transferred say via source control, than both instances with the dev code on it can publish to the Repo. I would not recommend it though as you could be overwriting changes without noticing it. It takes some extra care when doing so.
Update Set naming convention:
I would recommend to reverse the order. As you can already see in the screenshot, the story number is truncated in the selection picker. This is a bit tedious for developers in terms who 'where am i'... having the story first helps identifying if they are working in the correct plact.
We can create a new branch for each sprint and select it. While I like that it also means we collect lots and lots of branches in Source Control over time. Also missing is the element how these branches lead up back to the main branch by using Pull Requests/Merges. This is a task someone will need to execute and something a traditional ServiceNow admin needs to get experience with. Managing Source Control is a new / extra task.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
@Ivano B This is a very useful scenario to demonstrate the single dev instance multiple developer setup.
However I have one follow up question: In your example, developer A completed STRY001 and pushed to the TEST instance via app repo. What happens if ATF or UAT fails at this point, how can we back out this change, especially in the case where there are other completed stories that passed testing and can move forward?
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
@zayang The idea is you don't. Backout / remove something from the package you plan to deliver will render your tests invalid - IMHO. You have tested the things in a package, you deploy in a package.
If you want something to not go live which was part of the test, make an update to remove/disable the components. Test this again and deploy right after or with the initial package.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Great article. A question: In the case of global scope, about batch deploy, I understood that we can deploy a group of update sets in bulk, in this case there is only one cash flush in the end of the batch? We are concerned about cash flush because use to make our instance slower, and because of that we use to deploy at night...
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Brilliant, thank you for providing this much-needed clarification, @Ivano B ! I wish this stuff was documented better in the official servicenow docs... the key that I was missing this whole time was to use stash local changes w/ source control link before publishing the app to app repo to move to test and prod. Now that this part is clear, it is much easier and cleaner to promote changes for my custom apps to test and prod without moving in-flight development work that isn't ready to be tested or live in prod.
Thank you so much!!!
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hey @Ivano B,
very nice article, that makes myself clear, how to handle with source control and app repos, but how are adjustments such as hot fixes processed in this way, which are processed independently of the current release/sprint and must be transferred to PROD very promptly? Do you then work normally with the update sets?
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi @Flo
technically you can use an update set in this case, but we do strongly advise against. Once you start using app repo, you should stay on that path due to the nature of how we apply the changes to the target instance (and track those). You run the risk, that an update set deployed change might be revoked with the next app version if not properly managed.
Your best course of action is to stick with the same methodology. In the minimalistic setup (only one dev instance), you will need to stash all ongoing (version+1) changes to get back to what production looks like, implement your fix, deploy. Once ready, reapply the stash and make sure the fix is still available/active. If not, re-do the same fix after reapplying the stash. Then continue to work on version+1.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hello all,
for the time being - and hopefully this era will end soon - we can't use feature branches to let developers work independently on features - which would allow us to make selections when we ship new versions of an app.
Only one branch can be associated for each app in each instance at any given time.
I have seen a number of teams trying to find their way around the challenge of how to handle "work in progress" at the time of app delivery.
The author suggests to use stashing to keep unfinished work on the sideline while providing a new app version to the repo.
While this may work in a very small team with very disciplined developers - who know exactly what they are doing - in reality in large, dynamic teams - the stashing approach fails miserably. There are certain limitations on the technical side - especially when the same person works on complex structures like UI pages or flows and now tries to figure out which records belong to which change or story (but ended up in the exact same update set).
But the even bigger issue is the human factor - we simply cannot assume that every single developer will be able to follow these procedures at all times.
So - as long as we don't have sandboxes and full branch merging capabilities in the platform (so looking forward to it) - this is what works fairly well for large, dynamic, diverse teams:
https://www.wildgrube.com/download/A%20mature%20Development%20and%20Deployment%20Process.pdf