- Post History
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
on 02-23-2022 12:45 PM
Table of Contents:
- Import Sets: Import & Transform (Data Sources & Transform Maps)
- LDAP Import Sets
- Easy Import
- Import Set API (Web Service Import Sets)
- Scheduled Imports
- Import Set Deleter (Table Cleaner)
- Concurrent Import
- The Big Picture - Putting It All Together
- Troubleshooting Performance
- Import Set Summary Tool
- Instance Troubleshooter Import Checks
- Flow Designer/Integration Hub/Service Graph Connectors
1. Import Sets: Import & Transform (Data Sources & Transform Maps)
Quick Overview: Simple import set - Learn Integrations on the Now Platform from Dev Program [0:00-6:17 | 6 Mins]
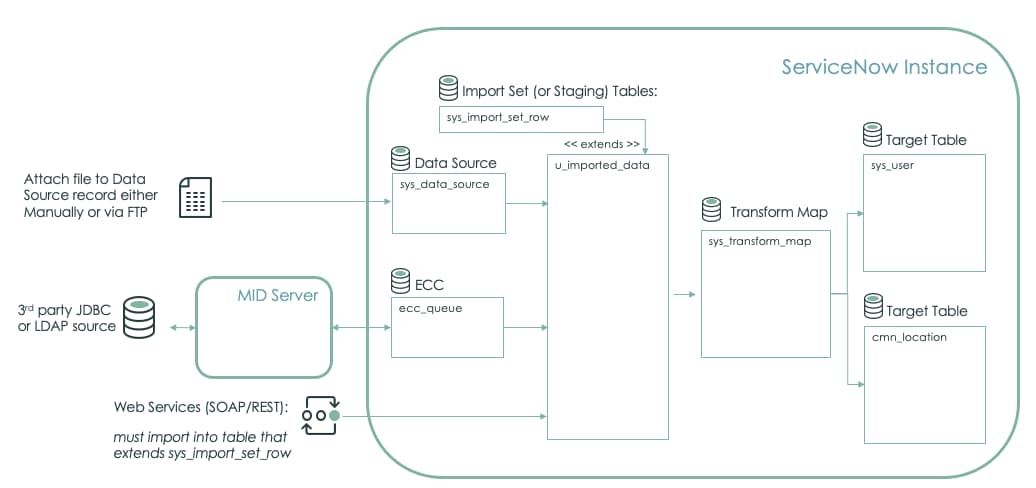
Data Flow Diagram:

from KB0867752,Import/Transform Execution Flow and Table Reference
Configuration:
1. Create and Configure the Data Source [00:00-9:12 from Dev Program | 9 Mins]
2. Create and Configure the Transform Map [0:00-8:51 from Dev Program | 9 Mins]
3. Create and Configure Field Mapping Within Transform Map [0:00-5:50 from Dev Program | 6 Mins]
Test and/or Run the Import Set:
1. Test the Import using "Load 20 Records" from the Data Source record
2. Using "Load All Records" link from the Data Source record
3. Using System Import Sets > Load Data [2:11-5:41 from Dev Program | 4 Mins]
Components, Architecture, and Design:
Data Flow (from source to target table): [KB0867752, Import/Transform Execution Flow and Table Reference]
Table Structure: [KB0867752, Import/Transform Execution Flow and Table Reference]
All Import/Transform System Properties [Official Doc]
Transform Map Event Scripts execution order [Community Article]
Troubleshooting:
Cutting the issue in half (is it an Import or a Transform issue?): [Issues That May Occur During an Import Set section of Community article]
For imports, this is the typical process for creating a new Import Set (test as you build): [0:00-1:17 from Dev Program | 1 Min]
1. Import test 20 records
2. Validate the imported test records
3. Check the source data (compare import set records with the records in the data source)
For transforms, you may find out that some business rules don't run ... [KB0825734, Business rule created on import set table does not fire.]
... on Staging tables - by design the ServiceNow Platform will not fire business rules that are defined on import set tables during a data load by an import process. This behavior cannot be override.
... on Target tables - business rules defined on import target tables will be fired if the transform map has set the flag "Run Business Rules" on.
2. LDAP Import Sets
Quick Overview:

Configuration [Official Doc]
LDAP Server. ServiceNow platform record holds LDAP Server record. One record is required for each LDAP Server [Official Doc]
LDAP OU Definition. ServiceNow platform record that holds information for one LDAP OU definition. An organizational unit (OU) definition specifies the LDAP source directories available to the integration. Every LDAP server definition contains two sample OU definitions: one for importing groups into the system and the other for users. There may be more than one LDAP OU Definition records per each LDAP Server - see diagram on top of section. [Official Doc]
Data Source. ServiceNow platform record that holds import configuration. There should be a one-to-one mapping between LDAP OU Definition record and Data Source - see diagram on top of this section. [Official Doc]
Transform Map. ServiceNow platform record that holds mapping information between the source and the target tables. There is usually one transform map for each of the default Data Source records (Users and Groups) - see diagram on top of this section. [Official Doc]
LDAP Browse Feature
Troubleshooting tool to view the exact state of an LDAP Server object before it is imported into the ServiceNow platform. We strongly suggest to use this as your first step when records imported seem to not match records in the LDAP Server. What you see in the LDAP Browser is exactly what you should expect in the Import Set table after the import is complete.
LDAP Listener
Enabling a listener is optional. If enabled, a listener notifies the system to process LDAP records soon after there is an update on the LDAP server. A listener is a dedicated process that periodically searches for changes on the LDAP server. [Official Doc]
3. Easy Import
Quick Overview:
Easy import is a simplified import process that enables administrators to import only the columns they want.
Video: Easy Import - Learn Integrations on the Now Platform from Dev Program [0:00-4:50 | 5 Mins]
Run Easy Import:
1. Download an import template [Official Doc]
2. Add a record in the template [Official Doc]
3. Update a record in the template [Official Doc]
4. Import a record from the template [Official Doc]
5. Show reference fields as lists in Excel templates [Official Doc]
6. Easy import template validation [Official Doc]
Components, Architecture, and Design:
Easy Import Properties [Official Doc]
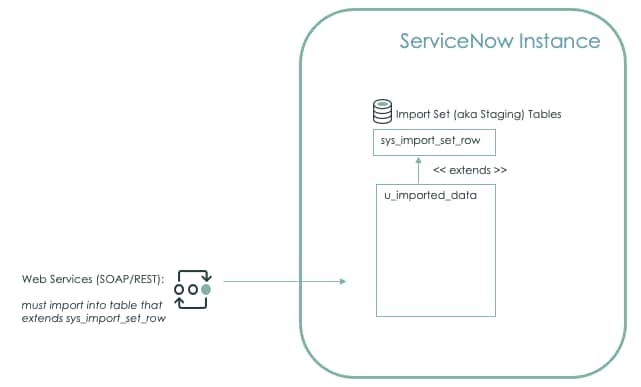
4. Import Set API (Web Service Import Sets)
Overview:
A web service interface to import set tables. This method of importing records, allows direct imports into the Import Set (Staging) table without having to create a Data Source record.

Configure a Web Service Import Set:
Create the Import Web Service (for REST and SOAP) [Official Docs] [Dev Site]
Use a Web Service Import Set (SOAP):
Insert Import Set records using SOAP Web Service [Official Doc]
Use a Web Service Import Set (REST API):
Test the Import Set [Test the Import Set section in Dev Site article]
Insert one record [Official Doc]
Insert multiple records using insertMultiple [Official Doc]
Import Set REST API [Official Doc] [Dev Site]
Components, Architecture, and Design:
Synchronous vs Asynchronous Import Set Mode. By default, this type of web service transforms the incoming data synchronously based on the associated transform maps. If the associated import set mode is set to Asynchronous, the behavior is to save the data for transformation at a later time. [Official Doc]
5. Scheduled Imports
Overview:
Schedule imports to run at a specified interval.
Video: Scheduled Imports - Learn Integrations on the Now Platform from Dev Program [0:00-3:35 | 4 Mins]
Configuration:
1. Schedule a data import [Official Docs]
2. Scheduled data import scripting options [Official Docs]
Components, Architecture, and Design:
Selected properties:
glide.scheduled_import.stop_on_error: Set to true to stop the import process when the parent scheduled import generates an error. [1:52-2:13 from Dev Program | <1 Min]
6. Import Set Deleter (Table Cleaner)
Quick overview:
The Import Set [sys_import_set] table and the Import Set Row [sys_import_set_row] tables or sometimes referred to as the "Staging Import Set tables", and any table that extends from them act as a staging location for records imported from a data source before transforming those records. If these tables are not cleaned, then the import set performance may be negatively impacted due to the large number of records in these tables.
Scheduled Cleanup (System Import Sets > Import Set Tables > Scheduled Cleanup): [Official Doc]
ServiceNow has an out-of-box scheduled system job to maintain the import set table named "Import Set Deleter". If the cleaner job is disabled for any reason, the import set table will grow indefinitely. Sooner or later, it will cause problem at the database level and impact the whole instance when the import is running.
Keep in mind that the import set table only stores the import set meta info. The raw data to be imported are stored in a staging table which is extending the import set row table. So when the cleanup job execute, it will not only delete import sets older than 7 days, it will also delete all the raw data and transformation history associated with that import set, which can be millions of rows for each import set. -- [from Community]
A cleanup of import set records older than 7 days is recommended and is the OOB value [Official Doc]
Manual Cleanup (System Import Sets > Import Set Tables > Cleanup): [Official Doc]
This method not only gives you the option to clear all the records in these tables but delete the tables themselves.
This method also gives you the option to delete Transform Map records associated to the import set tables
Troubleshooting:
Import Set tables are growing large that is negatively impacting performance
Verify that the Import Set Deleter job is currently active and successfully deleting records older than 7 days (7 days is the OOB default, some customers may have changed this value)
Records are being added to the Import Set tables so fast that 7 days is enough to build a large import set record volume. In this case we recommend the customer to decrease the OOB value of 7 days down to 3 days.
7. Concurrent Import
Quick Overview:
Videos: Concurrent Imports - Learn Integrations on the Now Platform from Dev Program [0:00-4:10 | 4 Mins]
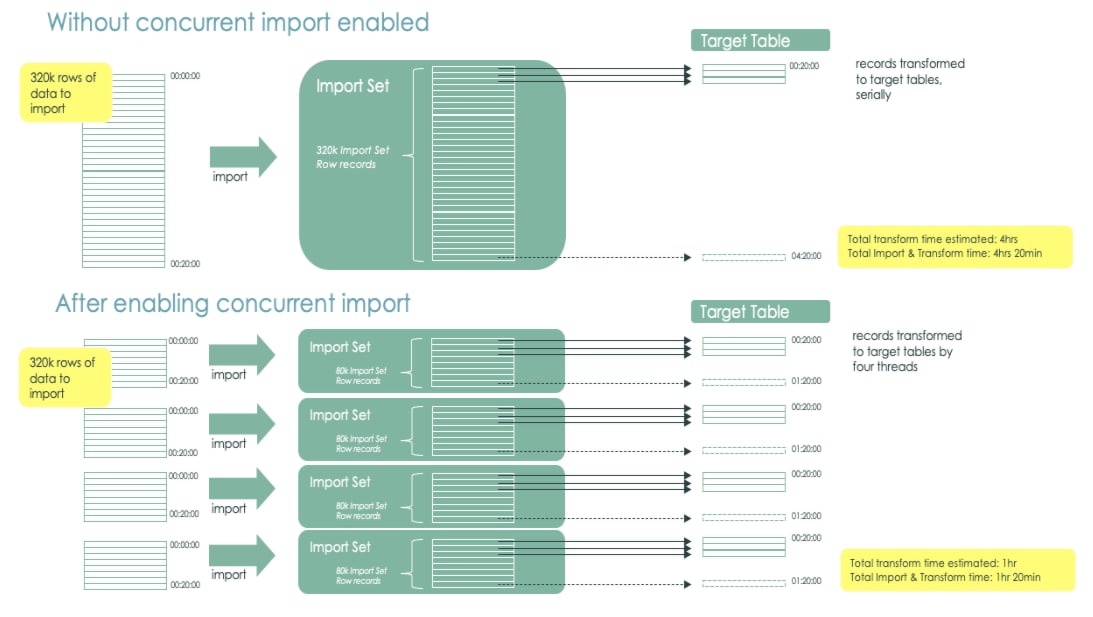
Data Flow Diagram (Time Improvement):
In this scenario without Concurrent Import, the time to import and transform 320,000 records took 4hrs and 20mins. The import and transform were done serially.

In this scenario with Concurrent Import enabled, the time to import and transform the same data took 1hr and 20mins. The transform was done by four processes in parallel.

In both scenarios, the import process took the same amount of time (from 00:00:00 to 00:20:00, 20 minutes). The Concurrent Import has no impact on import processing time. Immediately after the import completed, the four transform processes kicked off (at 00:20:00). Since each transform process is now handling 1/4 of the data, it takes 1/4 of the time to transform.
What is it?
Concurrent import sets is a feature introduced in the Madrid release to handle imports that take a long time to transform large amount of data. This feature helps customer have imports, that usually take a long time during the transformation phase, to be split into multiple import sets for which concurrent jobs transform the data in parallel. This helps bring down the transform run time significantly for large imports. -- [KB0720801]
Using this Feature:
Schedule a normal Import Set job and check the field labeled "Concurrent Import" on the "Scheduled Data Import" form [Official Doc]
Note: by default, this feature does not support order processing. Ordered processing can be done by partitioning data correctly using source partition.
Do NOT use this feature:
... on small imports. Use on very large imports (millions, not thousands) that take a long time (days, not hours) for example.
... until you have exhausted all other Import Set performance tuning options (for example: lack of coalesce field index, slow business rules, slow transform scripts)
Components, Architecture, and Design:
-
- How does it work? [KB0720801]
- The Import and Partition phase:
- First, an Execution context for the scheduled import is created in sys_execution_context table.
- Next, an execution plan is generated in the sys_execution_plan table.
- note: this is how the system knows what to run
- note: this and the previous step occur regardless if the Import Set is running concurrently, or not.
- The number of import sets is calculated. For each node, there will be one Parent sys_trigger job "Import Set Transformer" and there will be 2 child triggers for each parent trigger.
- Data is loaded into each of these import sets using Progress Workers based on the Partition Method selected in the Scheduled import record. By default, system distributes records among import sets in a round robin manner.
- note: this feature has no effect on Import processing time. This feature only affects Transform processing time.
- note: when all data has been imported, the event import.finished is fired. The Parm1 value shows the number of records imported.
- Now that the data is loaded in the import sets, Concurrent Import Set Jobs are created in the sys_concurrent_import_set_job table for each import set.
- The Transform and Processing phase:
- The Import Set Transformer job runs every minute and polls the sys_concurrent_import_set_job queue to transform any pending jobs. Note: only looks for jobs with state "Pending"
- Note: To make sure no other Import Set Transformer job picks up the same concurrent import set job, a mutex is acquired before picking a pending concurrent import set job to transform. Once picked, the state is set to Running and the mutex is released.
- The import set associated to the picked concurrent import set job is transformed with all transform maps as per the Order.
- Once transform completes for the 1 import set, an event ‘concurrent_import_set.completed’ is fired with the sys_id of the ‘Import Set Run’ (Transform History) as Parm1. State of the Concurrent Import Set Job is now set to “Completed”.
- Next, the import set transformer job checks the sys_concurrent_import_set_job table if there are any other jobs for the same concurrent import set that is in state “Pending” or “Running”.
- If there is no such job, then this is the last transform job for this concurrent import set.
- If it is the last transform job, an event ‘scheduled_concurrent_import_set.completed’ is fired with the concurrent import set’s sys_id as Parm1. It then gets the execution context for this scheduled import and triggers the next scheduled import (child) as per the execution plan.
- The Import Set Transformer job runs every minute and polls the sys_concurrent_import_set_job queue to transform any pending jobs. Note: only looks for jobs with state "Pending"
- The Import and Partition phase:
- Aggregated View
- Each concurrent import creates a concurrent import set record. All related import sets, concurrent imprt set jobs and transform histories are shown in this form view.
- Can be used to resume, reprocess all import sets.
- Custom Partitioning
- By default, system distributes records among import sets in round robin manner
- Users can write a custom script to define a custom partition key
- Every row with same partition key adds to same import set
- Pre/Post Scripts
- For non concurrent scheduled imports
- import_set parameter refers to Import Set GlideRecord
- Pre script runs before loading data with scheduled task execution thread
- Post script runs after transformation with the same scheduled task execution thread
- For concurrent scheduled imports
- import_set parameter refers to Concurrent Import Set GlideRecord
- Using the sys_id for this record, users can refer to all import sets, transform histories
- Pre script runs before loading data with scheduled task execution thread
- Post script runs after the last transformer job completes
- import_set parameter refers to Concurrent Import Set GlideRecord
- For non concurrent scheduled imports
- Hierarchical Imports
- Scheduled Imports can be set to run after another scheduled import (Parent import)
- This makes a scheduled set hierarchy
- One parent can have many child imports and they execute in the order specified
- Execution should start from the parent and all scheduled imports should be executed in the depth first order
- In London and previous releases, the scheduled job, which executes the parent import, executes child imports in the depth first order
- For Concurrent Import Sets, child imports can only be started after all Import Set transformer jobs completed
- Scheduled Imports can be set to run after another scheduled import (Parent import)
- Execution Plan
- Set of GlideRecords denotes next scheduled import process (in the depth first order of scheduled import hierarchy) for each scheduled import
- At the beginning of parent import process, execution plan is generated and each import process uses it to fetch the next process to invoke
- For non concurrent imports, scheduled job fetches the next import and executes it
- For concurrent imports, last transformer job fetches the next import and executes it
- Synchronized Inserts
- Coalesce fields are used to define the uniqueness among the records
- At the transformation time, transformation process checks fore an existing record with the coalesce values and updates the existing record if exists. Otherwise inserts a new record
- With the concurrent import, two records with same coalesce values can be inserted if both records get processed the same time with to transform processes
- Inserts are synchronized with a lock to avoid multiple inserts
- By default, concurrent import supports synchronized inserts
- The maint only Synchronized insert field can be used to disable this behavior
- Selected Properties:
- glide.scheduled_import.max.concurrent.import_sets [2:41-2:59 from Dev Program | <1 Min]
- Lock related properties:
- com.glide.concurrent_import_set_insert_mutex_spin_wait (default: 1000)
- Wait time mutex spend if the lock is acquired
- Specified in milliseconds
- com.glide.concurrent_import_set_insert_mutex_expiration (default: 300000)
- Mutex expiration time
- Specified in milliseconds
- com.glide.concurrent_import_set_mutex_fast_lock (default: false)
- Whether to use fast lock or sql based slow lock
- com.glide.concurrent_import_set_insert_mutex_spin_wait (default: 1000)
- How does it work? [KB0720801]
-
- Database Schema Changes
- New Tables:
- Concurrent Import Set [sys_concurrent_import_set]: Keeps details of each concurrent import
- Concurrent Import Set Job [sys_concurrent_import_set_job]: Keeps the import sets to be processed
- Execution Context for Scheduled import [sys_execution_context]: Execution context for each Scheduled import
- Hierarchical scheduled import execution plan [sys_execution_plan]: Execution plan for hierarchical imports
- Adding columns to existing tables:
- Scheduled Data Import [scheduled_import_set]
- Concurrent import [concurrent_import]
- Partition Method [partition_method]
- Partition Script [partition_script]
- Synchronize Inserts [synchronize_inserts]
- Import Set [sys_import_set]
- Concurrent Import Set [concurrent_import_set]
- Transform History [sys_import_set_run]
- Concurrent Import Set [concurrent_import_set]
- Scheduled Data Import [scheduled_import_set]
- New Tables:
- Database Schema Changes
Troubleshooting:
Use Concurrent Import Aggregated view to get status of Concurrent Import. This view provides information such as:
all Import Sets associated to one Concurrent Import
Status (and errors, if any) for each Import Set associated to the Concurrent Import
all Transform Histories associated to one Concurrent Import
8. The Big Picture - Putting It All Together
In this section, we provide two different methods to summarize the Import Set feature.
Data Flow Diagram
This diagram shows the flow of data and the tables they touch from data source to target tables.

Table Structure
This diagram shows the tables that make up this feature. Note the three different colors to mark the three main functions.

9. Troubleshooting Performance
Import
Importing Data That Has Not Changed [Official Doc]
Large Import Set tables [Official Doc]
Altering Table Schema During Import [Official Doc]
Importing Very Large Data Sets [Official Doc]
Transform
Running business rules during Transform [Official Doc] - Option to run business rules, workflows, approval engines, auditing, and field normalization while the transformation inserts or updates data into the target table. If the customer has slow business rules on the target table, then the overall performance of the transform phase will be negatively impacted.
Determine if a business rule is running on top of the transform map [KB0538161]
Slow Transform Scripts [Official Doc] - pay close attention to scripts that run on each record import/update.
Coalescing On Non-Indexed Fields [Official Doc]
Scheduling
Running Imports Simultaneously [Official Doc]
High-level steps to troubleshoot slow Import Sets
Step 1: Identify if the rate of import is slow, or if the total time is long
Step 2: Identify if there is overall slowness or a bottleneck
Step 3: Identify where the bottleneck is occurring
10. Import Set Summary Tool
Quick Overview
The Import Transform Summary Tool is a script that runs in scripts–background and provides an Import Set summary.
The script output is made up of three sections: Definition, Runtime, and Transaction. The definition section shows data regarding the import configuration. The runtime data is information that is usually found in the import set records or data created when the import and transform actually run. Finally, the transaction part of the output gives information regarding the transaction that ran the import/transform job. [KB0870045]
How To Use This Tool
Step 1: Copy and paste the script found in [KB0870045] into the Scripts-Background area
Step 2: Replace the value of "iset" with the desired Import Set (ISET) number
Step 3: Execute the script
11. Instance Troubleshooter Import Checks
Quick Overview
Instance Troubleshooter, a free store application, helps ServiceNow instance administrators to resolve issues on their instance by themselves. This application can detect issues in the instance across several product categories including Import Sets. When the administrator invokes the troubleshooter on a suite, it runs one or more checks and reports its findings with detailed information and links to resolving the issues by themselves.
Video: 7/27 - Ask The Expert - Instance Troubleshooter Application from Community [2:46-5:01 | 2 Mins]
KB: KB1112531 - Instance Troubleshooter Overview and Quick Start Guide
Selected Import/Transform Checks
A JDBC-type Data Source must have an up-and-running MID Server associated to it. This check alerts the user if it detects a JDBC Data Source without an active MID Server.
A File-type Data Source with File retrieval method is NOT "Attachment" retrieves the file from an external source. If the instance cannot access the file, the import will fail. This check alerts users if it detects connection errors while retrieving this file.
A File-type Data Source with File retrieval method value of "Attachment" must have a file attached to the Data Source record. This attached file has the contents of the data to be imported. This check alerts the user if no file is attached to this type of Data Source.
Adding new columns to large Import Set tables may significantly degrade the instance's performance. A property exists that determines whether or not to automatically add new columns during the import phase. This check notifies the administrator to disable this property.
Dates are not converted correctly when using Easy Import. This issue is mitigated by updated a system property.
For the complete list of checks see KB0966883
12. Flow Designer/Integration Hub/Service Graph Connectors
Quick Overview
Flow Designer: A simple way to create automated workflows (or processes) in a single design environment using mainly drag-and-drop. Allows non-developers to create repeatable activities in a ServiceNow instance that are easy to reuse within and outside of Flow Designer.
Integration Hub: Use Flow Designer to integrate with third-party applications using run-ready connectors called spokes to connect to third-party systems.
Service Graph: Service Graph is not a product or feature. It is a strategy. Service Graph is the next-generation system of record for digital products and services. It implements the Common Service Data Model (CSDM) on the Now platform and provides associated life-cycle management capabilities. Service Graph extends the notion of CMDB to include new data types that encompass the entire digital lifecycle of applications and services. Where CMDB has traditionally focused on infrastructure, assets and their relationships, Service Graph encapsulates data from planning to design to application development and deployment, so the data it captures is broader and deeper than CMDB alone.
Service Graph Connector: While IntegrationHub Spokes provide stand-alone and shareable integrations with 3rd parties, Service Graph Connectors provide stand-alone and shareable Service Graph imports from 3rd parties. ServiceNow created and supports some Service Graph Connectors. Also, a number of design partners and beta customers have been using this toolset (IH-ETL, RTE, IRE) to develop new connectors with great success.
Data Flow Diagram (Flow Designer & Integration Hub):

Data Flow Diagram (Service Graph Connectors with Integration Hub ETL, RTE, and IRE):

Roadmap:
A new learning path community article dedicated to Flow Designer, Integration Hub, and Service Graph Connectors will soon be published.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- 13,378 Views