- Post History
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
on 12-11-2017 04:43 AM
With GlideRecord, ServiceNow has quite a simple API to access its database, with good options on filtering, aggregating and querying result sets. However, it doesn't provide an easy way for you to cache its result, in case you have larger scripts that perform repeated database lookups for the same queries.
I've often come across the need to have longer running scripts that need to perform the same kind of lookups over and over again. If you perform a new GlideRecord query every time, that can seriously reduce your scripts performance.
Let's look at the following (contrived) example. Imagine that you have a list of problems, and for each of them you want to know how many other problems exist for the same configuration item.
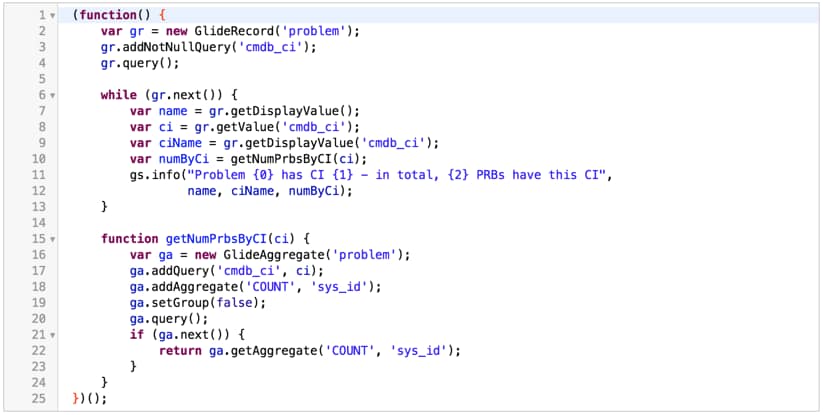
Naí¯ve implementation
A naí¯ve implementation would just query the database for every problem, and look like this:

The result of which would look like this:

Now the problem is that you repeatedly call the database with the same query, which is unnecessary and inefficient. Specifically, you can see that "SAP ORA01" is used three times, and ideally you'd only query the DB once for this CI, not three times.
Manual Caching
One way to deal with this is to cache the results yourself. You set up your own cache variable, and store the results in it, and for every query you check if you already have a result for that input value and only query the DB if you don't. It looks like the following:

In the real world, you might store the cache as a property of your Script Include, but this works fine. The output is the following:

The drawback is, you have to reimplement this kind of logic every time you need to have repeated lookups in your scripts. It also gets more complicated if you have multiple input variables to cache. Ideally, we want to have a repeatable pattern that we can apply. Thankfully, we have that in the pattern of memoization.
Memoization
The idea is that we can take an arbitrary function, like in our case the function that looks up the number of problems per CI, and turn it into a cached version. The function doesn't know anything about caching and doesn't have to care. Using memoization, we can turn it automatically into a function that caches its result.
Assuming I have my memoization function stored in the global script include "Memoizer", the version using memoization looks like the following:

As you can see, the memoizer basically takes the "naí¯ve" version of the function and returns a new function (which I prefix with $ to show that it's memoized — just a personal convention). You can then subsequently call the memoized function and let the system deal with the rest. The memoized function caches the input and only calls the original function if it doesn't find the result in its cache.
Conclusion
The result of applying memoization is a a collection of easy to understand functions, with the caching logic nicely kept separate from the business logic. And every time you create a new lookup function, you just have to apply the memoization, and it just works.
I attached the memoization script include I use as an attachment in case you want to try it.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
How will this work with 1000, 10000, 100000 records? I would imagine this use a lot of internal memory.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Depends on the size of your input and output values.
If your input and output are just single numbers or booleans, you'll need a few dozen bytes per cached result.
If you have strings, it might be several hundred bytes. So in the latter case, 100.000 cached results might need a few dozen MB of RAM, which isn't too bad. It will also be reclaimed quickly after the Rhino context is shut down after script execution.
Also keep in mind that you only store results for distinct input values. If you have 100.000 records and most of them result in different input values, it doesn't make sense to use caching in the first place. This technique is especially valuable where you have a lot of lookups with the same value.
In general, you still have to think about when this makes sense to use. In most cases, using up a few megabytes of memory for caching is better than querying the database hundreds of times with the same query.