















Simon White1

ServiceNow Employee
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
06-30-2016
01:04 AM
By Simon White and Tony Branton
ITOM Practice Team
Introduction
ServiceNow's Event Management application enables the consolidation and management of the Enterprise's IT events. Typically, this means creating actionable alerts from performance and operational health events coming from various IT monitoring tools. When you overlay these alerts on service maps created by ServiceNow Service Mapping, you start to realise significant improvements in Service Assurance processes and improved levels of IT service to the business.
Out-of-the-box (or should that be Out-of-the-cloud), ServiceNow Event Management provides connectors for some popular monitoring tools like Microsoft SCOM and IBM Netcool/OMNIbus. However, one of the benefits of Event Management is the ease of integration with nearly all monitoring tools available today.
In this article I want to share some experiences from a recent project I undertook with a large insurance company in Australia. The project's objectives were to map out one of their complex application environments (mostly an IBM stack) and provide real-time event integration with their IBM Tivoli Monitoring (ITM) tool. The ITM event integration involved the use of the ServiceNow REST API Event Management capabilities in the Geneva release to dynamically transform incoming events into standardised and actionable alerts. Please note that whilst this article focuses on ITM event integration, the strategy and capabilities equally apply to any other monitoring tool which can call the REST API and pass in useful information about an event.
One of the important project considerations was to minimise the changes required to ITM in having to reformat messages to fit ServiceNow's common event format. This can be easily accomplished in Event Management through the use of Event Rules. As part of building out these rules, regardless of where the events are coming from, it is critical to ensure that alerts correlate accurately to the correct CI. Business value provided by the service map can be diminished if alerts are not bound to the correct CIs and can lead to delays in finding the root cause CI or misunderstanding the impact of an alert.
Service Mapping Review
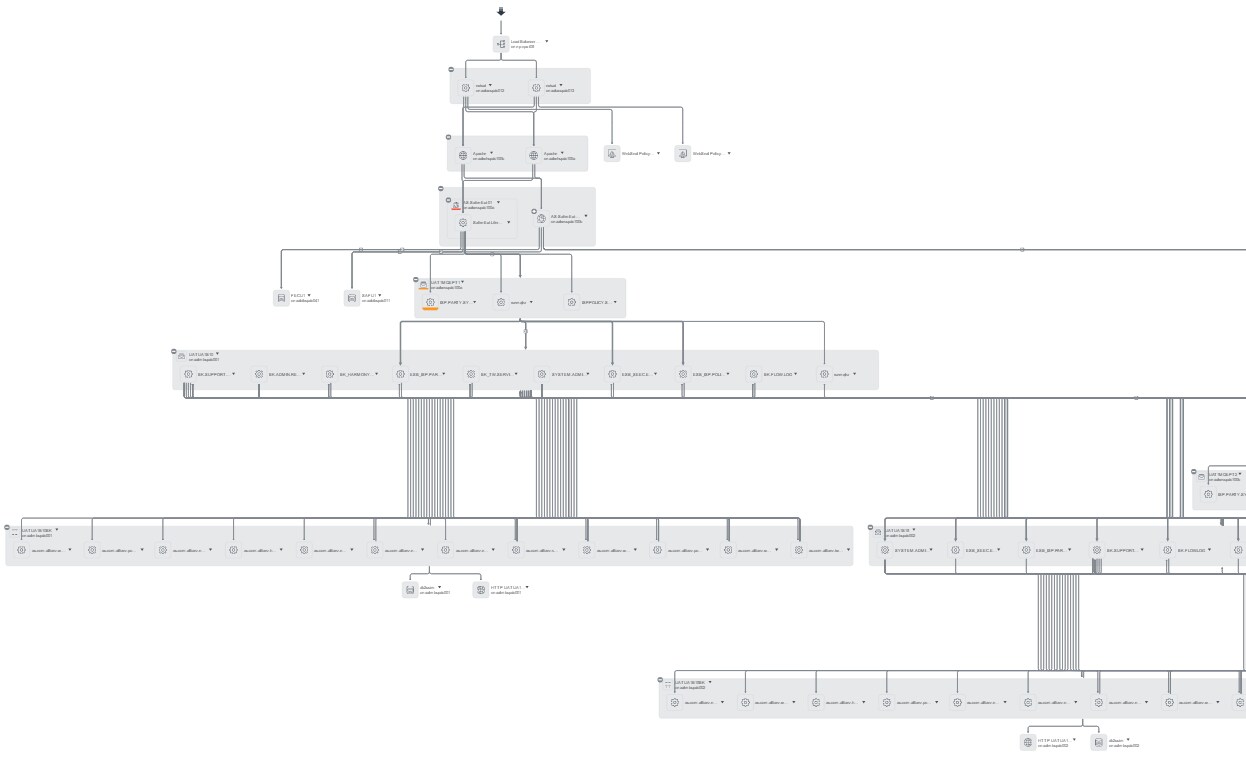
For this project, the application Service Map was very detailed and included many container-type relationships. For example, a WebSphere Application Server (WAS) cluster contains WAS instances which in turn contain Enterprise Archives (EARs — the Java application modules). Service Mapping also uncovered and mapped the application's very complex relationships within their middle-ware environment (traditionally a nightmare task).
Whilst the details are illegible, the following screenshot shows the numerous levels of infrastructure and multiple linkages (in both directions) to drive user transactions. The WAS-based application talks to a queue in an MQ queue manager which talks to a message flow within IBM Message Broker which in turn talks to Data Power which in turn… you get the idea.
If the monitoring technologies (in this case ITM) determine that an event has occurred with one of the low-level components, we need to ensure that when the event is processed the resulting alert is attached to that specific component and not to the higher-level software CI or indeed the server hosting it.
Sending the Event from ITM
The REST API is well documented and can be used to inject events directly into the ServiceNow Event table (em_event). This is the appropriate place for all incoming events from where Event Rules will determine which events to drop, de-duplicate or escalate up to alerts for handling. The ServiceNow Event doc summarises the fields you need set when making the REST call. For the ITM integration, you can use a script invoking cURL or code it in your favorite scripting language (e.g. Python).
Here's an example of a Windows-based batch script calling curl:
And a Python snippet:
Parsing the Event Data
The most important parts of the event are the identifying fields describing what actually went wrong. ITM is very good at providing numerous fields to describe where the event occurred and why. Per the ServiceNow Event Management documentation, you can simplify the event processing by directly providing the correct information in the expected fields. E.g. set the "source", "message_key", "time" and "severity".
Any other useful event information should also be included in the REST call, appended in JSON format to the "additional_info" field. For example, the above cURL sample pulls the event content from a file which looks like this:
The fields in yellow and purple are expected event attributes. The pink are additional fields which help enrich the resultant alert whose data might then be used in an incident. They will also be used to correlate the event to the correct CI and provide useful information to the Event Management user who is triaging the incident.
Binding Events to a CI
The Event Management application follows a set of rules to work out which CI to bind an alert to. This is documented here and depicted in this flowchart:
For events impacting hosts, the automatic event-parsing rules do a good job of binding the alert (and related events) to the correct host CI. In the above flowchart, decision #1 will flow to Host CI Binding using the Node name as lookup.
But what happens for alerts impacting sub-components (i.e. specific resources within a given container) if only the node field is specified? Without helping Event Management, these alerts will fail to be bound to the correct CI or in some cases to any CI whatsoever. The default binding logic will see that a node has been specified (the host where the impacted service is) and incorrectly bind the alert to it, instead of continuing down the flowchart to #2 which is what we want.
Forcing Binding to the Exact CI You Want
You could solve this by changing the originating script to complete all the required fields correctly and null the node field, but this will need to cater for different types of event. This approach will see the script quickly grow in complexity and become difficult solution to maintain and troubleshoot.
A much better approach is to use Event Rules to bind alerts to CIs — this is one of the things they're designed to do. They can be used to manipulate events arriving from multiple external sources to conform with the internal CMDB schema and work with event processing logic. One important note to remember about Event Rules is that they don't change the raw event in the event table. They act on a copy of the event (in memory) and apply your transformation rules before processing it into an alert.
Two fields available in the Event table can be used in an Event Rule to control how alerts are bound to a CI:
- ci_identifier — used to specify the match criteria which is used to search for a matching CI. The criteria as name:value pairs in JSON format. The name in each pair must match the name of a field from the target CI table. The more matching criteria you provide, the more accurately you can match a CI — this becomes increasingly important if there are CIs with non-unique names.
- ci_type — used to specify the CMDB CI class. Setting this field limits the scope of the search for a matching CI to just those that have the specified CI class. Although not mandatory, it is highly recommended and can help optimize the performance of the Event Rule, especially if your CMDB has a large number of CIs (e.g. > 50,000).
Now that we know what fields can be used to match a CI, let's look at how we can set these using an Event Rule. Event Rules can be configured to Ignore (or filter) events, Transform events or apply a Threshold condition to control when an alert is created. To set the ci_identifier field we'll use the Transform operation to extract data from the incoming event, store it in variables and then compose the ci_identifier field for matching a CI.
We begin by creating a new Event Rule, providing a descriptive name and specifying the event source to ensure the Event Rule will be applied only to events with a matching event_class field value (e.g. ITM). We then need to specify a filter condition to ensure the Event Rule is applied to specific types of event. Referring back to the sample event data above, we could specify that the Event Rule should be applied to ITM events where the Type field is "ITM Queue Statistics" (Note: the specific fields and values will depend on how your monitoring tool provides the information).
Next, we need to define the Event Match Field specification which will be used to extract data from the additional_info field and map it to variables. It's here we need to examine sample events to identify the specific source event fields to match. Referring again to the sample event, we might identify that the information we need for the ci_identifier require the queue_name and mq_manager_name fields. So the Event Match Fields section would look something like that shown below:
Here we use the regex (.+) to select all the text in the queue_name and mq_manager_name JSON pairs from the additional_info field in the event, and map them to temporary variables. Note that these variables will be added to the additional_info field in the alert.
Now it's time to compose the ci_identifier field so a CI can be matched. Before we do that, let's take a look at the impact of non-unique CI names on binding alerts to CIs and what we can do to make them unique.
Dealing with Non-unique CI Names
Whilst every CI record in the ServiceNow CMDB has a unique system identifier (sys_id), the name of a given CI may not be unique. For example, in an MQ environment, there are likely many queues with the same name — but defined in different queue managers. There will be multiple records in the MQ queue CI table with the same name. The "queue manager name + queue name" provides the unique reference to differentiate CIs.
This introduces an added complexity when binding an MQ queue alert to a matching CI. We can't simply use the queue name to bind — as it may bind to the wrong queue. The obvious solution is to use the ci_identifier field and add additional attributes to ensure the correct CI is bound to — namely the queue manager. This strategy works fine assuming there are in fact additional fields in the table to provide that uniqueness. Unfortunately, this isn't always the case so a little more configuration is needed to provide it.
In the MQ queue table (cmdb_ci_appl_ibm_wmq_queue), the related (owning) queue manager isn't included by default, so we need to add it in. Given the underlying flexibility of the ServiceNow CMDB schema this is easily done:
- Add a custom column to the table to hold the queue manager name:
- Update the MQ mapping pattern to fill in the field when the object is discovered. This could also be done during base MQ discovery and would be preferable if mapping hadn't been deployed yet.
- Remember to save your changes and activate the pattern before re-running the service mapping discovery.
- Service Mapping will extract the MQ Queue Manager name and populate the Queue Manager (u_queue_manager) field we previously added to the MQ Queue table for the discovered CIs.
At this stage we now have CIs that are no longer non-unique and can proceed to completing our Event Rule to bind alerts.
Completing the Event Rule
In the Event Rule, we compose the ci_identifier field using the queue name and queue manager name to force binding to the specific queue CI:
There's one more step we can perform before saving this Event Rule: setting the CI type. As mentioned earlier, this isn't mandatory however as the number of CIs in the CMDB grows it can impact the time taken to match the CI and therefore impact event processing performance. Our completed Transform section now looks like the that shown below:
Results
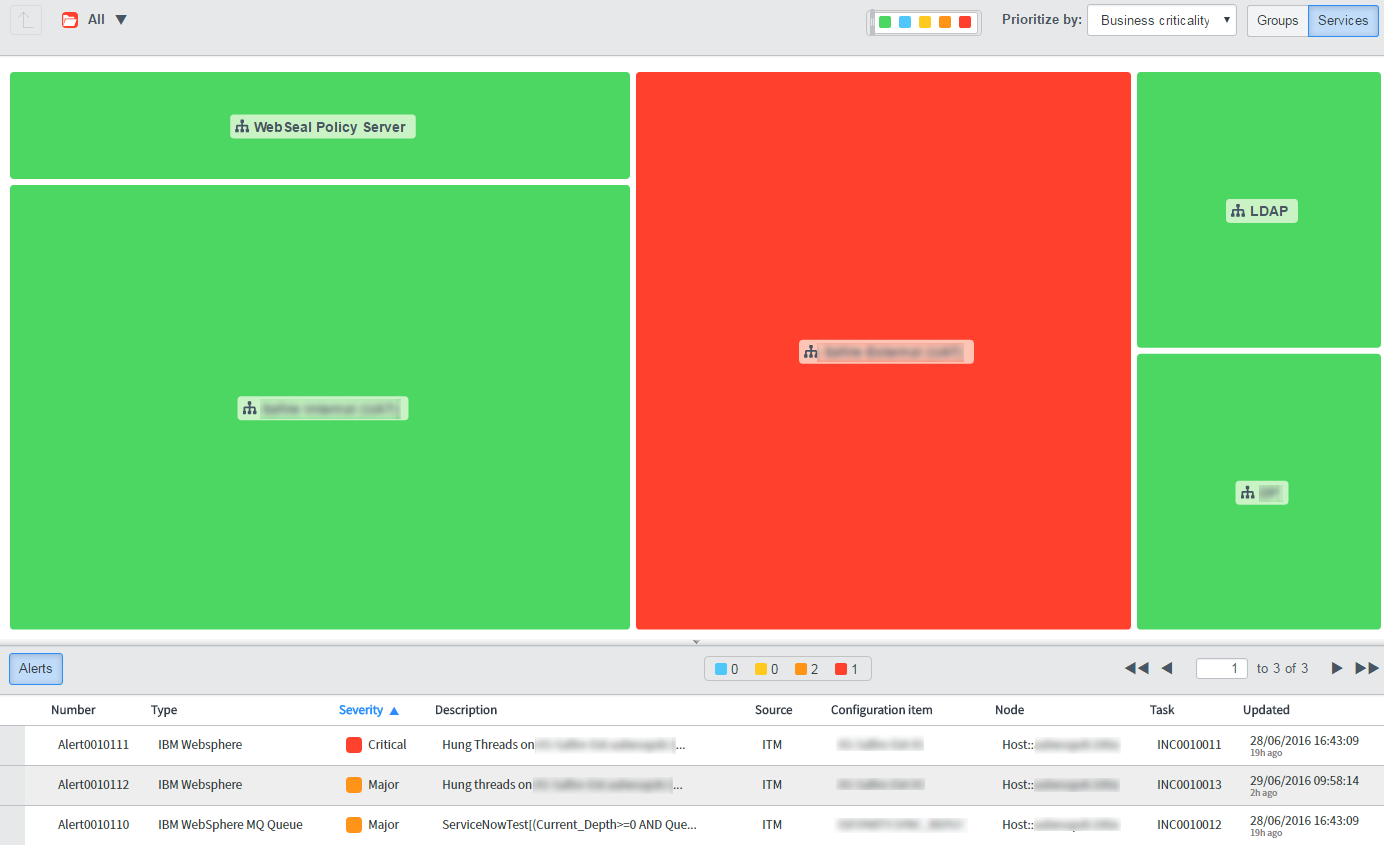
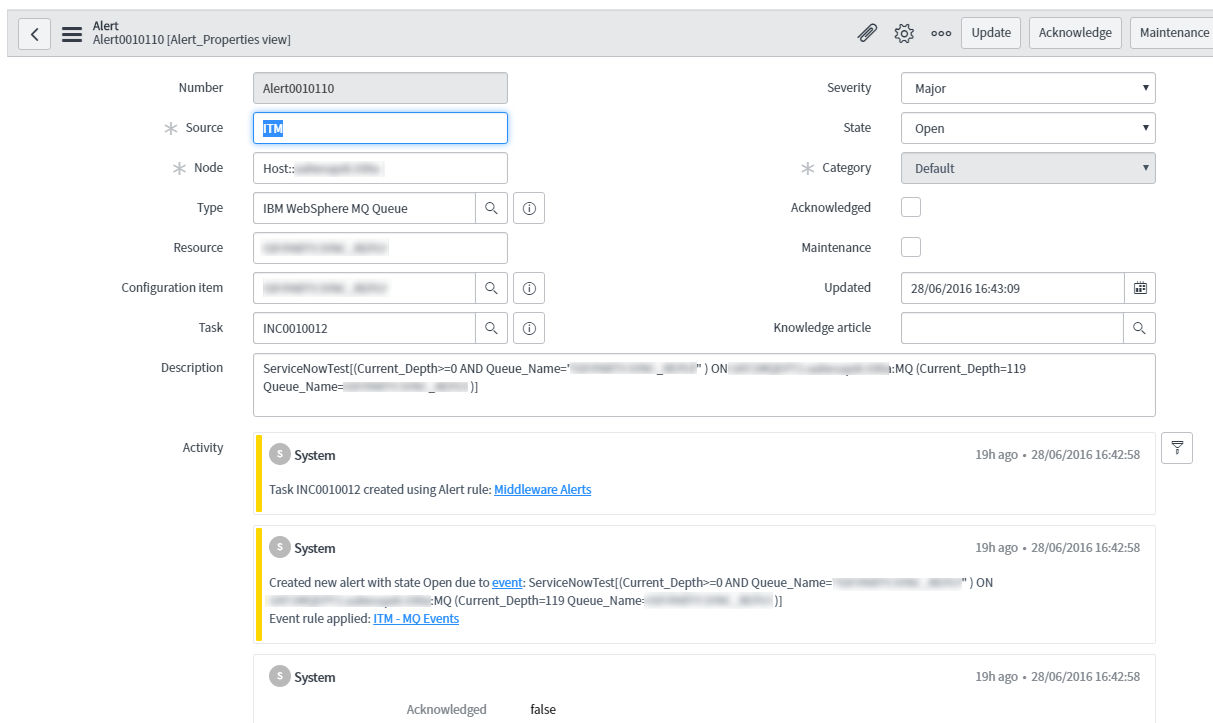
With the addition of a CI attribute and our new Event Rule, now when the ITM events are received, they are automatically processed and the resulting alerts are bound to the correct CIs. Since the CI is related to a business service by virtue of a service map, Event Management can calculate the impact of the alert on the business service and automatically update its health status. IT Operations teams can now not only be alerted to an impacted service, but are able to drill down to identify the CI as the probable cause. Depending on any Alert Rules, incidents or other tasks may then be automatically created.
Binding to alerts to specific CI's ensures that our monitoring dashboards and triage efforts focus only on those impacted services.
The following series of screenshots show the results of this successful project. Please contact us if you need further information.
Sample Business Service Health Dashboard:
Application Service Map showing overlaid ITM events:
Alert created from event and bound to specific impacted resource:
Incident record assigned to resolver group detailing CI and impact:
MQ queue CI relationship view showing impacted service:
If you'd like to learn more about ServiceNow's Event Management capabilities, please see the Learning Library here.
- 12,539 Views
3 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}