- Post History
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
10-20-2020 01:52 PM - edited 12-11-2025 03:01 PM
** Zurich update. Predictive Intelligence has gotten several welcome updates. The core concepts of this article are still applicable.
- Classification has new Advanced Solution Settings.
- We added a feature analysis capability called "model explainability" which provides visual impact of features on the predicted class. You can use that along with the Predictability Estimate method shown below.
- We added a new LightGBM algorithm for classification model training in addition to the Feed Forward Neural Net and XGboost algos for classification.
- Access Predictive Intelligence from AI Agents or Now Assist skills using the Now Assist Skill Kit(NASK) Predictive Intelligence tool. This allows your AI Agents and NASK skills to access your Predictive Intelligence models - combining deterministic and generative AI into one pipeline.
- Word Corpus is no longer needed for vectorization. Google Universal Sentence Encoder (GUSE) is used as the default (introduced in Utah).
- You have the ability to exclude classes in the prediction.
In this article I’ll cover two methods to tune your Predictive Intelligence classification model.
Method 1 - Auto-Tuning a classification model
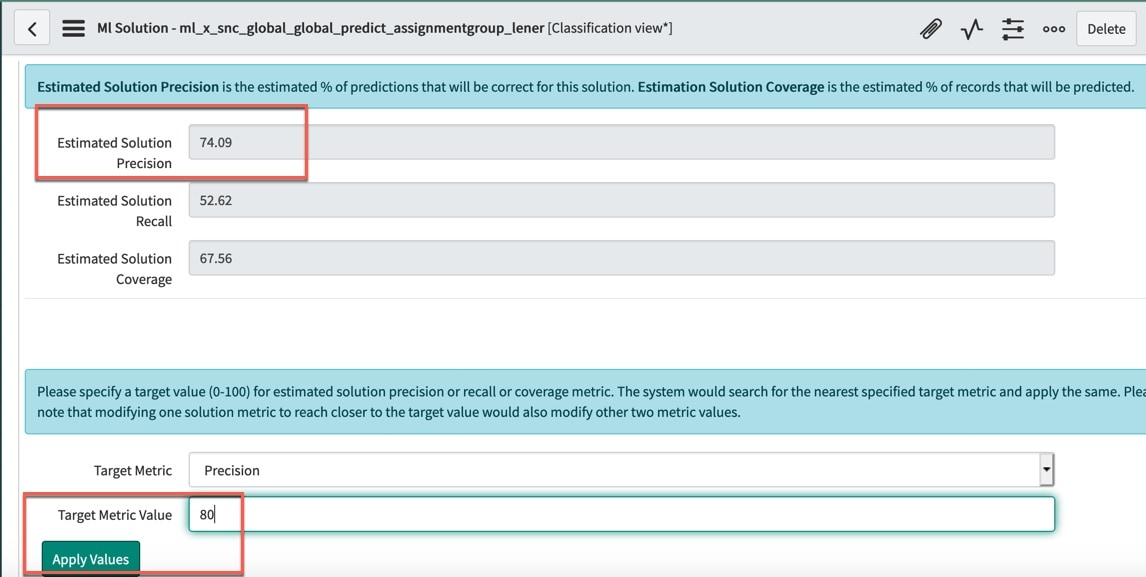
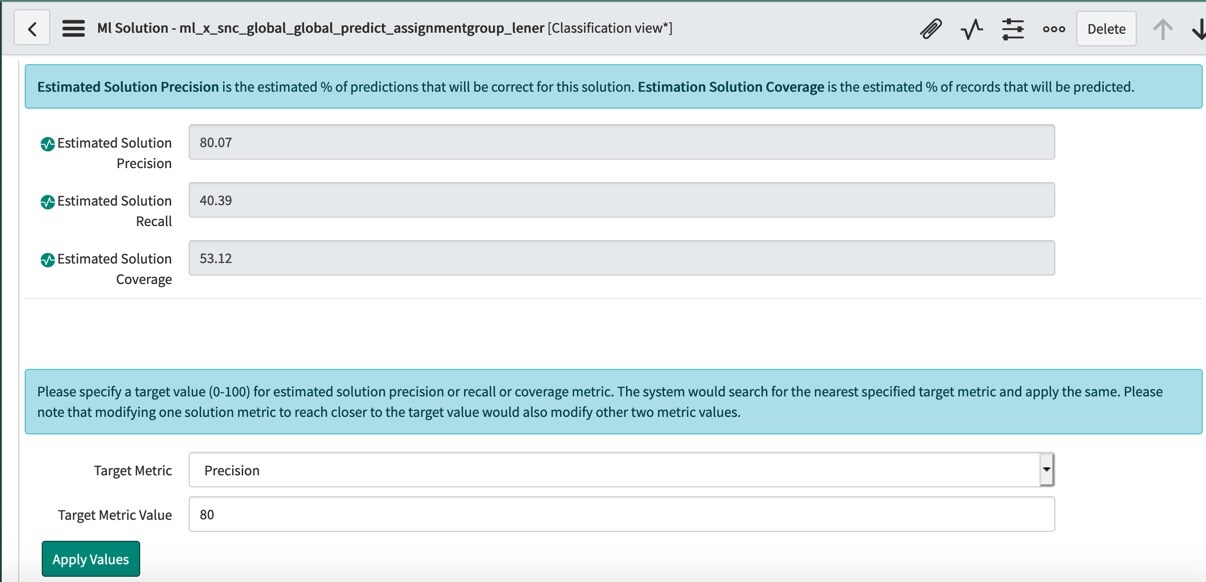
The simplest way to “tune” a Predictive Intelligence classification model is to set the Target Metric Value. Navigate to your trained solution and click into the Solution Statistics tab. In the below example my Estimated Solution Precision is 74.09%.

If I wanted to improve the precision, I can set the Target Metric Value to a higher precision (in this case 80%) and press Apply Values. The target metric value will optimize the precision by adjusting the recall and coverage percentages for the model. The below picture shows that we have improved our model to a precision of 80.07%, but we did drop in recall and coverage to get the precision gain.

Method 2 - Adding inputs to your model
A second way of tuning our classification model is to add additional inputs to our classification solution definition. The question is, which inputs will have the most impact in improving the precision of the model? To answer this question we can use the PredictabilityEstimate object.
We’ll use the ML API() to instantiate and use the PredictabilityEstimate object in two steps.
Step 1 – Create and submit the PredictabilityEstimate
The PredictabilityEstimate is a scriptable object that provides an estimation of which features can be useful for predicting the target field for classification. To read more about the ML API() and the PredictabilityEstimate object please see our documentation. To learn more about the inputs see the DataSetDefinition doc.
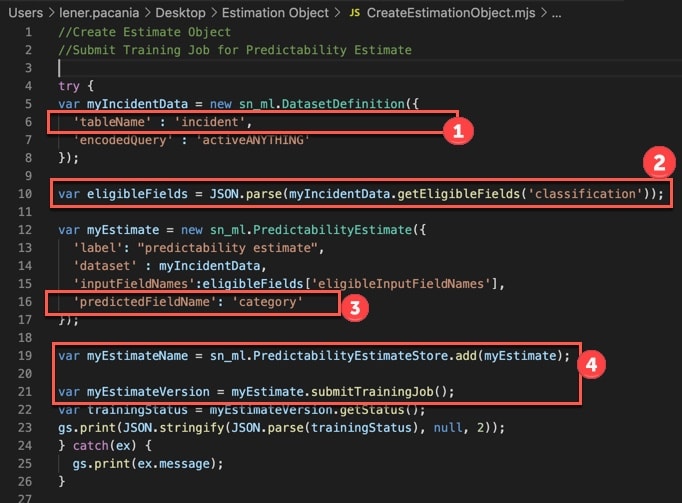
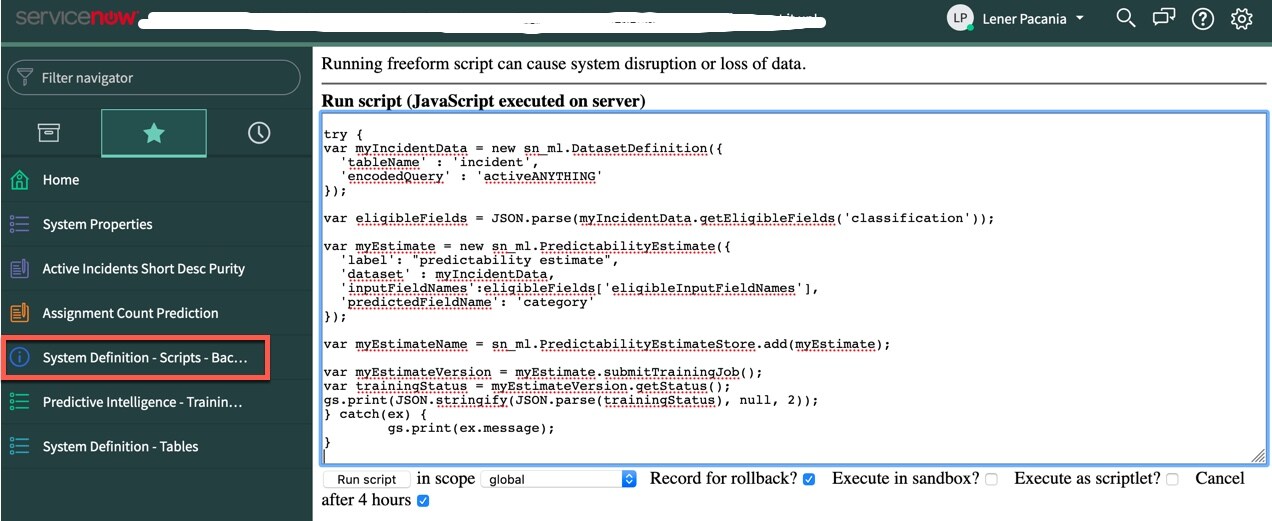
Copy & paste the below code (attached as createEstimate.txt) and run as a background script, by going to System definition > Scripts – Background. The below java script uses the PredictabilityEstimate object to recommend input fields to improve the classification prediction for category. If you want to use a different table or a different predicted target field, just swap them out.

I did a quick synopsis of the below key blocks of code 1-4.

Block 1 – specifies the “incident table” as the table with our training data.
Block 2 – says we want to test for “classification” in our solution
Block 3 – defines the target predict field as category
Block 4 – Adds our PredictabilityEstimate object, myEstimate, to the PredictabilityEstimateStore and submits the training job.
Step 2 – Get the unique name of the PredictabilityEstimate
Go to the ML Solutions table and get the unique name for the predictability estimate object that you just created. In my example it’s, ml_x_snc_global_global_predictability_estimate.

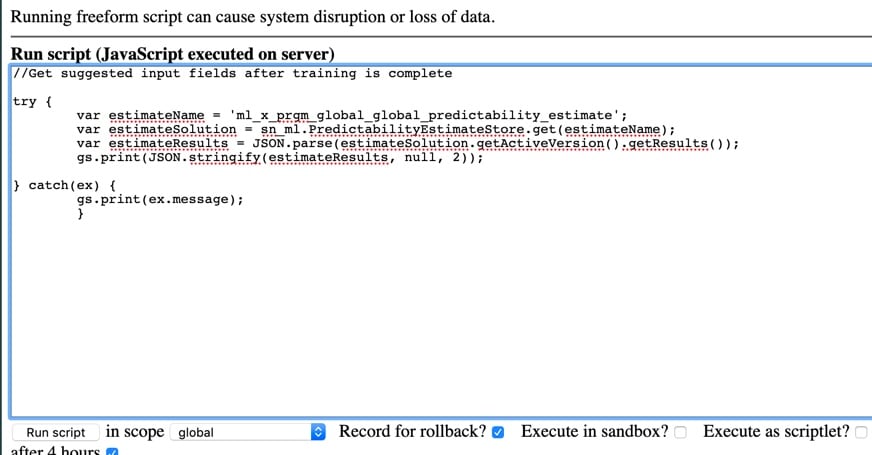
Step 3 – Query the PredictabilityEstimate for the recommended input fields
Run the below script to retrieve the Predictability Estimate score for predicting category using classification (see attached script retrieveEstimate).

Interpreting the results:
The script outputs two valuable insights when predicting category. The first being the impact of “nominal field inputs” on improving the model. The second calculates the “density of text input fields”. I won’t get into all the data science details here, but at a high level we’re using feature ranking that leverages a mix of weighted information gain techniques, AUPRC (area under precision recall curve), ReliefF Scoring, and a pre-trained model to select and rank relevant nominal input fields for the recommendation.
Nominal Field Inputs are discrete values that can be used as inputs into the classification model. The below “modelImprovement” numbers show the correlation percentage to our predicted target field, in this case “category”. We can see that subcategory is highly correlated to category, by 47%.

Now here is where we have to apply some human logic to the recommended input field output. We’re trying to predict category, however we’re not going to know the subcategory at the time of prediction. Also category typically drives subcategory so these two fields are typically highly correlated. So we should skip subcategory as a potential input to improve the model and look at the other recommended input fields. For example, assignment_group and service_offering both look like potential input fields that we might be able to use to improve the precision of our classification model. You may need to experiment with different combinations of the recommended input fields to get the best precision. I would suggest you make a copy of the original solution definition and add one new input and train that model to see if precision improves.
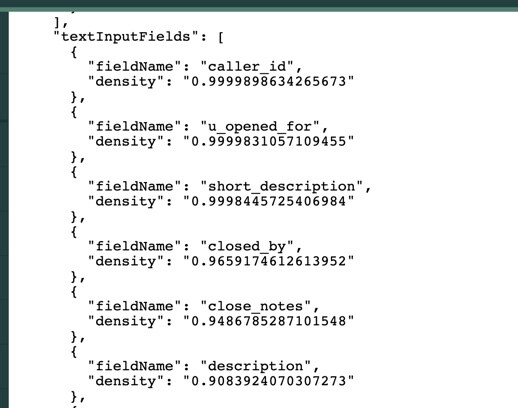
If you scroll to the bottom of the output, you will see textInputFields density.

Density of text input fields, represents the fullness or the sparsity of a potential input text field. Your predictive intelligence models will perform better if the text input fields have a high density of data. In our example above the short_description is a good text input field because it has a density of 99%. We want to avoid any text input fields that have low percentages.
In summary, we just learned about two methods for tuning your classification model. There is a third method that I did not cover, which is using your knowledge of the data to determine which input fields are required and analyzing the data using Performance Analytics or reporting.
Again for reference the document for using the Machine Learning APIs here:
Best Regards, Lener
- 17,350 Views
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hello Lener Pacania,
Thank you so much for your Explanation.
Regards,
Harsha.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
My peer, Chris Steinke (author of the great NPS PA article), also shared how he changed the filter criteria for the PredictabiltyEstimate. You add the filter criteria in the encoded query, here is what he used. -Lener
'encodedQuery': 'active=false^contact_type!=event^sys_created_onONLast 12 months@javascript:gs.beginningOfLast12Months()@javascript:gs.endOfLast12Months()'
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Step 2 - unique name for estimation object can be found by going to
filter navigator > ml_solution.LIST

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
I've included Predictability Estimate scripts if you'd like to find the input field correlations to Assignment Group. Paste and run this code from Filter Navigator > Background Scripts.
Step 1 - Create the Predictability Estimate Object for Assignment Group.
By using the ML API() we are creating the Predictability Estimate Object to find the highly correlated fields that will help us predict Assignment group. This may take 30minutes+ to run. You can check the status by going to Filter Navigator > ml_solution.list
I've called mine "TS22 AG Predictability Estimation Object", in the label field. Change to your desired name.
//Create PredictibilityEstimate for the Assignment Group
//Submit Training Job for PredictabilityEstimate
try {
var myIncidentData = new sn_ml.DatasetDefinition({
'tableName' : 'incident',
'encodedQuery' : 'short_descriptionISNOTEMPTY'
});
var eligibleFields = JSON.parse(myIncidentData.getEligibleFields('classification'));
var myEstimate = new sn_ml.PredictabilityEstimate({
'label': "TS22 PredictibilityEstimate AG",
'dataset' : myIncidentData,
'inputFieldNames':eligibleFields['eligibleInputFieldNames'],
'predictedFieldName': 'assignment_group'
});
var myEstimateName = sn_ml.PredictabilityEstimateStore.add(myEstimate);
var myEstimateVersion = myEstimate.submitTrainingJob();
var trainingStatus = myEstimateVersion.getStatus();
gs.print(JSON.stringify(JSON.parse(trainingStatus), null, 2));
} catch(ex) {
gs.print(ex.message);
}Step2 - Retrieve the Predictability Estimate Object for assignment group
This will provide the list of highly correlated fields as well as text densities on all potential input fields.
Once step 1 is complete, paste and run this code from Filter Navigator > Background Scripts.
//Get suggested input fields after training is complete
//Find the estimate name from the ml_solution.list
try {
var estimateName = 'ml_x_snc_global_global_ts22_predictibilityestimate_ag';
var estimateSolution = sn_ml.PredictabilityEstimateStore.get(estimateName);
var estimateResults = JSON.parse(estimateSolution.getActiveVersion().getResults());
gs.print(JSON.stringify(estimateResults, null, 2));
} catch(ex) {
gs.print(ex.message);
}
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hello,
I am trying to create a Classification Solution in Predictive Intelligence. However while giving the filter conditions, matching records are showing 0 although in the incident table there are around 3 lakh records for the same filter condition.
What can be the issue?
Also after running the model, I am getting a solution accuracy percentage under solution statisctics related list as 0.
Can someone help me in these 2 issues?
Regards,
Dipanjan Saha
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi @Lener Pacania1
How to create GUSE encoder in ML solution parameter.
issue is system shows other language articles based on semantic similarity matching in the training dataset. I need to show only the records in related list in KB related list widget on portal as per the language selected on portal by logged in user.
Thanks in advance.