- Post History
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
on 12-21-2020 06:00 AM
The Predictive Intelligence similarity framework can be used to help agents resolve incidents/cases faster, predict major issues before they occur, and identify gaps in your knowledge base.
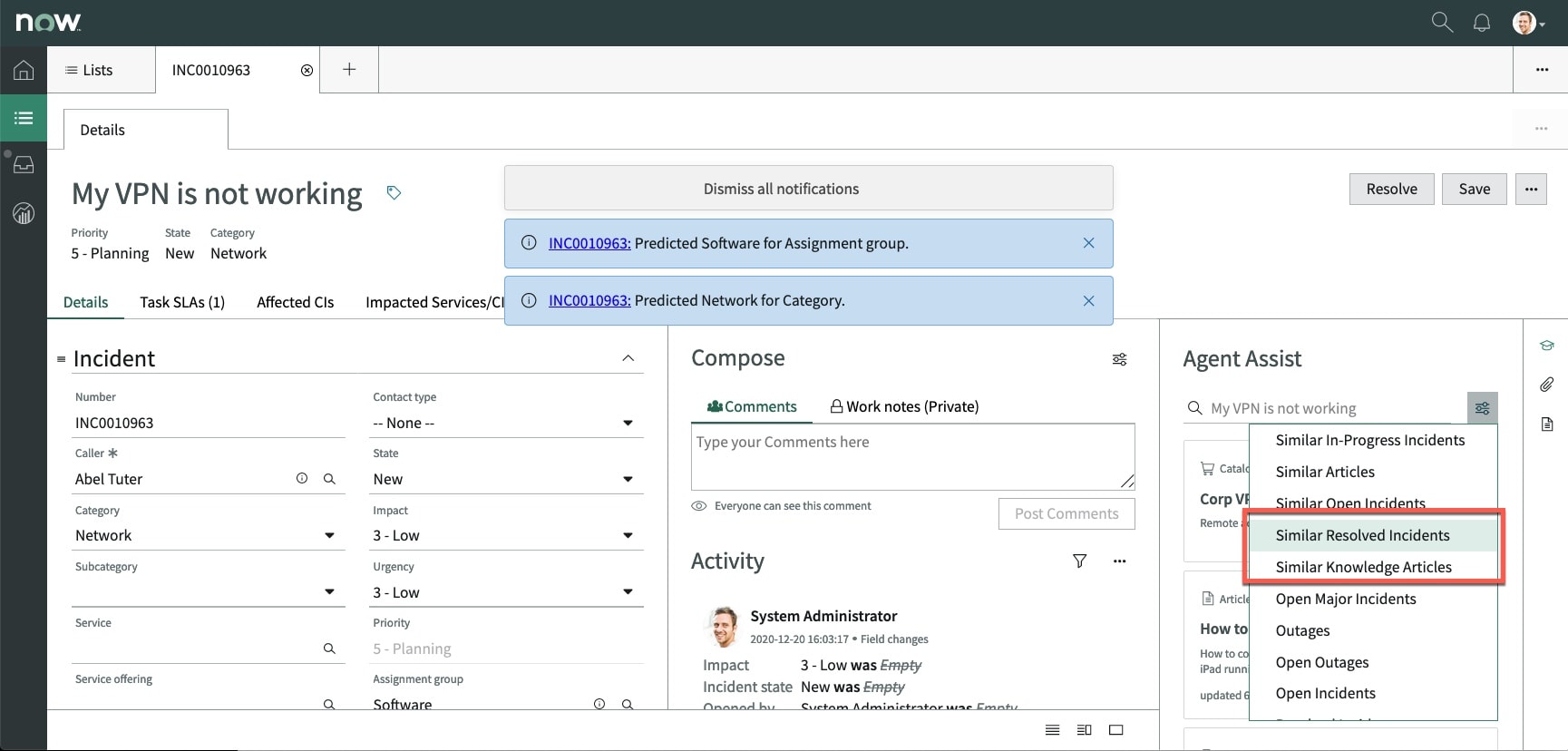
In the below example(fig1) similarity does the work of predicting which resolved incidents might help the agent solve the below problem faster. The agent can select “Similar Resolved Incidents” in Agent Assist and select “Similar Resolved Incidents” from the agent assist drop down menu.
(fig1)

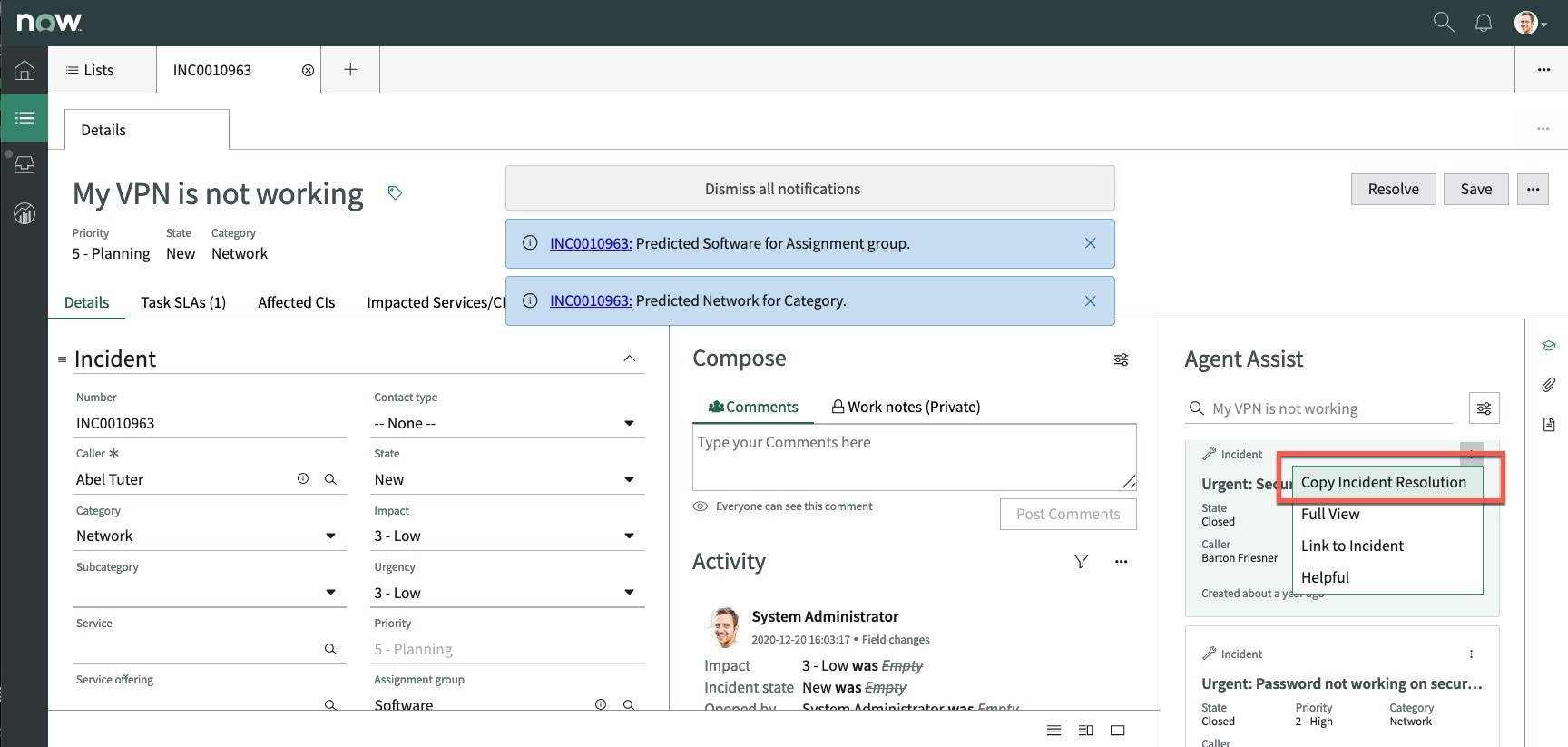
The agent can then review a list of predicted resolved incidents that are similar to the current open incident. If there is similar resolved incident that has a relevant solution the agent can copy that resolution to the open incident (fig2). Similarity reduces the research time required to solve the open incident.
(fig2)

This looks great. So what’s the problem?
Depending on your data the out of the box similarity solution definitions for incident/case may not return ideal similarity results. I’ll start with the problem then provide two quick tuning tips that may help you improve your similarity prediction results.
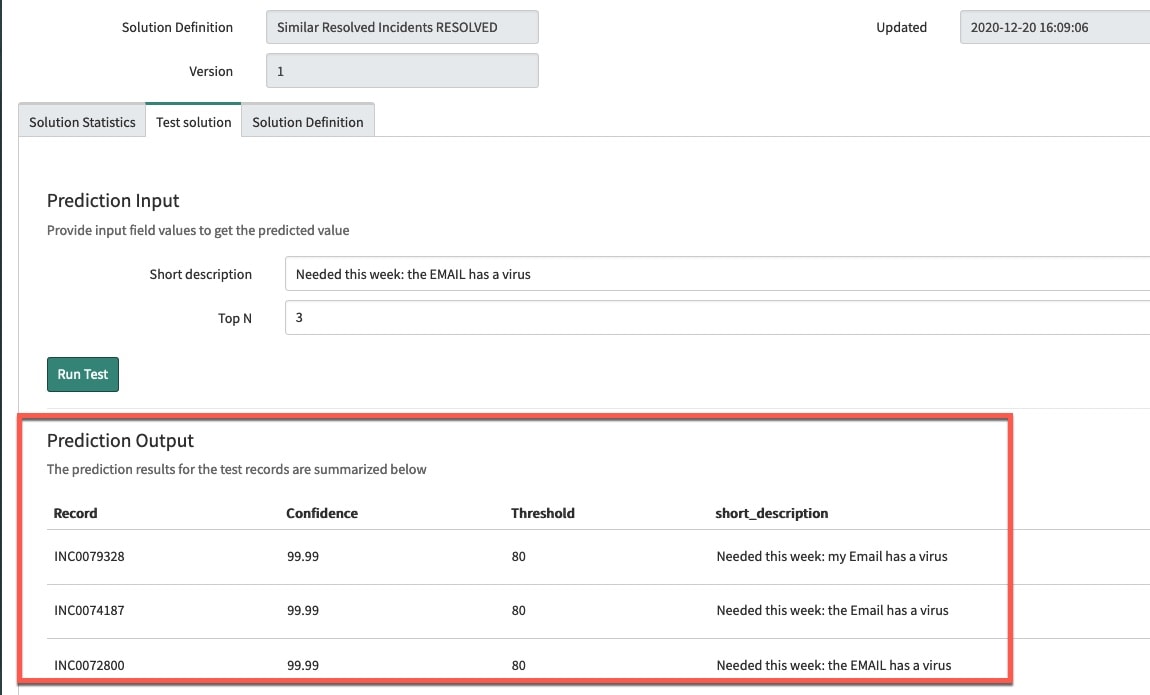
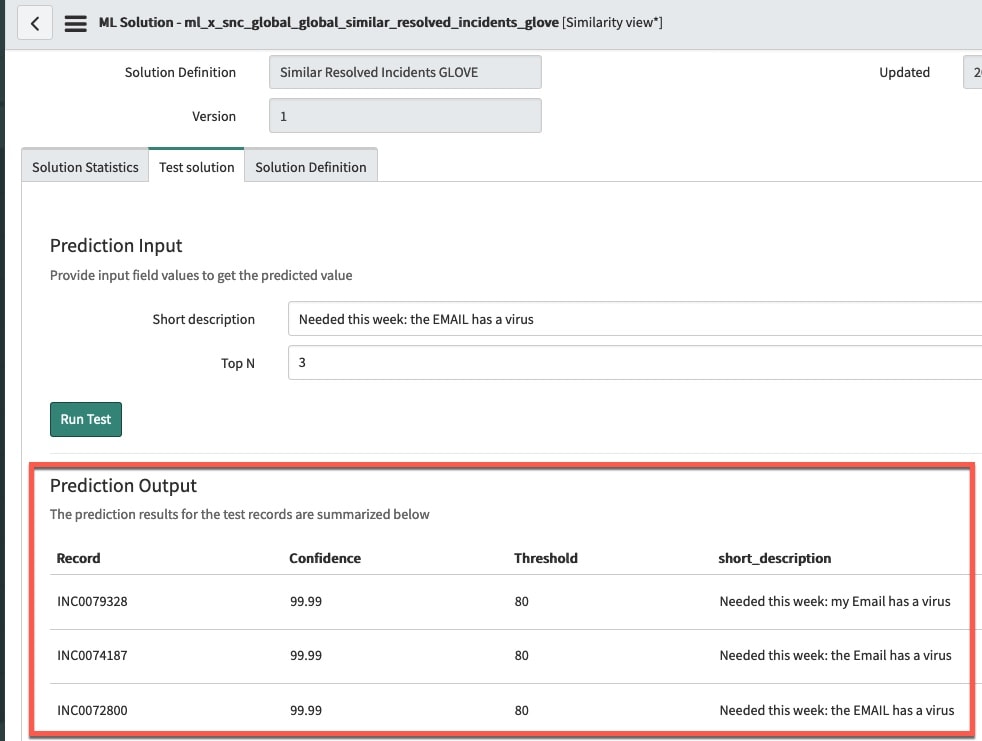
Let’s test the out of the box “Similar Resolved Incidents” solution definition. We’ll enter “Needed this week: the EMAIL has a virus” as short description in the test solution tab of the trained solution.
I see that with almost 100% confidence the similarity solution returns the following Top 3 Prediction Outputs (fig3):
(fig3)

None of the incidents in the predictions output look like they may help with the specific “Needed this week: the EMAIL has a virus” issue that I am having. So what tuning approaches can we take to improve the prediction?
Tuning your Similarity Solutions
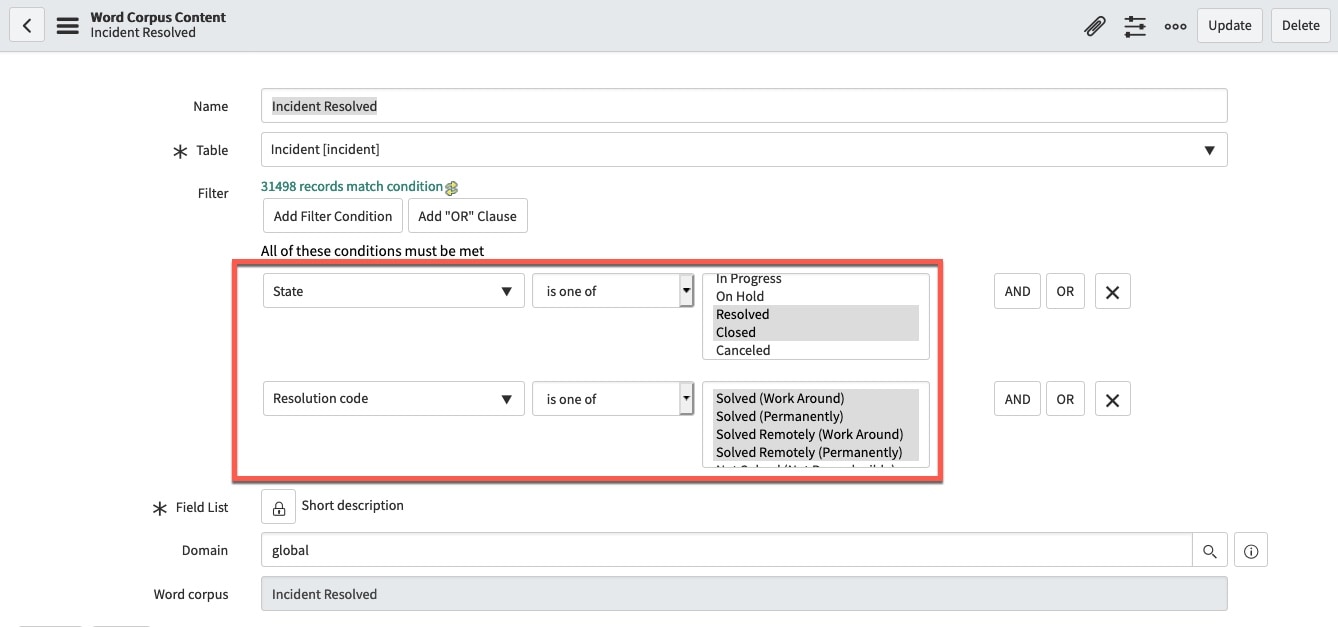
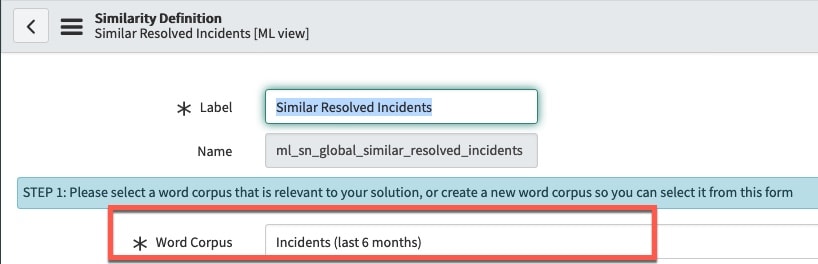
The problem is that our word corpus for Similar Resolved Incidents does not provide the right type of data to effectively train our model. The word corpus acts as the vocabulary to aid in the prediction. We are trying to predict Similar Resolved Incidents, but the selected word corpus is Incidents (last 6 months), which may or may not have resolved incidents (fig4).
(fig4)

Tuning Tip#1 – Use a focused Paragraph Vector word corpus
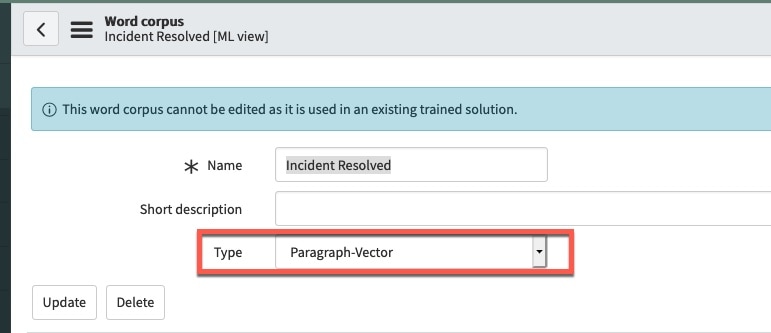
We can get often get a better prediction result if we use a focused word corpus that matches the filter of our solution definition. Let’s create a new word corpus called “Incident Resolved” by going to filter navigator > predictive intelligence > word corpus > new. Name this word corpus “Incident Resolved” and select “Paragraph-Vector” as type. Paragraph-Vector is also known as doc2vec and is based on the word2vec algorithm which generates our numerical vectors embeddings for use by the similarity algorithm (fig5a).
(fig5a)

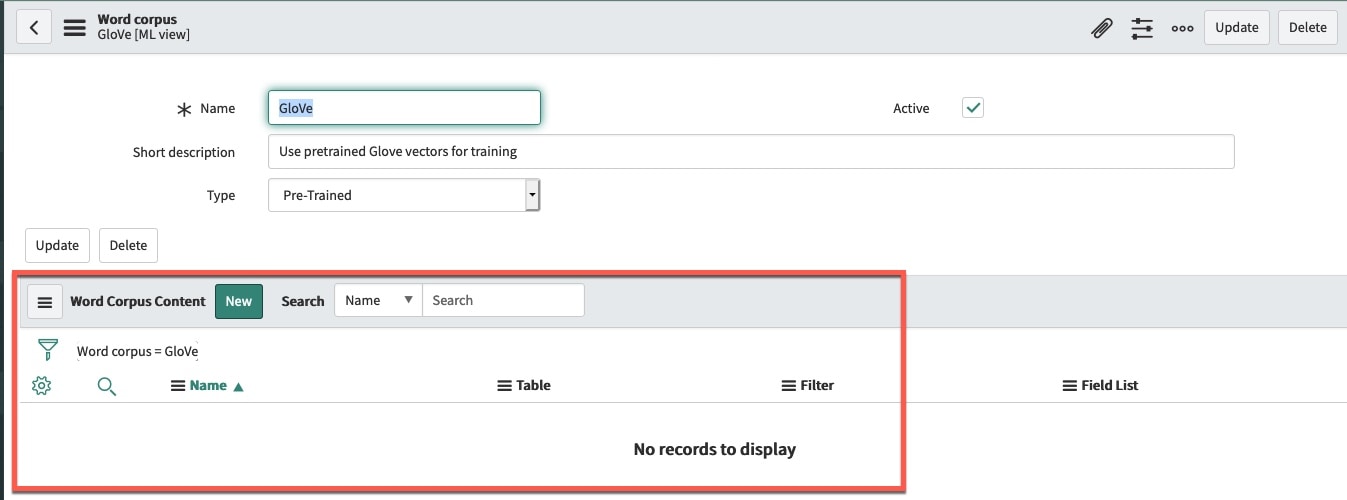
Now we need to define a word corpus content that is focused only on Resolved Incidents (fig5b) vs the default Incidents 6 months.
(fig5b)

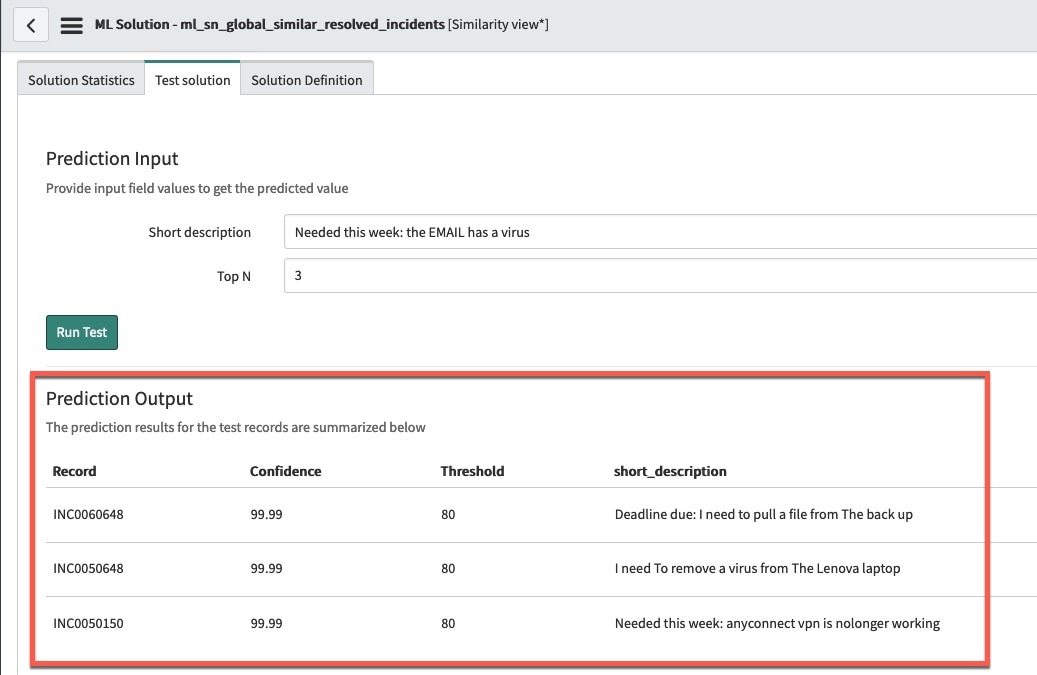
After switching the word corpus to “Incident Resolved” and re-training our testing results are greatly improved (see fig6).
(fig6)

*Note – in my example I duplicated the Similar Resolved Incidents solution definition and switched the word corpus and re-trained so I could compare the results without changing the original out of the box solution definition.
Tuning Tip#2 – Pre-trained word corpus
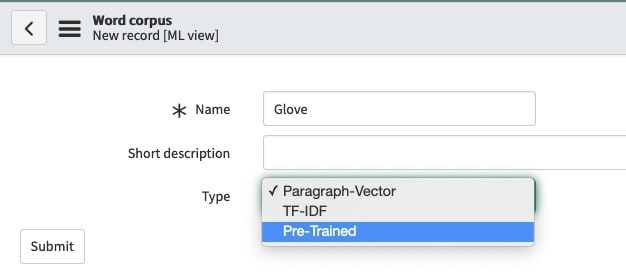
In Paris we support the pre-trained global vector word corpus (gloVe). To use the pre-trained word corpus go to filter navigator > predictive intelligence word corpus > new.
In the word corpus type drop down switch from the default Paragraph-Vector to “Pre-Trained” and hit submit (fig7).
(fig7)

When using a pre-trained corpus you should not define a “Word Corpus Content” (fig8) as we will be using the pre-trained corpus.
(fig8)

Let’s test again with the same Recommend Resolved Incidents solution definition and the same short description “Needed this week: the EMAIL has a virus”. In this test we will switch the word corpus to our new Glove pre-trained word corpus and re-train the solution definition. For this data set our results(fig9) look very similar to the tuning approach that we took in Tip#1.
(fig9)

Both focused paragraph-vector and pre-trained word corpus performed better than the out of the box incidents (6month) word corpus. So when do you use a focused Paragraph-Vector or pre-trained corpus?
As a rule of thumb if your similarity table (records you are comparing) has a lot of domain specific vocabulary (like Paris has a different meaning for ServiceNow), you need to train your own focused word corpus via Paragraph-Vector. ServiceNow uses gloVe as a pre-trained word corpus. GloVe is trained with a huge Internet corpus. So it is very accurate for general similarity problems. There is also a third word corpus option which is TF-IDF. TF-IDF has been known to sometimes return better prediction results for records that have machine-generated content, such as alerts and error messages for log files. You have to experiment and see which word corpus approach might work the best for your data.
If you are new to Similarity you can go to nowlearning.service-now.com and enroll in the “Accelerate Incident Resolution with Predictive Intelligence” course.
- 70,640 Views
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Thanks for the wonderful and helpful information, much appreciated! I tried the same in my client instance, but the issue is that I'm not able to see a similar option in SOW under Agent Assist. Is there something I'm missing here? However, this option is available under the Agent Workspace. How can I fix this?

- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Along with the above, I created the Classification and Similarity solutions, but they are not working on the native view, neither in the Agent Workspace nor in the SOW. However, when I update and test the solution in the staging environment, I can see the results there. Am I missing some configuration for this?

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Thanks for sharing! Using a smaller word list for resolved incidents sounds really helpful. I’ll give it a try.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Since Washington, we introduced the Workflow capabilities which no longer require a Word Corpus. This article was intended for pre-Washington non-Workflow capabilities.
Regards,
Brian
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi,
How can I connect the Similar Incident model I've created to my Incident form using workflows? I can't seem to find any KB articles explaining this or showing the steps.
@Brian Bakker @Lener Pacania1
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
there is a similarity model that works on getting results for "recommended for you" Widget .
Has anyone updated it to switch it from employee to HR profile?
- « Previous
-
- 1
- 2
- Next »