- Post History
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
on 12-21-2020 06:00 AM
The Predictive Intelligence similarity framework can be used to help agents resolve incidents/cases faster, predict major issues before they occur, and identify gaps in your knowledge base.
In the below example(fig1) similarity does the work of predicting which resolved incidents might help the agent solve the below problem faster. The agent can select “Similar Resolved Incidents” in Agent Assist and select “Similar Resolved Incidents” from the agent assist drop down menu.
(fig1)

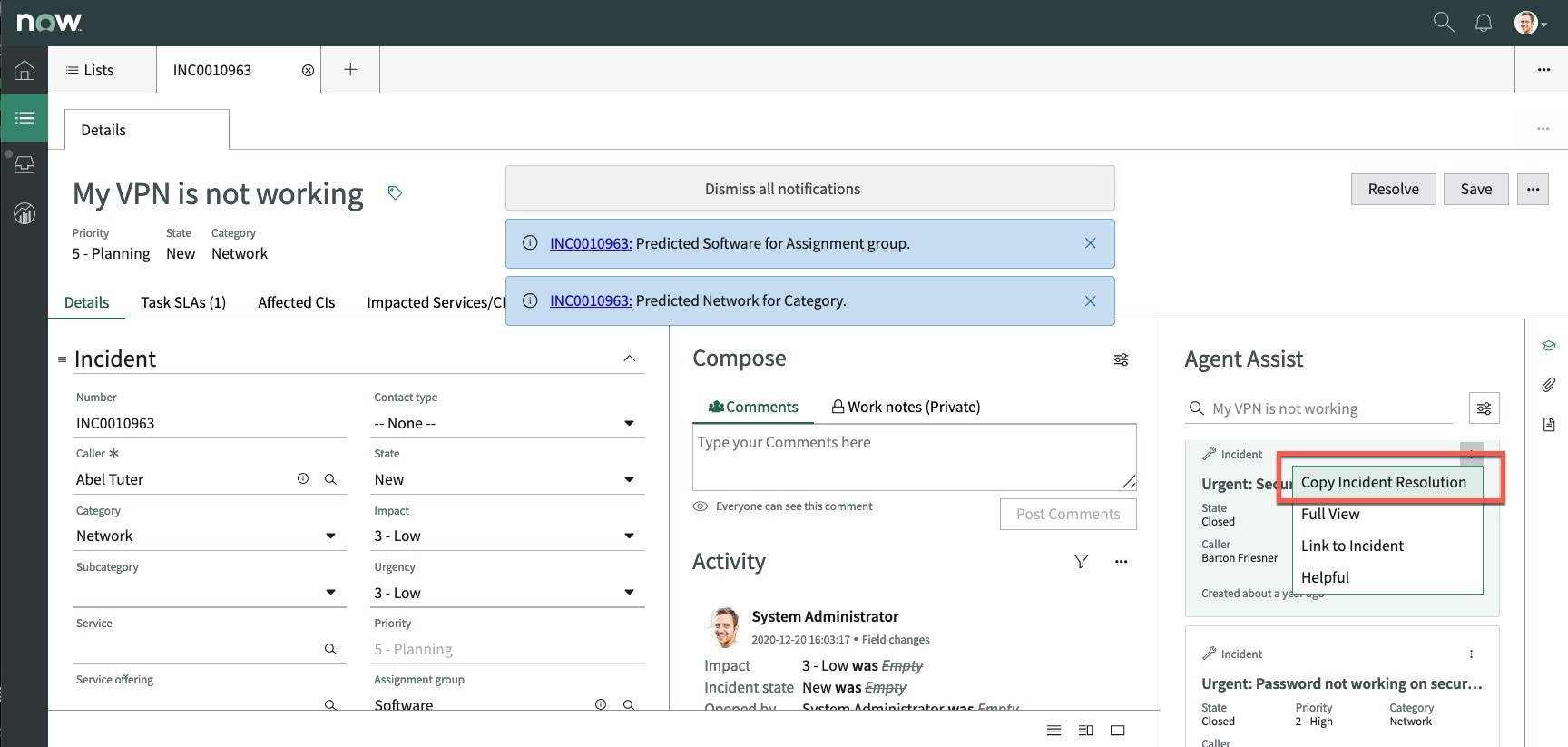
The agent can then review a list of predicted resolved incidents that are similar to the current open incident. If there is similar resolved incident that has a relevant solution the agent can copy that resolution to the open incident (fig2). Similarity reduces the research time required to solve the open incident.
(fig2)

This looks great. So what’s the problem?
Depending on your data the out of the box similarity solution definitions for incident/case may not return ideal similarity results. I’ll start with the problem then provide two quick tuning tips that may help you improve your similarity prediction results.
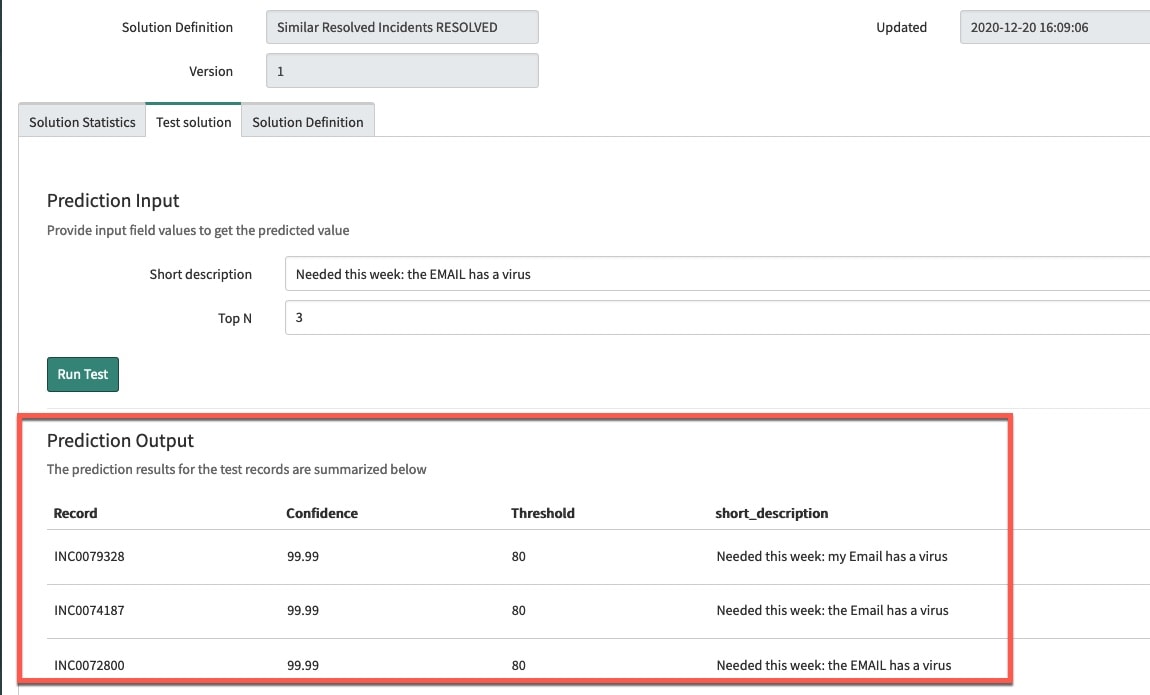
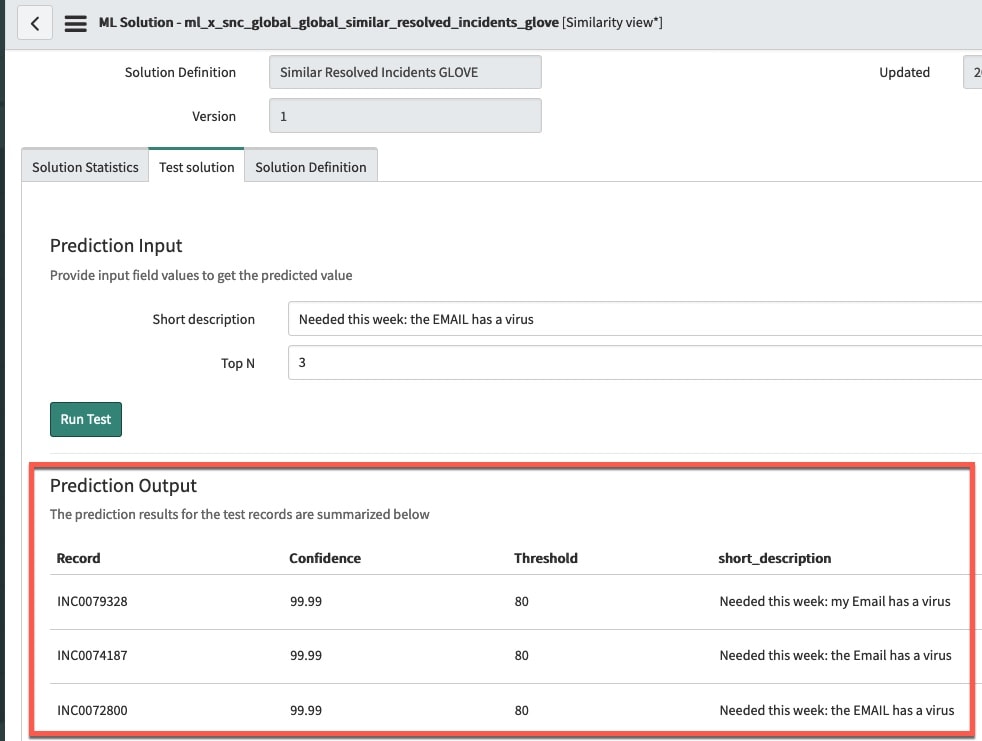
Let’s test the out of the box “Similar Resolved Incidents” solution definition. We’ll enter “Needed this week: the EMAIL has a virus” as short description in the test solution tab of the trained solution.
I see that with almost 100% confidence the similarity solution returns the following Top 3 Prediction Outputs (fig3):
(fig3)

None of the incidents in the predictions output look like they may help with the specific “Needed this week: the EMAIL has a virus” issue that I am having. So what tuning approaches can we take to improve the prediction?
Tuning your Similarity Solutions
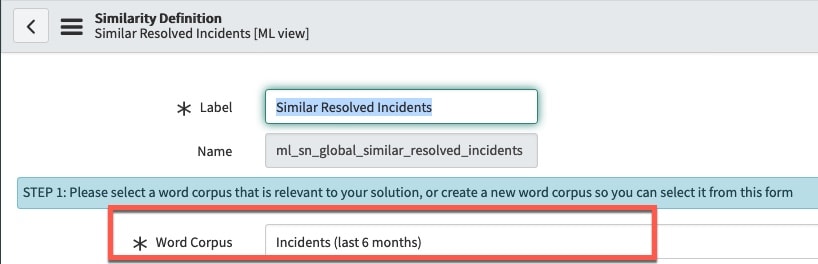
The problem is that our word corpus for Similar Resolved Incidents does not provide the right type of data to effectively train our model. The word corpus acts as the vocabulary to aid in the prediction. We are trying to predict Similar Resolved Incidents, but the selected word corpus is Incidents (last 6 months), which may or may not have resolved incidents (fig4).
(fig4)

Tuning Tip#1 – Use a focused Paragraph Vector word corpus
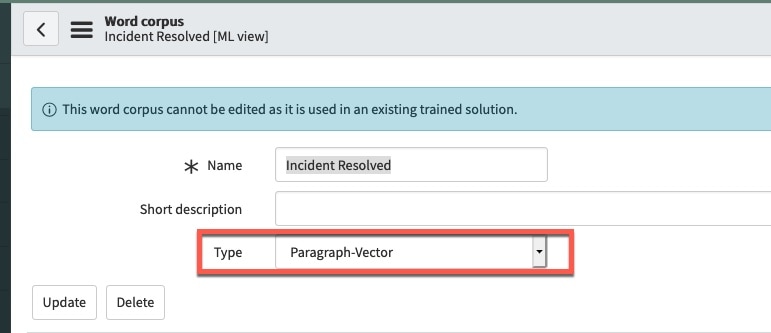
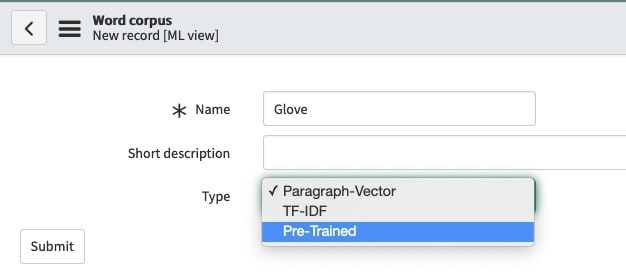
We can get often get a better prediction result if we use a focused word corpus that matches the filter of our solution definition. Let’s create a new word corpus called “Incident Resolved” by going to filter navigator > predictive intelligence > word corpus > new. Name this word corpus “Incident Resolved” and select “Paragraph-Vector” as type. Paragraph-Vector is also known as doc2vec and is based on the word2vec algorithm which generates our numerical vectors embeddings for use by the similarity algorithm (fig5a).
(fig5a)

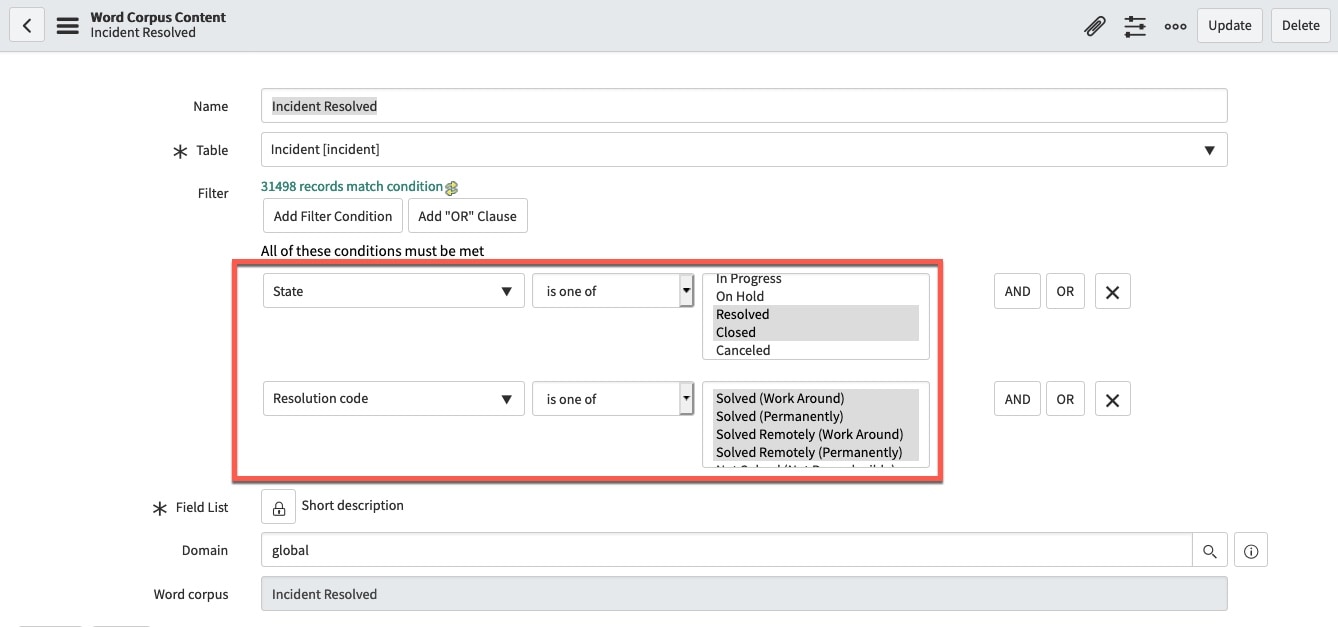
Now we need to define a word corpus content that is focused only on Resolved Incidents (fig5b) vs the default Incidents 6 months.
(fig5b)

After switching the word corpus to “Incident Resolved” and re-training our testing results are greatly improved (see fig6).
(fig6)

*Note – in my example I duplicated the Similar Resolved Incidents solution definition and switched the word corpus and re-trained so I could compare the results without changing the original out of the box solution definition.
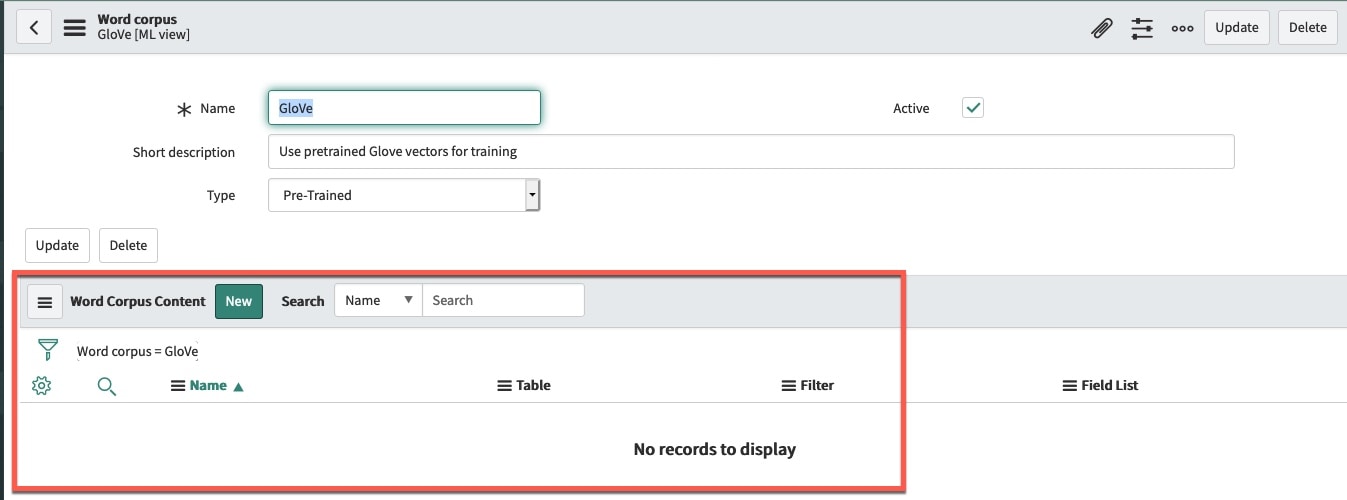
Tuning Tip#2 – Pre-trained word corpus
In Paris we support the pre-trained global vector word corpus (gloVe). To use the pre-trained word corpus go to filter navigator > predictive intelligence word corpus > new.
In the word corpus type drop down switch from the default Paragraph-Vector to “Pre-Trained” and hit submit (fig7).
(fig7)

When using a pre-trained corpus you should not define a “Word Corpus Content” (fig8) as we will be using the pre-trained corpus.
(fig8)

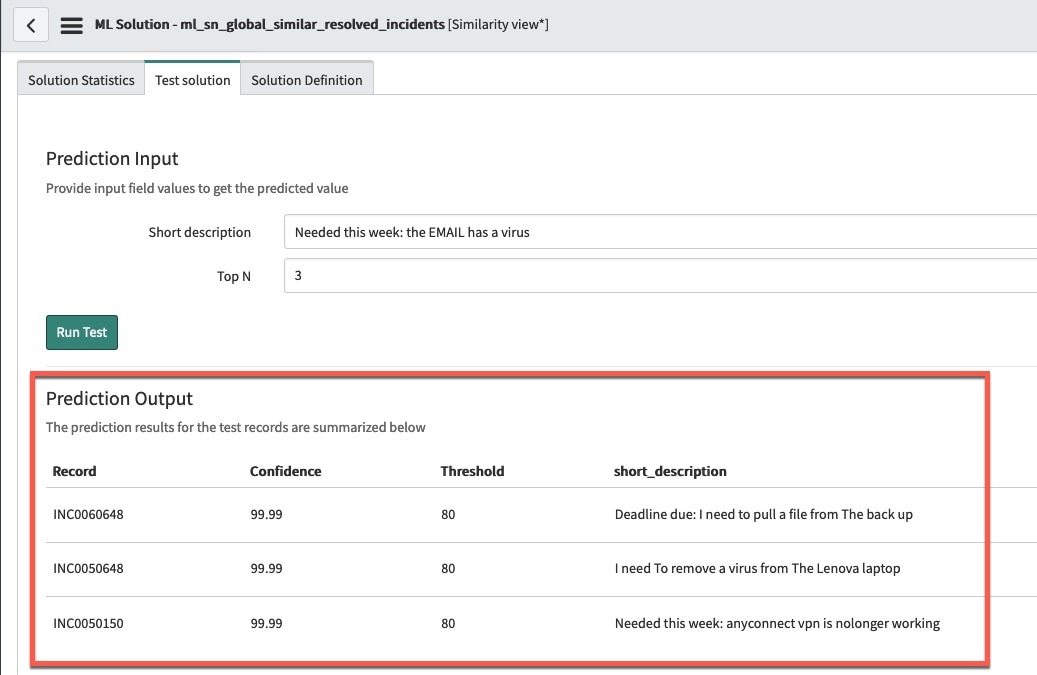
Let’s test again with the same Recommend Resolved Incidents solution definition and the same short description “Needed this week: the EMAIL has a virus”. In this test we will switch the word corpus to our new Glove pre-trained word corpus and re-train the solution definition. For this data set our results(fig9) look very similar to the tuning approach that we took in Tip#1.
(fig9)

Both focused paragraph-vector and pre-trained word corpus performed better than the out of the box incidents (6month) word corpus. So when do you use a focused Paragraph-Vector or pre-trained corpus?
As a rule of thumb if your similarity table (records you are comparing) has a lot of domain specific vocabulary (like Paris has a different meaning for ServiceNow), you need to train your own focused word corpus via Paragraph-Vector. ServiceNow uses gloVe as a pre-trained word corpus. GloVe is trained with a huge Internet corpus. So it is very accurate for general similarity problems. There is also a third word corpus option which is TF-IDF. TF-IDF has been known to sometimes return better prediction results for records that have machine-generated content, such as alerts and error messages for log files. You have to experiment and see which word corpus approach might work the best for your data.
If you are new to Similarity you can go to nowlearning.service-now.com and enroll in the “Accelerate Incident Resolution with Predictive Intelligence” course.
- 70,636 Views
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
I've included a diagram for those interested in more detail around how a word corpus is used. At a high level we are running Natural Language Processing against the text data and converting that text into numeric vectors so we can plug those vectors into the similarity, classification, regression, and clustering algorithms.

- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Lener Pacania, I have read your three great Articles from this serie (part1 to part3), this content is being very useful, as we are starting the implementation of PI in a customer. If you could help me on this question please (sorry if it is not the better way to ask for help about it): we are analysing the out of the box similarity solution definitions for incident (ITSM Pro instance), we will need to change some definitions, e.g.: the processing language of the solution, add the Description field to be compared (the "short_description" will not be enough), among other definitions to be changed.
The best approach is to re-use the out of the box Models (to keep the data provided by those solutions, and to avoid impacts in the Predictive Intelligence Workbench Dashboards), or the best in this case is to duplicate the out of the box Models, inactive the base records and change the definitions in the "duplicated / customized" records?
Thank you so much for all your help!
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi,
If you plan to use the similarity solutions as part of the Agent Assist in Agent Workspace you must not change the names of the out of the box similarity models. The reason is that they are currently configured in a way that if you duplicate the out of the box similarity models you will not be able to access those copies in Agent Assist or in the incident form.
Best practice is to use the out of the box similarity models and leave the names the same. You can change the input and filter criteria and re-train and still use those similarity definitions in Agent Assist or in your incident form.
Hope that helps.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
For those interested in data science the above image shows a vectorization technique called one-hot-encoding. ServiceNow uses advanced vectorization techniques such as Paragraph Vector (aka doc2vec), Glove, and TF-IDF. A word such as "hello" is turned into a vector that looks something like this.
[-0.33712, -0.21691, -0.0066365, -0.41625, -1.2555, -0.028466, -0.72195, -0.52887, 0.0072085, 0.31997, 0.029425, -0.013236, 0.43511, 0.25716, 0.38995, -0.11968, 0.15035, 0.44762, 0.28407, 0.49339, 0.62826, 0.22888, -0.40385, 0.027364, 0.0073679, 0.13995, 0.23346, 0.068122, 0.48422, -0.019578, -0.54751, -0.54983, -0.034091, 0.0080017, -0.43065, -0.018969, -0.08567, -0.81123, -0.2108, 0.37784, -0.35046, 0.13684, -0.55661, 0.16835, -0.22952, -0.16184, 0.67345, -0.46597, -0.031834, -0.26037, -0.17797, 0.019436, 0.10727, 0.66534, -0.34836, 0.047833, 0.1644, 0.14088, 0.19204, -0.35009, 0.26236, 0.17626, -0.31367, 0.11709, 0.20378, 0.61775, 0.49075, -0.07521, -0.11815, 0.18685, 0.40679, 0.28319, -0.1629, 0.038388, 0.43794, 0.088224, 0.59046, -0.053515, 0.038819, 0.18202, -0.27599, 0.39474, -0.20499, 0.17411, ..]
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Lener Pacania, I really appreciate your time and help!
Yes, you are correct, we are planning to use them as part of the Agent Assist in Agent Workspace. That's good to know about it, we will proceed as you recommended.
Just a last question (I promise), as you mentioned the Agent Assist, just to make sure we are understanding properly:
In this Now Support Article: "KB0755924 : How the contextual search works in "Agent intelligence" tab and "agent assist" tab in wo...", I can see there are two different tabs: "Agent intelligence" tab and "Agent Assist" tab, but actually I see only one in the Agent Workspace: Agent Assist tab.
Currently (after install the Predictive Intelligence plugin for Contextual Search), we already see on the same Agent Assist tab, the "Similar" contextual searches (Show Similar Incidents... among others already available). The ML contextual searchs are working together with the base contextual search, so, is that correct to say that we could have only one tab: "Agent Assist", where all the contextual searches are available (it does not depend on they belong to ML or not).
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
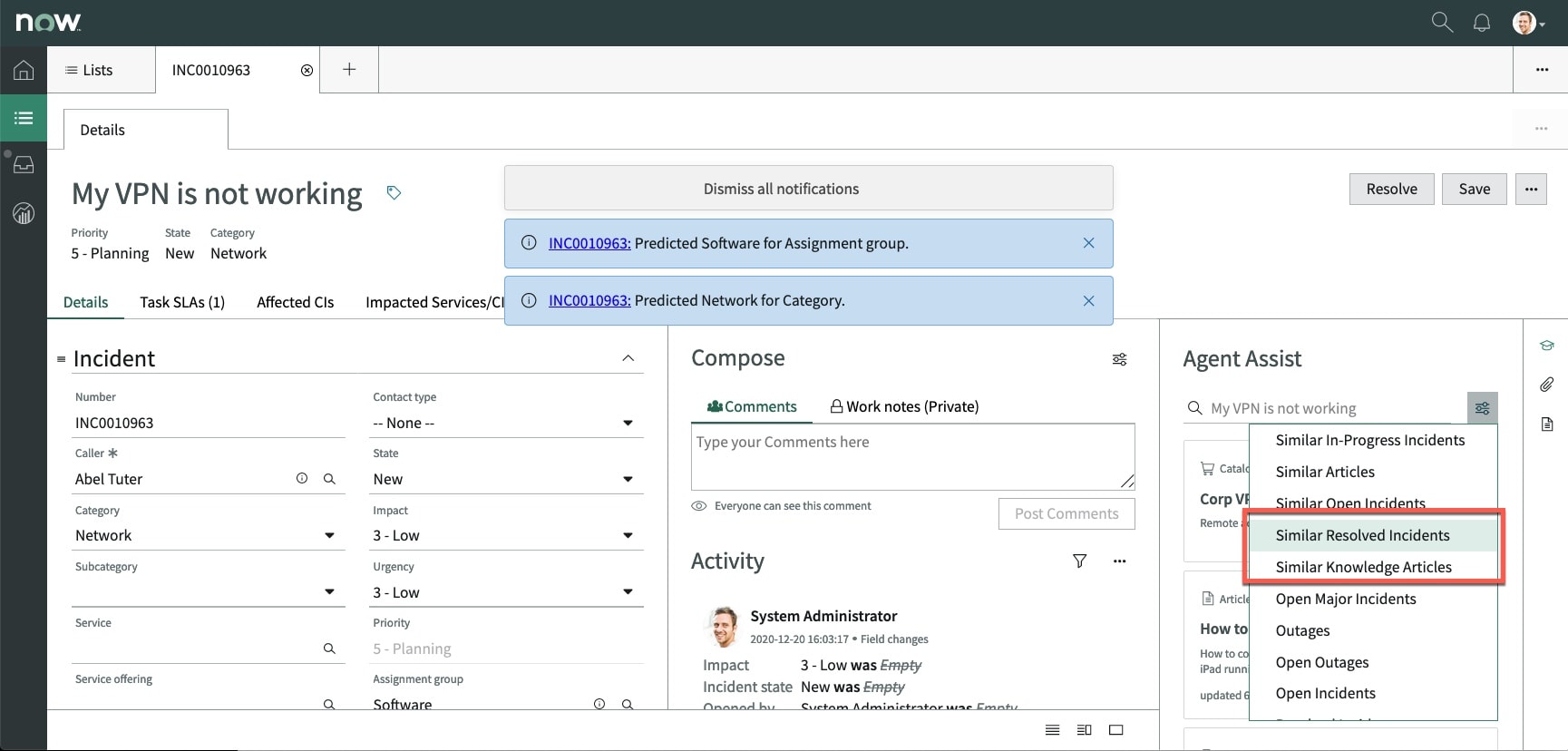
Hi Vibrasil,
The predictive intelligence similarity results are shown under the Agent Assist tab (see the red square below). Does your agent workspace look different?

- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Lener Pacania,
Yes, our Agent Workspace looks the same as yours, I can see Predictive Intelligence Similarity results under the Agent Assist tab. I was in doubt, because in the KB0755924 it seems we would have two tabs... but may be the another tab is related to a older release, it's why I was little confused, if I was not missing to enable something else.
That's good, thank you so much for your time and help, it help us a lot in the beginning of this implementation, I really appreciate that!
Have a good day!
Viviane

- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Vibrasil, looks like you're in good shape. I don't see any extra Agent Workspace tabs in my Quebec or Rome instances. If you run into any issues I would recommend opening a Hi ticket.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hello Lener, We are tying to implement Predictive Intelligence and appreciate your assistance on few queries:
We are planning to use Similarity Framework to identify:
- similar incidents in last 2 to 5 days with threshold of 10 Incidents, If more than 10 Incidents with similar short description/description then propose recommendation on Agent Assist to propose problem ticket.
- similar resolved incidents
Currently I can see 3 Plugins activated,
- Predictive Intelligence ( com.glide.platform_ml)
- Predictive Intelligence - Enhanced UI (com.snc.ml_ui)
- Predictive Intelligence Automated testing framework (com.glide.platform_ml_atf)
I understand we need to install com.snc.contextual_search_ml for Contextual search as well.
Queries:
Do we need to install -
- Predictive Intelligence for Incident Management (com.snc.incident.ml_solution) as well?
- Also Do we need to install Predictive Intelligence Workbench (com.sn_piwb_ml) and Predictive Intelligence Workbench ITSM content (com.sn_piwb_itsm_content) for our requirement and is this Free or Paid?
- What's the difference between "Similar Incidents" and "Similar Open Incidents" Solutions - Is the condition of similar incidents pull all incidents irrespective of state of an incidents vs Similar open incidents pull only open incidents?
- Can we create multiple agent assist recommendations cards specific to each solution and it displays on Agent Assist if there is a match (For example similar Incident card to show how many incidents happened in a week and provide some recommendation and similar open incidents to show only open incidents from 2 days and provide some recommendation)
Thank you in advance for your help on this!!
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Vinay,
Yes you should install the com.snc.incident.ml_solution plugin.
Predictive Intelligence Workbench (PIWB) is part of the ITSM Pro & HRSD Pro SKUs. So if you own either you are entitled to install the PIWB plugin. There are two ways to configure and train a Predictive Intelligence classification model. 1st way is using the classic interface and the 2nd way is to use PIWB. PIWB allows you to easy configure, training, and tune the out of the box solution models for classification. PIWB does not allow you to select advanced settings (it uses the defaults), which may or may not matter depending on the performance of the model. Also PIWB hides the implementation vs you calling the PI models via business rule/Flow Designer/UI Action. Even though you will see similarity in the PIWB interface it will take you to the classic interface to implement similarity.
You can see the difference between similar incidents and similar open incidents by opening the filter of the solution definition and reviewing the criteria. You are correct that the major difference between the two is the state of the incident.
In the current Rome release you can't show custom similarity solutions(i.e. show recommendations for incidents in a week vs 2 days) in Agent assist. You are constrained to what we provided out of the box for similarity.
HTH - Lener
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
I'm working on internal training 2022 training for the technical team at ServiceNow and thought these slides on vectorization would be helpful to our community.


- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Excellent article. Request you to share the links to Part 1 and 2 as well.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Anish, these articles from
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Thank you!
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
We are trying to consolidate all of the old and new PI advanced topics articles from ServiceNow in this course on NowLearning. Gives folks an organized way of finding all the PI advanced topic material.

- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hello Lener,
Thank you for providing the clarification for my earlier query. I have setup a new Similarity definition which is same as OOB Similar Open Incidents.
The word corpus that's attached to the solution contains around 100,000 records from last 6 months.
My Queries are as below:
1) Since we are trying to find similar open incidents, My condition on left table is to pull Incidents only that are open so incident count is around 1500 records. Does this solution work as it has only few records to learn or it takes the data from word corpus that's attached? Have read minimum 30K records needed.
Below is the condition for Left Side Table-
- State IS NOT ONE OF RESOLVED, CLOSED
- Created at or after Last 6months
2) From which table we are comparing and retrieving the similar results? Is it Left Table to Test Table or vice versa? In our case End User submits only Short Description and we would like that to compare with Description and Short Description of the current open incidents, so in this case Left Table pulls existing open incidents and compares incoming incident short description from Test Table?
3) Does "Similar Open Incidents" Searcher from Agent Assist Contextual Search works for newly created solution or do we have to use/modify existing "Similar Open Incidents" ML Solution Definition only?
Thank you
Vinay
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Vinay,
My input to your questions below:
1) Since we are trying to find similar open incidents, My condition on left table is to pull Incidents only that are open so incident count is around 1500 records. Does this solution work as it has only few records to learn or it takes the data from word corpus that's attached? Have read minimum 30K records needed.
[Lener] Yes, your PI solution definition will train with 1500 records, you need to double check the sys_properties > glide.platform_ml.api.min_similarity_window_records and make sure the value is 1500 or less. The 30k record recommendation is a guideline based on internal testing. Similarity is a statistical comparison measuring the cosine similarity between two vectors. So theoretically you are not training anything, you're converting the incident open short descriptions on the left table to what you defined on the right into word vectors. I've done this with as little as 100 records on the left table with decent results.
2) From which table we are comparing and retrieving the similar results? Is it Left Table to Test Table or vice versa? In our case End User submits only Short Description and we would like that to compare with Description and Short Description of the current open incidents, so in this case Left Table pulls existing open incidents and compares incoming incident short description from Test Table?
[Lener] The right table compares it's results to what is on the left. You can see this working in the trained solution under the related links similarity examples. You've probably noticed you can only put a filter condition on the left table. So how this works OOTB with similar resolved incidents is that the left table pulls all the resolved incidents (using the condition filter) as the comparison set to all the the incoming incidents on the right. As of Rome you can't put a filter on the right table, if you do need to restrict the right table you would need to use a database view.
3) Does "Similar Open Incidents" Searcher from Agent Assist Contextual Search works for newly created solution or do we have to use/modify existing "Similar Open Incidents" ML Solution Definition only?
[Lener] No the agent assist only works for the OOTB similarity solutions. Agent Assist is using what is defined in the contextual search>additional search sources. You will see you can't add new search resources. So my advice to customers is to modify the existing OOTB similarity solutions, keep the name the same but modify the inputs and the conditional filters.
HTH -Lener
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Thank you Lener for quick response, This was very much helpful.
Best Regards
Vinay
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hello Lener,
Do we have any OOB dashboard to measure the Similarity framework prediction results and monitor business value of it? I could Prediction Results Report in Classification but don't know if there is any dashboard to measure for Similarity framework solutions and also other KPI dashboard if any, thanks
Best Regards
Vinay
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Vinay, apologize for the delay in responding to you I was out on PTO all last week.
The OOTB PA dashboard ( Predictive Intelligence > Prediction Results Report) does not collect data on similarity precision. The data collectors and breakdowns only collect for classification.
If you want to also include similarity metrics you can try a couple of things:
1. You can modify the Prediction Results Report PA dashboard and add an indicator and breakdown to include the similarity precision input stored in the ml_predictor_results table.

2. If you are just trying to gauge the effectiveness of your similarity model you can go to a trained similarity solution and click on similarity examples to see how well the similarity model is doing, I normally focus on records with a confidence percentage less than the default threshold or less than 80%.

HTH -Lener
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hello Lener,
Thanks for all your help, I quickly wanted to check on "Similar Open Incidents" solution, It seems its not displaying the similar open incidents that are created newly but older incidents does show up, I tried creating similar descriptive content as well but no luck, It was working fine earlier.
I thought it could be due to network issue and have re-trained it couple of times and refreshed it as well. Update Frequency was set to 15min and changed to 30min and then 15min back. Is there anything else that need to be checked? thanks
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Trouble Shooting Similarity - Reduce the Similarity Threshold
There are a number of things that can impact the similarity prediction. This article was about how the word corpus (used to transform text into numbers) can impacts similarity results. Another common factor is the Similarity Threshold.
The similarity threshold controls whether a similarity prediction is displayed in Agent Assist. If you find your similarity solution definition predictions are not displaying in Agent Assist try lowering the threshold, in this case (fig1) I switch from the default 80 and lower it down to 40 and SAVE the form. No need to re-train. Agent Assist should start showing results with the lower threshold.

figure 1 - change the similarity threshold
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Lenner,
I have trained the similarity solution for similar resolved incidents and have the agent workbench as well however i am not getting the Similar resolved incidents option in agent assist. can you help?


- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Gunashekar,
In order to see the OOTB similarity models in Agent Assist they need to be listed as an additional resource via the all > contextual search > additional resources. They should be listed OOTB. Do you see the below? If not I would repair the PI Plugin and make sure your contextual search plugins are installed. HTH-Lener

- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Lener,
I see only below models in my contextual search> additional resources. However i am not able to see even the Similar knowledge articles in my agent workspace. Is there any way i can add the solutions into additional resources.

- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Gunashekar,
So that's concerns me that you don't see the OOTB similarity models in the additional search sources for incident. You should also see similar resolved incidents, similar open incidents, similar incidents per my original reply.
Did you double check the setup steps in here?
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Lener,
I have a question about re-training a Word Corpus. We have a large environment with many classification models. When I check the "updated" time stamp of a Word Corpus it shows they never get updated after creation.
We have the problem that some models don't preform as good as they did a year ago. And when we create a new Word Corpus the recall rate is much better. I remember re-training them is set to 180 days but that does not seem to work. Is there any way to force re-training Word Corpuses?
Thanks and best regards
Martin
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hello @Martin Schinck,
The system property is [glide.wordvector.upgrade_time_frame], which by default is set to 180 days. To force training of the Word Corpus, you set the value of this system property to 0, which will train the Word Corpus every time you train a solution linked to the Word Corpus. You will find the trained Word Corpus artifacts in the [ml_model_artifact] table, where the Word Corpus field is NOT EMPTY. This is a referenced field to the Word Corpus records.
In Vancouver release onwards, a Word Corpus is no longer required for Classification solutions. Today we use GloVe/PV/TF-IDF embeddings for the Word Corpus, but in Vancouver, we will introduce the pre-trained Word Corpus based on Google Universal Sentence Encoder (GUSE). In our tests, we saw a 5% increase in the accuracy when using GUSE. So, if the Word Corpus does not exist, it will default to GUSE in Vancouver.
I hope this helps.
Regards,
Brian
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hello Brian,
thank you for the information and the system property name. But I still wonder why the WC do not re-train as per the set 180 days.
It is good news that you use the GUSE corpus when there is non. The only concern I have in this case is that company lingo is not considered and I am not sure about other languages than english.
Thanks & best reagrds
Martin
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hello Brian,
I just tried your solution but the word corpus of the re-trained solution still shows that it was updated 10 months ago. Any ideas?
Thanks & best reagrds
Martin
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Sorry I was wrong. Your solution worked as expected.
Thank you.
Martin
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Great to hear it work Martin. @Brian thanks for jumping in on PTO today. Was going to say yes it's probably the [glide.wordvector.upgrade_time_frame] default only training once every 6 months.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Sorry Brian and Lener,
I got confused with the different environments we run. Unfortunatelly it did not work. The updated-time stamp in the Word Corpus is still 10 months ago.
best regards
Martin
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
I checked my instance, and as per the screenshot, you see it has trained the "Articles and Incidents" Word Corpus 3 times, by checking the [sys_created_on] date for the Word Corpus in table [ml_model_artifact]. However, I calculated that the Word Corpus is trained every 210 days, and not 180 days, as per the system property [glide.wordvector.upgrade_time_frame]. The actual Word Corpus record in table [ml_word_vector_corpus] is not updated when it is retrained, so you can only check via table [ml_model_artifact], if the Word Corpus has been retrained with a new version in the Word Corpus field, as shown below -

I hope this helps.
Regards,
Brian
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
The solution is set to train every 30 days, and this is added to the default 180 days in the system property [glide.wordvector.upgrade_time_frame] to make the Word Corpus actually train every 210 days. If you set the system property [glide.wordvector.upgrade_time_frame] to 179 days, then it will train the Word Corpus every 180 days based on the training frequency "Every 30 days, or every 60 days, or every 90 days, or every 180 days".
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Thank you very much Brian. Now it is clear. We have successfully tried it.
I could not find this information in a KB article. Not sure if this might be worth to write.
Thanks again and best regards
Martin
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hello,
I'm trying to understand the difference between training frequency and update frequency in the similarity definition.
If, for example, I train the similarity model just once and have an update frequency of 15 minutes, does that mean the vocabulary in a new record will not get vectorized?
What's the advantage of retraining more often versus having a more frequent updates?
Thank you
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Update Frequency is how often you want to refresh the data you use to retrieve your similarity results.
For example, if you have incident records that are open, you may want to select an update frequency of Every 15 minutes, as new incidents typically occur frequently throughout the day. This frequency may increase the likelihood that newly opened records are included in the refresh and hence are returned in the prediction results when the Similarity Solutions is invoked. However, if your solution uses KB Knowledge article records, which are typically not created often, you may want to choose a less frequent update frequency such as Every 1 day.
These updates ensures your Similarity solutions are refreshed without having to train the whole solution again to ensure any new records that meet the criteria are returned in the prediction results or any old records that no longer meet the criteria are removed from the prediction results.
Training Frequency is how often the solution is retrained based on the training dataset defined in the solution definition, and as it will train all the data again, it takes longer to complete. We generally advice to train every 30 days for models that are used often and have high throughput, and less frequently for models that are used less often and have a low throughout.
Training and Updates are two separate actions, and you should base the Update Frequency on how often records get created for the solution and how often these solutions are invoked by your users. You can check how often these Similarity solutions are invoked via the [ml_predictor_results] table.
Hope this helps.
Regards,
Brian
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Is the similarity definition taking of domain separation?
because I don't want to recommend cross-domain cases. 😊
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Yes. Our documentation Domain separation and Predictive Intelligence covers this. For Similarity prediction performance issues, you should review KB1117974: [Similarity] - Infrequently used similarity solutions with high update frequency cause slow performance when invoked, such as opening [em_alert] record or can throw a Malformed URL error when predicting, as this performance issue is frequently reported, especially in a PROD instances with many application nodes.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content

- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Similarity solutions are designed to collect and compare text in your existing records to new similar records. If you want to compare similar cases created by the same account, then you would add Account.Name as an Input and Test Fields. Therefore, the Input/Test fields are determined by your business requirements for the Similarity solution you are creating.
Hope this helps.
Regards,
Brian
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
@Brian Bakker I have trained OOTB similarity solution for Similar resolved incidents. Also I have this in my additional resources but still I don't see similar resolved incidents in my agent assist. Why don't I see similar resolved incidents?


- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
@shegupta06 Did you find any solution for this, I am facing the same issue.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi @Lener Pacania1 , Hope you're doing good.
Thank you so so much for the valueble information for the people who are new to PD.
I Just want to ask you so basic information. Recently we had a thought of implementing PD in our instance.
We installed all plugin's related to PD.
I Created on classification as well as similarity solution and trained by using OOB steps. I seen results in Solutions (Under 'TEST' option). But not in incident table.
My Questions: 1. Without Agent workspace, similar incidents and classified incidents will not visible?
2. If Visible, where it is? I didn't see any option in Incident form (for Classification solution also, it's not populating data).
3. From Where can we get started for complete implementation for PD in our instance?
I knew these were basic questions): 😞 , But please help me with your explanation. It will help lot of people who started PD recently.
Thanks in Advance) :):
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi saibhaskarc,
You can access the PI models through the UI16 interface in the following ways:
1. The OOTB similarity models can be accessed via related search (see below). This is done through add'l search context.
2. The classification models would need to be called through a UI Action, Business Rule (using ML API code) or the recommendations framework. -lener

- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi @Lener Pacania1 ,
Thank you so much for your response.

I didn't see any other options than this...
and, please let us know, where can we get complete details for PI to implement all functionalities and called from different tables. Lot of people had this question.
For classification, please share some knowledge to get details to call from business rules and UI actions?
Thanks in Advance.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi,
Interesting articles, thank you.
I would like to know if the Word Corpus is used anymore with Xanadu?
Best regards
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
As of the Washington the majority of OOTB ITSM, HR, CSM predictive intelligence solutions use the pre-trained GUSE word corpus for classification, similarity, and clustering. We made this change as we found quality is good when using GUSE vs a custom defined word corpus. I've not sunsetted this the article as it's still relevant to customers who have trained PI solutions pre-Washington and there are other solutions such as SPM Clustering that still use a customer defined word corpus. You can search the ServiceNow docs for "word corpus" and you will see which solutions still use a custom defined word corpus. HTH -lener
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi @Lener Pacania1 i've installed all the plugins that are related to PI in ITSM Pro+, but i don't see the Similarity models in the agent assist yet.

Even though i can see then in the Search Resources (Additional Resource) table:

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
List of Plugins installed:
Did i missed something?