











vNick

ServiceNow Employee
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
11-01-2018
11:59 AM
Management guru Peter Drucker noted that "you can't manage what you can't measure". I'm going to make a bold statement and say that every customer using the CMDB is struggling, or has struggled in the past, to operationalize the data, and this is most commonly attributed to a lack of easy visibility and control over metrics surrounding CMDB health. Whether using it for standard IPC (incident, problem, change) processes, or for other platform functions like IT Business Management or Security Operations, the CMDB is a valuable source of data for understanding your IT operating estate. At the same time, this valuable source of data can also make platform users pull their hair out trying to keep up with all the changes going on in the environment and how that impacts CI (configuration item) data.
New in Helsinki: CMDB Health Dashboard
Determine CMDB Health with CMDB Health Dashboard
Duplicate Configuration Items in the ServiceNow CMDB
Numerous blogs (some links above) have been written about the CMDB Health Dashboard and the metrics it provides. In this blog, I'm going to show you some best practices and thought processes to utilize when configuring the various CMDB capabilities within ServiceNow. The goal is to provide a framework to automating the upkeep of the CMDB by making choices on CI lifecycle policies. As no two companies operate the same, please use this information as a starting point for expansion and not as an all-encompassing, step-by-step guide for a completely hands-off CMDB (don't we all wish).
Here's a quick list for what's to follow in more detail:
- Create inclusion rules
- Identify the cause of duplicates before remediating them
- Tweak stale rules
- Create orphan rules
- Define required and recommended fields
- Create workflows to automatically handle tasks
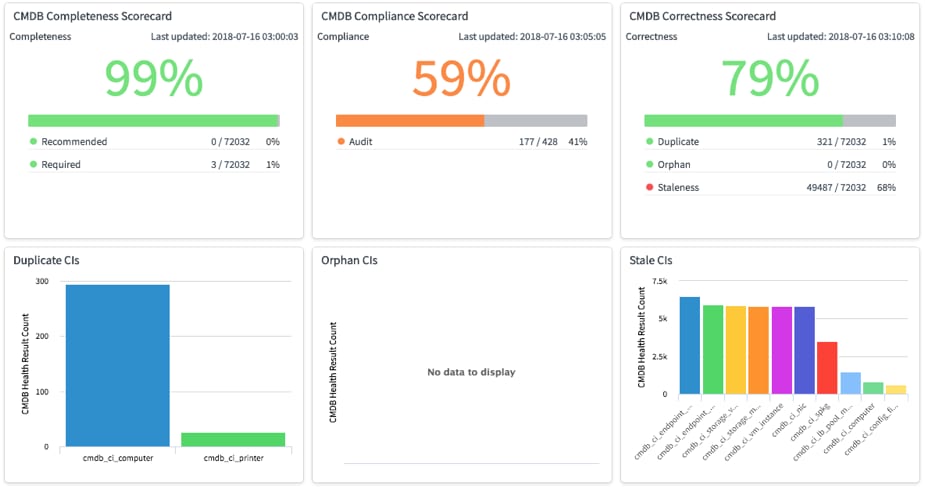
Now let's have a look at what things can look like before and after making some quick policy choices. Here is a look at the dashboard without configuring any of the above settings and just running the jobs to score the CMDB.
CMDB Health Dashboard Without Configurations
Now after making some tweaks about what CI classes should be scored and some orphan rules, we get a very different picture.
CMDB Health Dashboard With Configurations
Let's step through the details of what should be evaluated when configuring the various settings to make this a useful capability in your ServiceNow instance.
Inclusion Rules
Health inclusion rules are the first step in keeping your sanity about what this data is telling you about your CMDB. The core capability is to allow you to filter which CIs are scored (for everything but duplicates that is). This is very important for multiple reasons. Take an example environment where a customer may have just turned on ServiceNow's discovery capability as it comes out of the box, no limit on protocols (behaviors), no limit on technologies to exclude (applications), no tweaking of which exploration probes run, etc. In this environment you end up with a lot, and I mean a lot, of CIs that you never could have imagined would be created.
Rather than list all the granular classes that are populated, let's get back to inclusion rules. A good rule of thumb could be to only score what you have CI class ownership for. Otherwise, who cares about the score and who would do anything to make it better?
Health Inclusion Rule Example
The screenshot above shows an example of what health inclusion rules can look like upon initial definition. Here we are saying that we only want to score CIs that are in the Application hierarchy (including all child classes), the Hardware hierarchy, and the Virtual Machine Object hierarchy. We are also saying that we want to exclude all statuses that are not "Operational", and that it applies to all the metrics (orphans, staleness, required, and recommended). Even this definition has flaws.
Each of these 3 super classes has many, many child classes, so you may still be getting classes that have no owner. Similarly, you may want to conduct staleness scoring for all classes because you want to apply some remediation to anything that is stale (we'll touch on this in the automation section below). For this latter issue, you can tweak the inclusion rule and override the settings for just stale. Once you save this initial definition, you can then go back in to each metric and make tweaks as desired.
Duplicates
Probably the most painful part of CMDB maintenance for customers is dealing with duplicates. Below are many extremely helpful blog articles from my colleagues on how to deal with duplicates in varying fashions. To not be redundant, the focus of this section is what can the CMDB health dashboard do for you in the area of duplicates.
CMDB Identification and Reconciliation
Duplicate Configuration Items in the ServiceNow CMDB (worth repeating from above)
CI Relationship Duplicate Record Clean Up
Discover Multiple CIs with the Same Serial Number - Part 1
Discover Multiple CIs with the Same Serial Number - Part 2
When you run the CMDB Health jobs (correctness job most specifically), "De-duplication Tasks" will be created for any CI marked as a "duplicate". As noted in many of the blogs above, this is because a record has violated an identification rule regarding uniqueness. Each class, or superclass, has out of the box identification rules based on common identifiers. The reality is that they do not fit all technologies that exist in the world and so customers must tweak, create, remove, etc rules as they encounter duplicates. The CMDB health dashboard provides a view into which classes have the most duplicates and then lets you drill into the detailed list to evaluate what is making them a duplicate.
I will provide some options for handling duplicates automatically near the end of this blog, but the first step is to find out why they are coming in as duplicates and either tweak the way they're populated, or tweak the identification rules to properly capture uniqueness for the given CI class.
A very important feature to implement is that of identification inclusion rules. These are different from the health inclusion rules described above. Identification inclusion rules drive not only what shows on the CMDB health dashboard for duplicates, but also what the identification and reconciliation engine will evaluate when trying to find existing CI's. It is an extremely useful feature when you are controlling CI statuses as part of CI lifecycle management. Does your company "retire" or "decommission" CIs? Are you getting duplicates because the same CI attributes exist for a retired CI as they do for a newly provisioned device? Identification inclusion rules are the way to control these not being flagged as duplicates. There are no out of the box (baseline) rules, so you can either create them on a class by class basis, or possibly start at the base class (cmdb_ci) and make a rule like below.
Identification Inclusion Rule Example
As you can see in the "Inclusion Rule (Advanced)" section, I have specified for the ID and Recon engine (and the duplicate metric on the dashboard) to only evaluate "Operational" CI's when doing a lookup in the CMDB. This will be inherited by all classes given I defined it at the base level. Sweet, right?
Staleness
A stale CI is a suspect CI. Infrastructure and applications change quickly, and that rate is only increasing with new technology themes like microservices and public cloud (not really new, but more adopted). The baseline rule is defined at the base CI class level (cmdb_ci) and states a CI is stale after not having updates for 60 days.

Baseline Stale Rule
Some considerations around when and why to make additional rules on more granular class levels are as follows:
- How are you populating the CMDB (ServiceNow Discovery, schedule import, API via 3rd party, etc)?
- What frequency is the populating happening?
- Is it different from class to class?
Based on the answers to these questions you may decide that because network devices are only updated (discovered or other) every 2 weeks, you can define that they are stale after 21 days of no updates. Maybe servers should be discovered every day, so you give a buffer of 7 days before marking them stale. Whatever policy is right for your environment, this important metric should drive lifecycle behavior because you don't want CI's used in other ServiceNow processes if they don't really exist in the environment anymore. Again, I'll cover how to automate handling these towards the end.
Orphan CIs
An orphan CI should be flagged when it no longer has a desired relationship with another CI. Below is an example rule, but it's important to note that there are no baseline orphan rules, which is reflected on an initial health dashboard view when you first turn on the jobs.

Orphan Rule Example
In the example above, the orphan rule is saying that an Application CI (or child class) is deemed an orphan if there is not a "Runs on::Runs" relationship to a Server CI (or child class of server). Some other common examples are storage mappings having a relationship to a server, virtual machines having a relationship to an ESX server, etc. Even within the Application hierarchy there are times you need to override something like the rule I defined above. Take for example a Tomcat WAR file being its own CI class. A WAR file does not run on a server directly, but rather, should have a "Contains::Contained by" relationship to a Tomcat server CI.
Required and Recommended Attributes
A baseline instance comes with little or no required or recommended attributes in the CMDB. Given that data quality and consistency are the keys to a healthy CMDB, CI class owners (or the lone ServiceNow admin if that's all you've got) should consider specifying certain attributes as being either required or recommended when they are key to other processes. The needs will vary by class, but there are some choices which can be made at the base class level and inherited by all classes. For example, if the assignment group or support group fields on a CI are used to drive incident assignment, then those should probably be required. If approval group is used to drive approvals on changes for CIs, the that should probably be required.
*** UPDATE: It is very important to note that making an attribute "mandatory" may cause discovery jobs or imports to fail. The system property "glide.required.attribute.enabled" is set to true by default and will enforce mandatory fields to exist or give errors.
Being a required field is only used for visibility and does not impose any sort of database functionality in terms of errors or the like when the attribute is not populated (*** see UPDATE above for qualification to this statement). Because many attributes are not discoverable and require human input or decision making for automated updates (like a business rule), the required and recommended metrics are helpful for measuring the effectiveness of either a manual process or what is intended to be an automated process.
One last note on these 2 metrics. Implementing what is required (mandatory) or recommended, is very different and as such you may decide that one of them is sufficient for you purposes. A required attribute needs to be set one by one at the column level in a given table / CI class. Even that is over simplifying things because of the inheritance nature of the CMDB. Consider a field like IP Address. IP address is a great candidate for being mandatory on classes in the Hardware hierarchy. However, IP address is an attribute defined on the base cmdb_ci class. If you want to make it mandatory, you may need to create a dictionary override on the higher level class so that it does not impact all classes. Here is what it may look like for wanting IP address to be required on just the Hardware hierarchy:
Dictionary Override on the cmdb_ci table for IP address
We get to this point by opening the cmdb_ci table definition, then drilling into the ip_address column, then scroll to the bottom to see the related list and add a dictionary override. In this case we added an override that says ip_address is "mandatory" for the cmdb_ci_hardware table.
On the other side, recommended attributes are very easy to define in mass. You can go to the specific CI class you want (or super class), and use a slush bucket to move in the desired attributes (no dictionary overrides necessary).
Example Recommended Fields
In both cases you will get visibility into data consistency, but whether you always use just recommended, or you use both required and recommended can offer insight into high-impact data versus nice-to-have data.
Automating Tasks
Now that we've covered how to get the metrics working like you want, let's dive into some fun stuff on how to make issues go away automatically... sounds too good to be true, I know. The truth is that we can achieve this, but it does require some up-front decision making. For each metric we've discussed (duplicates, orphans, stale, required, and recommended) we can have a task created specifically for exceptions on a given metric type. For duplicates this always happens, but for the other 4 metrics you must enable the task to be created. This is done in the Health Preference module.
Health Metric - Task Creation
On the far right you will see a "Health Metrics" option. Once you click that option you will be taken to a Health Metric form where you can modify settings for each metric, including toggling the "Create Task" setting, which is off by default for all metrics except Duplicates(sorry, can't change that one... must address duplicates).
For each task type we can now create a simple workflow for handling the task automatically (or maybe manually at the beginning until you're comfortable with the handling options). Below are some code snippets that do different things, but they provide a template for handling each metric's task records so take them for just that, a template to be modified based on your processing needs.
Duplicate Task Handling
// Find all duplicate records associated with the current task
var grResult = new GlideRecord ('duplicate_audit_result');
grResult.addQuery ( 'follow_on_task', current.sys_id );
grResult.query();
var cis = [];
while (grResult.next())
cis.push(grResult.getValue('duplicate_ci'));
// Query for the duplicate records, and order in reverse chronological order
var grCi = new GlideRecord ( 'cmdb_ci' );
grCi.addQuery ('sys_id', 'IN', cis.toString());
grCi.orderByDesc ('sys_created_on');
grCi.query();
grCi.next(); // Skip the CI that was created first
while (grCi.next())
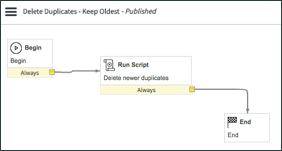
grCi.deleteRecord();This script processes a de-duplication task and orders the CI's by creation date, then deletes all but the oldest CI record. You can create a very simple workflow based on the "duplicate_audit_result" table and have a single script action that runs this.
Handle Duplicates Workflow
This process will repeat for each metric type, and you can change what is in the final step of the script to do things other than simply delete the record (maybe change to non-operational, update the name with "DO NOT USE", etc).
On the topic of duplicates, the London release of ServiceNow introduced a very cool feature called the Duplicate CI Remediator, which provides a wizard for handling duplicates in a non-coding method versus doing it with remediation task scripts as I'm showing.
Stale Handling
// Delete CI associated with current stale remediation task (stale_ci_remediation)
var ciGr = new GlideRecord ('cmdb_ci');
ciGr.addQuery ( 'sys_id', current.cmdb_ci );
ciGr.query();
if (ciGr.next()){
ciGr.deleteRecord();
}
Again, you may want to do something other than brute force a delete. Stale CI's are definitely ideal candidates for status changes to control lifecycle. Once a CI you may not want hanging around has been change to retired or non-operational or whatever is desired, you can use archive rules to move to an archive table (while retaining a reference to them) and ultimately create destroy rules to purge the archive data once it's deemed unnecessary.
Orphan Handling
// Assign current orphan task to CI assignment group (orphan_ci_remediation)
var ciGr = new GlideRecord ('cmdb_ci');
ciGr.addQuery ( 'sys_id', current.cmdb_ci );
ciGr.query();
if (ciGr.next()){
current.assignment_group = ciGr.assignment_group;
current.updateRecord();
}
In this orphan example, we are updating the task record with an assignment group to handle the task versus just deleting the record, but you may find that deleting certain types of records is the best path (a storage volume that no longer has a server or virtual machine for example).
Automatic or Manual?
Now that you have some remediation options, how can you use them for certain CI classes and how can you control if they run automatically or initiated manually? CMDB Remediation Rules are the answer.
Remediation Rule Examples
While I showed just a single option for each metric, you may want to handle them differently based on class, which will result in multiple workflows being created based on the CI type (maybe you're okay deleting application CIs when orphaned or stale, but want to just modify the status for hardware CIs). If you do this, it's easy enough to just set a filter on the remediation rule that filters for CI types of just that class. Similarly, you can define the remediation to run automatically or manually on the rule as well.
Other Considerations
If you've stuck with this blog to this point, congratulations, it's a long one. While we've covered the main content I hoped to communicate regarding how to monitor and automate many aspects of the CMDB, there are other things to consider as next steps. Remember those health inclusion rules from the beginning? Don't let them mask problems. By that I mean don't think that not scoring something makes a problem go away in terms of unnecessary data in the CMDB. As you're using CI's in other areas (on incident, on change request, etc), you want to control what CI's show in different circumstances and this may include controlling what you store (or clean-up from stale). While you can create an advanced reference qualifier, you should also be creating a solid CI lifecycle policy for all your CI classes so you can drive the type of automation we've described here or within other mechanisms like scheduled jobs or business rules.
Related records are another painful area in the CMDB. When you retire a server you don't want to retain all the running process records, or TCP connections, or installed software, etc, do you? Probably not because they don't really exist anymore. Same for a network device. You don't want all the routing interfaces and such that a network device keeps a relationship to. Consider creating a business rule that fires after an update (update that has the status changed to something like "retired") or deletion to one of these highly related CIs, and have the processing go through and delete unnecessary related lists. Hint, there is probably a past Knowledge lab that has an example of one of these scripts, which is too long to include here.
A final recommendation is to tweak the scorecard thresholds for each metric. The baseline setup is for green, yellow, red thresholds to be at even 1/3, 1/3, 1/3 thresholds for scoring. In reality, if you're doing something like saying IP Address is required for all hardware CIs, then you probably want that to be red unless it's at 98-99% accurate. Likewise, duplicate CIs should be minimal and so the threshold should be modified accordingly.
Override Default Scorecard Thresholds ("Required" metric example)
As these thresholds are best tweaked at the various class levels where you have ownership identified (so they can manage what they can now measure), the default view of the CMDB Health Dashboard will be to show the score of the entire CMDB in aggregate. Make sure you and your class owners know to filter down to their specific class when evaluating a relevant score to them.
Filter CMDB Health Dashboard for a Specific Class
While we covered a lot here, I'm sure many of you can provide other examples of cool things you've done along these lines, so please share in the comments and we can create a running list for making CMDB great again.
Labels:
- 128,739 Views
32 Comments
- « Previous
-
- 1
- 2
- 3
- 4
- Next »
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}