Laurent5

ServiceNow Employee
Options
- Post History
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
on 07-30-2019 07:45 AM
In the first part of this series, we looked at extracting data from ServiceNow for Machine Learning purposes.
Now that we have our data, we will look to further prepare it in order to create our model.
Before we do that, I’d like to go back to the data type conversion to numeric we performed in the previous article.
It is useful to double check the data type of columns and Pandas offers a nice function to do just that: dtypes.
You can just apply it to your dataframe, df.dtypes for instance and it will return the data type for our columns. So in our previous example, we can see that task_calendar_duration was already an integer so no numeric conversion was actually needed.

Next, we need to scale the data.
Scaling, or feature scaling, ensures that we limit the impact of varying magnitude of features(i.e what we analyse) on our results. Since there can be range and units disparities in the data, we want to ensure everything is basically using the same scale, hence the name!
Varying features can have different impact (or sometimes none at all) depending on the algorithm. There are multiple ways to scale the data (Standardisation, Mean normalisation, MinMax.) and can be performed “manually” (i.e by coding the calculation) or use an existing scaler.
In the following example, we will use the MinMax scaler which available as part of the scikit-learn tool kit (https://scikit-learn.org/stable/). We will import it in addition to the other libraries we need:

For this example we will use the same example of data containing both a score and a duration, which we will import using the Pandas function read_csv and store the content in a Dataframe df (for the purpose of this example, I have renamed the column names that we will use, i.e duration score and reassign , for simplicity)

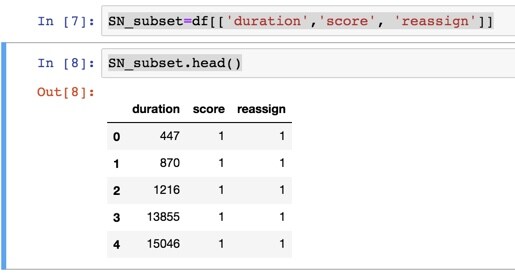
To simplify our dataset, we can create a subset that we will call…SN_subset. This way we can only keep the columns that we will need for our model.
This is done with the command
SN_subset=df[['duration','score', 'reassign’]] and we can preview it with SN_subset.head().

Since we are trying to predict y, i.e the score, our x data will contain the other columns (or features) duration and reassign.
To do that we will create a dataframe called x_data that will contain all columns except “score”.

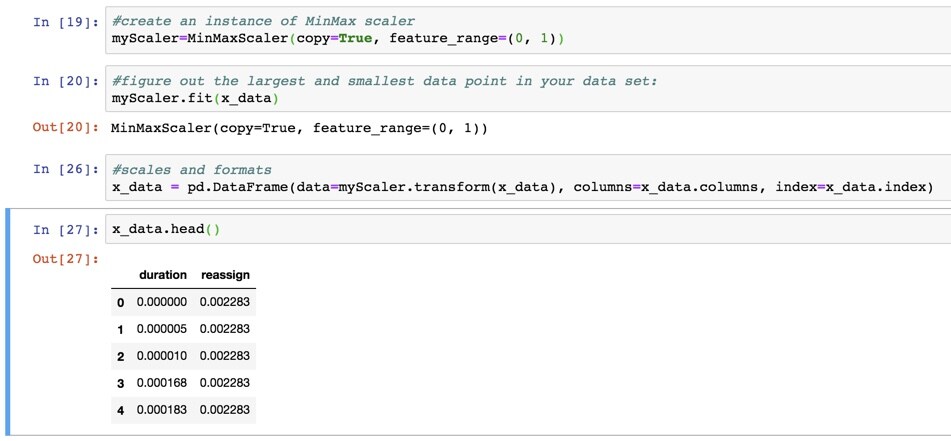
We then need to create an instance of the MinMax scaler that we will call myScaler and we will feed it our x_data set so it can check the smallest and largest value (myScaler.fit). We also set the range we want to use. In this case, between 0 and 1 (but could be -1 to 1 for instance).
Once this is done we can get it to scale our dataset with myScaler(x_data) that we format using a Pandas dataframe (this could be done as multiple lines but this one does everything in one go).
Finally we can check it has done its job by getting a preview with the .head() function we saw above, where we can see our values are now between 0 and 1.

In this example, we scaled the entire data set features. Another step required is splitting our data set into 2 batches: one for training the model and another one for testing it. This step is called… you guessed it, train-test split! Ratios would vary depending one the size of our data set but what I have seen is usually 70-30 or 80-20, the smaller amount being for testing.
Sklearn also has a dedicated function which you can import using the following command:
from sklearn.model_selection import train_test_split
We then create new variables called x_train, x_test, y_train and y_test (or whatever name you prefer using) and pass them to the function as below:
x_train, x_test, y_train, y_test = train_test_split( x_data, y_value, test_size=0.3, random_state=101) and job done!
Test_size indicating the proportion for test (i.e 30% in that example) and random_state is used to indicate the randomness of the result. i.e if no random value set, each run will generate a different train-test result whereas by setting a value, it will always generate the same result. This is useful if you want reproducible results for testing purposes.
With data scaled and split between train and test, we will next build a Machine Learning model to start predicting our CSAT based on TTF and the number of reassignments. Watch this space!
End of part 2
Labels:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- 3,846 Views
Comments
Sharique Azim
Mega Sage
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
10-18-2019
07:00 AM
eagerly expecting "building a Machine Learning model" article from you very soon 🤩
Laurent5
ServiceNow Employee
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
10-23-2019
05:57 AM
Thanks a lot Sharik!
Working on it so hopefully not too long now 🙂
I had to change a little to use some more recent high level API in TensorFlow so need to update my article.
Laurent5
ServiceNow Employee
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
11-08-2019
08:56 AM
It is now posted 🙂