- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-14-2016 08:12 AM
I have a really strange phenomenon involving import sets. This is on the Helsinki release. It seems that if I have two transform maps for the same import set, somehow the import set table produces a duplicate of all the data rows from the original import set!
A very simple CSV file with 9 rows containing machine names and some hardware data is loaded into a table named 'test_import'.
It looks like this:
Asset Tag,Appliance,Platform,Module,Component,Manufacturer,Model,PN,Man PN,Man SN
13752,ilauctsa01a,Dion,ilauctsa01a,Chassis,,1-u Intel D-Generation Edge Cache/SAS,,2602-556242,VM15AS001990
13752,ilauctsa01a,Dion,ilauctsa01a,Cpu/Processor1,Intel,Intel(R) Xeon(R) CPU E5-2630 v3 @ 2.40GHz,,,
13752,ilauctsa01a,Dion,ilauctsa01a,Cpu/Processor2,Intel,Intel(R) Xeon(R) CPU E5-2630 v3 @ 2.40GHz,,,
13752,ilauctsa01a,Dion,ilauctsa01a,Memory1,Samsung,8GB DDR4-1866 SDRAM DIMM Module,,M393A1G40DB0-CPB,418A74A0
etc...
I created two test transform maps that run scripts. They are called Test Import One and Test Import Two. They both look like this:
(function transformRow(source, target, map, log, isUpdate) {
// Do nothing
ignore = true;
})(source, target, map, log, action==="update");
After loading the data, if I look at the import set table named 'u_test_import' there are 9 rows.

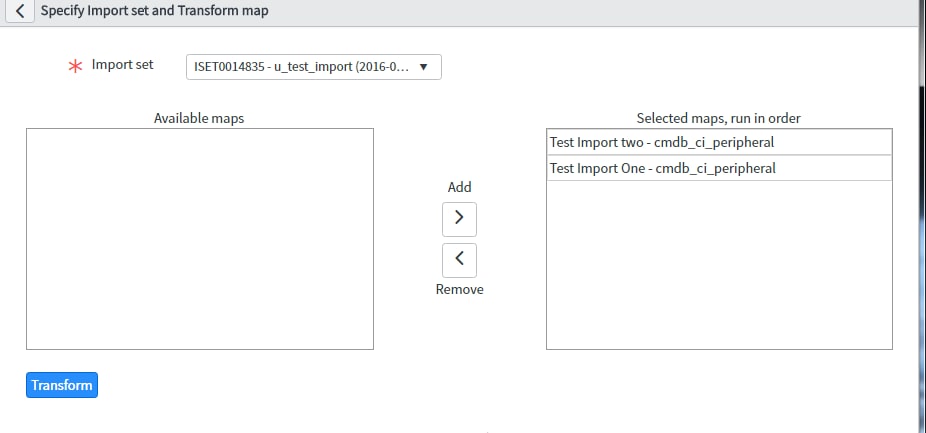
Then I run the do-nothing transforms:

After the transform there are now twice as many rows in the IMPORT set table as before:

So the "transforms" I had did nothing (ignoring every row) and yet my INPUT table has doubled in size. As you can imagine this is not a good thing with massive data sets (which is unfortunately how I discovered this).
Can anyone explain what is going on here? Is there something I'm doing to cause this that I can work around?
Thanks in advance for any help!
Solved! Go to Solution.
- Labels:
-
Integrations
-
Scripting and Coding
{kind=link}
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-14-2016 09:03 AM
While I don't have all the platform level details, I can certainly understand why it duplicates if you run them at the same time vs. separately.
Running them separately gives you the opportunity to analyze the results after each run. Run Map 1, check results. Yup, user's imported fine. Run Map 2 after it manually, check results. "Hmmm, some issues". If you run these together (map 1 for users and map 2 for groups) how can you tell which worked and which didn't, when you are sending to two different target tables? From a status perspective, you need two import set records when running two maps on the same source data.
The other alternative would be to have a status related list for each import record and treat the imported data as "sacred" and a related list of output status from each map that was run. In 99.9% of the cases (or more) this will be a related list of one record. That would require the engineers to rebuilt some bits of the import set engine, which you can recommend.
I invite you to open an enhancement request! Our product managers DO listen.
Enhancement requests: Tell us how you would improve the ServiceNow product
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-14-2016 08:50 AM
Hi Gregory,
I just wanted know did you made Coalesce Field true before you are going to run another transform ?, When ever you are running a new transform map its better create new table, load the data into it and run transform in your instance. If you are updating the same data using excel sheet or CSV once again, enable the Coalesce to true for a particular field, so that it stops creating a duplicate records.
transform maps, --> select the transform map you have created and make a field Coalesce true.
May be this might be helpful
Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-14-2016 08:53 AM
Hi Harish,
I thought about coalesce at first also, but then realized he's showing duplicate records in the import set table, not the target table. Incorrect (or no) coalesce will result in duplicate records in the target table.
http://wiki.servicenow.com/index.php?title=Using_the_Coalesce_Field
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-14-2016 08:57 AM
Hi Chuck,
Thanks for correcting me , yes you are right, your post here is the right solution I believe.