- Post History
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
on 09-29-2021 06:21 AM
In the Tokyo release, it is now possible to perform "Bulk Article Translations" via the Localization Framework.
Check the release notes here for more info.
I recently got asked this question by a Customer, where-by they suddenly had a business requirement to translate their entire KB (thousands of articles). Always up for a challenge I put pen to paper and tried something, so lets play out the scenario.
Imagine the scenario
You have an established English KB (or more than one) and for a new business reason you now need to have it translated into a number of additional languages. You don't have much time to do it and you don't currently have the luxury of being able to review the architecture of your KB, yet you do know the priority Articles that would need to be translated.
From our training (available here) we know that translated articles work in a Parent > Child relationship like this:
We also know that all articles (no matter the language) are populated in the [kb_knowledge] table (or an extension there-of), just with certain values in certain fields in order to work as necessary (imagine Category, Short description etc). We therefore have a bunch of options to translate these articles available to us:

- Manually create the Translated (child) articles - there's nothing wrong with this approach at all, except in this scenario it will take a long time. Whilst it is a perfectly valid option and fits a lot of use-cases, it's not the topic of what we'll cover in this post.
- Leverage "Translation Management" within Knowledge Management to allow us to easily translate the articles either manually or via an MT - absolutely nothing wrong with this approach either as it also covers many use-cases and is really good for net-new articles, just not the subject we'll cover in this post.
- Excel export a defined and filtered list of articles to re-import later - I typically see this as the most common approach, however it has just as many cons as it does pros. One of the big cons is that Excel's cell character limit is 32,000 chars, which means if you are needing to work with large HTML heavy formatted articles, you could reach that limit quite easily.
What if I said there could be another way, to do it with XML?
Before we go too much further, it's important to know and understand that there's no specifically right way or wrong way to do this. As it comes down to knowing what is possible and therefore being able to determine what fits best for your needs at that time. I'm sure someone will mention in the comments (at some point in the future) that there are other options I've not included here, which is absolutely fine, the chances are without including some sort of integration to somewhere else it'll probably be a derivative of the above.
Where do we begin?
The first thing we need to do is navigate to the [kb_knowledge] table (this is where all articles are stored) and filter a list of what we want to work with. For the sake of demo and explanation I'll just use one article for now:

As a side note - one of the main differences between an XLSx and XML export, is that XLSx will only include the attributes of the columns you see in the list view, where-as XML will include all. This is one of the reasons it's often used to migrate data between a sub-Prod > Prod instance as it can preserve sys_id's.
To export our list, we can click on any column header in the list and select the following path:
Once downloaded, we can view the XML in a browser or code editor like Visual Studio code to validate it's formed correctly:
For those who don't know, XML's attributes are called "namespaces" and in this scenario they correlate to the fields on the table we created our extraction from. This is why we can see "sys_updated_on" or "short_description" etc.


What we need to make a note of in this example is the following:
- number - we will use this in our transform script later
- article_id - you may need to use this in the transform script
- language - this will form an important part of our import and be used in the transform script later
- latest - this can be used to ensure we create a relationship with the latest version of this article, if "Version Control" is used. So review as per your needs.
- kb_knowledge_base - this will help us map our new translated article into the correct KB
- kb_category - this will help us map our new translated article into the correct category for the correct KB
- meta - if we translate Meta to assist search results, then this is how we can populate them into the new article
- short_description - this will become the new article's title
- text - this will become the body of the new article
We have our extract, what do we translate?
When dealing with massive quantities of translations, this is where a "TMS" (Translation Management System) comes into its own. Essentially, this is a tool that can handle the act of translation strings / content at scale.
Whilst a topic for another post, we actually have spokes for our "Localization Framework" product to 2 of the biggest TMS's out there (available in Quebec+):
RWS:
XTM:
With a TMS you can cherry-pick which of those "namespaces" in the XML (because they natively work with a XML type standard called "XLIFF") to mark for translation allowing you to preserve the remainder of the XML's contents. And for this scenario, this is exactly what we want to do, as it could preserve sys_id's making our potential transform activities easier.
We've got our translations, how do we import them?
Let's imagine that we've translated the "short_description", the "text" and changed the "language" to Chinese (zh) and we want to import this new article via our XML method, how would we do that?


* For the sake of explanation, our translations will be the English just with an extra "ZH" in-front of them.
Well, we can't just flat import the XML as is, because if we did do that it would just overwrite the English source articles as the records' sys_id's would match. So what we need to do is define a new "Data source".
Navigate to "System Import Sets" > "Data Sources" and define a new one like this:
The idea here, is that we're going to attach our big XML file of translations to this data source and process it as a one-time event (so "File Retrieval Method" needs to be "attachment"). This is because, after we've performed our bulk scenario any new articles can either be managed through "Translation Management" or other KB processes.
But... before we get into the Transform Map, it's important to validate the XPATH, which should be similar to "/unload/kb_knowledge" with "expand node children" set to true.
If you run a 20 row test load and navigate to a record, you should see that a field has been made in your staging table per namespace in the XML like this:
^ The form will naturally be quite large. What we're confirming here is that we will be able to call any "source.field" in our transform map script later.
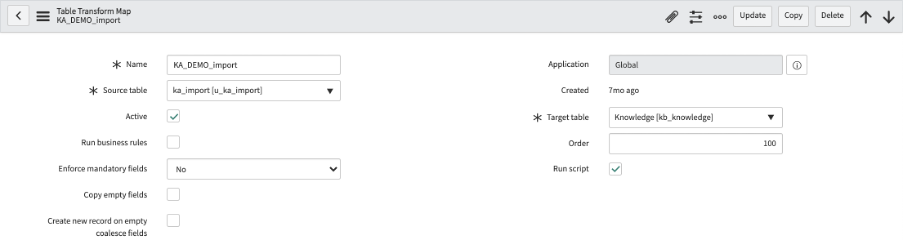
Ok, so we have our translation performed and provided in the XML, we have validated our XML and our import-set table, let's go and make a new Transform map.
The "Source table" will be the import-set table we just created and the "target table" will be [kb_knowledge] and it should look like this:
^ we need to make sure that "run script" is set to true.



Your specific script may vary, as you may need to factor in custom fields, mandatory fields, other reference fields that require additional lookups etc, however as a concept it should look similar to this:
(function transformRow(source, target, map, log, isUpdate) {
// lets find the english article
var artCheck = new GlideRecord('kb_knowledge');
artCheck.addQuery('number', source.u_number); // article numbers should be unique
artCheck.query();
if (artCheck.next()) {
// lets make the translated article
var newArt = new GlideRecord('kb_knowledge');
newArt.initialize();
newArt.short_description = source.u_short_description;
newArt.kb_knowledge_base = artCheck.kb_knowledge_base;
newArt.kb_category = artCheck.kb_category;
newArt.parent = artCheck.sys_id;
newArt.text = source.u_text;
newArt.language = source.u_language; // this assumes that the XML has the correct 2 digit language ID
newArt.insert();
}
ignore = true; // this will stop the row being processed per field which would cause blank entries to be inserted into the table
})(source, target, map, log, action === "update");
As you can see, the transforming is no different to normal. It just happens to be via a script so that we can preserve a parent>child relationship, with a slightly different data-source to populate our staging table.
And once we've run the transform on our import-set, we should see a result like this:
^ notice how the parent field has been correctly populated and the article has our expected values and set to the correct language. Also in this example the article is in a draft state.
What have we learned?
To recap, we've leveraged existing and established concepts in the platform for an additional use-case to cover a big business need. Via this method it could handle hundreds / thousands of articles for importing at scale without a single spreadsheet.

Whilst this solution is not perfect and can certainly be tweaked / modified to additional needs, it's important to remember (as stated at the beginning of the post), there is no specific right or wrong answer for importing tens of thousands of articles as everyone's needs often are slightly different for various reasons. However, this could be another avenue for you to consider.
Please let me know your thoughts down below as I'd be curious what you all think
- 13,119 Views
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
This was a great take on bulk translation.
But I am working on translating the knowledge articles IN servicenow instance itself without exporting.
I made a list choice UI action so that user selects multiple records and then it open a custom pop-up UI page where user can select the language in which they want to translate these articles into.
Now, I want to just send the array of sys_ids of the articles to a script-include where I run loop to translate the articles one by one.
This will remove the need of the user to go through each article and clicking 'Translate' button , and automate the whole process.
Let me know, if you have any ideas about this, anything would help.
-Thanks and Regards,
Neil
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Apologies for not seeing this sooner,
If it helps, within "Translation Management" (the feature in KM), if the languages are defined at the KB level and the tickbox to auto-generate the tasks is also ticked, then every time you publish a new English article (for example) it will auto-generate the per language tasks for you,
Just be very careful with automating the translations themselves, as they may not necessarily come back in the first time as a native speaker would expect them, therefore they might need some review,
Many thanks,
Kind regards
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
I am trying above method but it seems record not getting inserted to it ServiceNow. Are you Translate the Articles in same instance or different. can please tell
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
This specific method would have to be on the same instance due to the import-set and transform map requirements,
Many thanks,
Kind regards
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi @Alex Coope - SN ,
Can you please help me with how we can do this from excel. We are planning to get the knowledge articles data in translated format from customer. Then we need to bulk upload this data.
Please suggest what is the best approach to do this translation.
Thanks.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
@Brijmohan,
Ok, so it's best to not translate KB's via excel for a multitude of reasons:
- Excel's cells have a character limit of 32k in length, so if you have HTML this is problematic
- Version control is a really big challenge
- Complex transform scripts.
In the Tokyo release we actually introduced an Artifact in the Localization Framework to be able to translate Knowledge articles from within the platform:
https://docs.servicenow.com/bundle/tokyo-servicenow-platform/page/product/knowledge-management/conce...
With that being said, the way translated articles work is that the translated articles are essentially "child" articles to the "parent" being the English. So if you have a spreadsheet you would need to know the KB number (at a minimum) of the source English article as your transform script would need to GlideRecord each row you're processing to find the right parent, the right KB, the right Category etc to then insert your translated row of your spreadsheet (in the right language) as a new record in the kb_knowledge table. Not too dissimilar to my transform script in this post (it would for sure need to be refactored to your specific needs though),
However, I'd suggest checking out our "In-Platform Language Support Guide" to see more about the newer features available,
Many thanks,
Kind regards
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi @Alex Coope - SN,
Thanks for your prompt response and assistance. I will try with the above solution.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi @Alex Coope - SN,
I am trying to bulk translation for kb articles but LRITM are not generating, getting 2 request were skipped. Please guide me what I am doing wrong here.
PFB snap.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Thanks in advanced!
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
@Brijmohan,
My guess would be that you already have open LRITM's for those articles in the chosen languages in-flight, or Draft articles already created in those languages so it's "skipping" them to save you from unnecessarily duplicating them,
Many thanks,
Kind regards
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi @Alex Coope - SN ,
I have checked but no open LRITm there, I checked for other articles, same behavior for that also. Will check again.
If we have duplicate article with same number in draft state, It can be a cause??
Thanks.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi @Alex Coope - SN ,
I have checked for all other articles from Request translation UI action but same issue "request were skipped".
I am not able to proceed with bulk translation. Don't know why it is happing. I have checked all settings but nothing found useful. Also didn't found from where this message ("request were skipped") is coming.
It is working for record producer bulk translation.
Thanks.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
@Brijmohan,
Yeah, this message is specific to the Knowledge artifact,
Could you double check (for my troubleshooting) that the articles you requested translations from were already published?
Many thanks,
Kind regards
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi @Alex Coope - SN ,
Yeah, articles already published. I have imported those articles from prod instance to dev.
Bulk translation is working for articles that are already present in dev but not for imported one.
Thanks.