


vNick

ServiceNow Employee
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
02-01-2019
01:49 PM
"Noise reduction" ... "efficiency" ... "work on what matters" ... "get to root cause faster". These goals / aspirations / initiatives / or any other synonym for trying to achieve an outcome, are commonly associated with today's AIOps projects that want AI/ML-based event management solutions (like ServiceNow's) to perform levels of automation and understanding not previously available. While great strides are being made towards this end, the reality is that AI/ML needs a critical mass of data before it can come to conclusions about how to achieve these outcomes and it is currently best suited for analyzing metric data to detect anomalies, which is one of the capabilities of our Operational Intelligence module. Gartner's 2018 report on AIOps is a good read on the current state of AIOps if you have access.
Imagine the scenario where you have a network device that either fails completely, or the ports for a specific VLAN fail. Your network monitoring solution will hopefully send you an alert that tells you something went down, or if you're monitoring at a more granular level, you may get numerous alerts, one for each VLAN or port. You are also likely to get numerous alerts for all the devices and applications which rely on the network device or port(s) for communication. Ideally, when you start troubleshooting the issue you will see all these alerts correlated together with the network device's (or port's) alert being the primary, so you can focus on that first.
ServiceNow has the ability to "learn" these relationships and perform this type of correlation automatically (heck, it might even happen just based on relationships in the CMDB if you are populating it), and there are a number of articles written on the topic which I have included below.
Journey through Event Management - Alert Correlation : Aleck Lin
Service Analytics: Rise of Machines : Ben Yukich
Turn Noise into Actionable Insights to Answer Your Questions : Hakan Isik
Operational Intelligence in world of ML & AI
However, what if we want this type of event to be handled on day 1 of deploying such a correlation solution? Thankfully, ServiceNow provides such a capability and that will be the focus of this article.
Alert Correlation Module
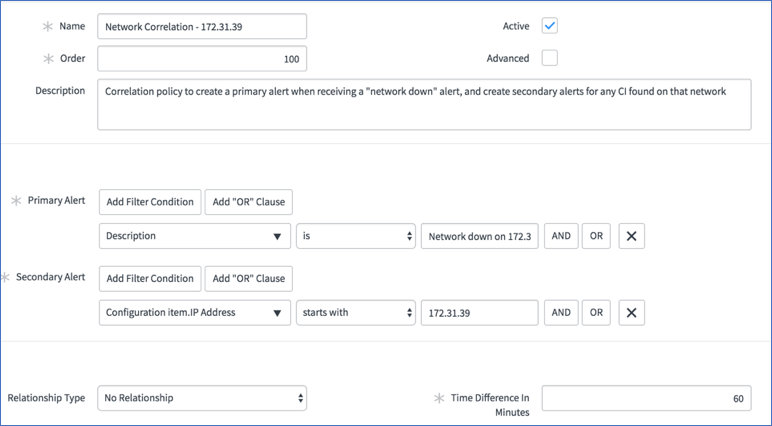
Below is a screenshot of a simple approach to creating such a policy within the "Alert Correlation" module. You will notice at the bottom of the definition that it does not depend on a relationship to exist within the CMDB. We do, however, take advantage of the CMDB (why not, we have it) to determine the IP address of any configuration items that come in with alerts and reside on the same network as the "network down" alert notes.
Simple alert correlation policy
This policy is enough to implement, but what if you have 10s of 1000s of networks? You don't want to create that many policies by hard coding each network into the policy.
Advanced Correlation
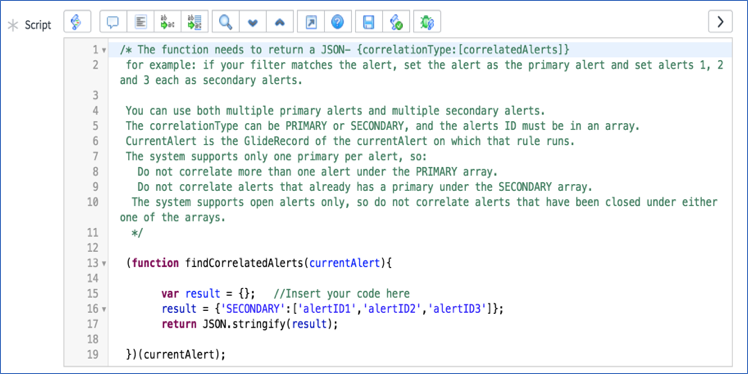
Now we can get to the advanced processing I teased in the title. You see that little checkbox at the top-right of the screenshot above (just below the "Active" checkbox)? Yep, you guessed it, this is what we have to "check" to enable the advanced processing section of this module. When you do so, you will be presented with the script section and some starting code to get you on your way.
Template code for advanced correlation
Let's just jump into the final code and then I will explain (and have hopefully commented to the code well enough for it to be explanatory when referencing later).
(function findCorrelatedAlerts(currentAlert){
/* CONFIG:
1. timeDifferenceInMinutes
Time difference between alerts - in minutes.
Example: 60 (equals 60 min, 1 hour)
2. NETregex
Regular expression to obtain first 3 octets of an IP address, and works for IP in a longer string like a description
3. desc
String in an Alerts description field that should be matched
Example: desc = 'network down' will match alerts with something like 'Network down for VLAN 10.1.1.0'
*/
var timeDifferenceInMinutes = 60; // Default 60 minutes between the first alert and the alerts that follow
var NETregex = new RegExp('\b(25[0-5]|2[0-4][0-9]|1[0-9][0-9]|[1-9]?[0-9])\.(25[0-5]|2[0-4][0-9]|1[0-9][0-9]|[1-9]?[0-9])\.(25[0-5]|2[0-4][0-9]|1[0-9][0-9]|[1-9]?[0-9])\b', 'j');
var desc = 'network down';
/* End of CONFIG */
// Initialization
var result = {};
var PrimarySubnet = '';
var CIsubnet = '';
// Alert CI must have an IP address to continue processing
if (!currentAlert.cmdb_ci.ip_address) {
return result;
}
// Prepare time diff for the query
var timeDifferenceBetweenAlerts = new GlideDateTime(currentAlert.getValue('initial_remote_time'));
var timeDifferenceInMilliSeconds = Number(timeDifferenceInMinutes) * 1000 * 60;
timeDifferenceBetweenAlerts.subtract(timeDifferenceInMilliSeconds);
var gr = new GlideRecord('em_alert');
gr.addQuery('description', 'CONTAINS', desc);
// Add query to search for alerts that are not closed by relation of potential parent (0 or 1)
// in time window (60) and order by time of creation
gr.addQuery('state', 'NOT IN', 'Closed');
gr.addQuery('correlation_rule_group', 'IN', '0,1'); // 0 = None (potential parent) | 1 = Primary alert (parent) | 2 = Secondary
// UNCOMMENT if you want time-based processing
//gr.addQuery('initial_remote_time', '>=', timeDifferenceBetweenAlerts);
gr.orderBy('initial_remote_time');
// Get the alert that may be the parent of the current alert by answering the conditions.
// If the alert is primary - make the current alert secondary, else - do nothing.
gr.query();
if (gr._next()) {
// Get first 3 octets of subnet and first 3 of current alert CI to see if they match
PrimarySubnet = NETregex.exec(gr.description);
CIsubnet = NETregex.exec(currentAlert.cmdb_ci.ip_address);
var correlate = 'false';
if (CIsubnet == PrimarySubnet)
correlate = 'true';
// Perform check to see if alert (primary) had an IP address (VLAN) and that the CI on the alert is in the VLAN / subnet
if (correlate == 'true') {
// Set the primary and secondary alerts by SysIds if parent was found
// The VALUES for BOTH keys (PRIMARY and SECONDARY) must be an ARRAY of ALERTS SYS_IDS, e.g. SECONDARY: [SYS_ID1, SYS_ID2...],
// while the value for primary can contain only 1 sys_id
result = {
'PRIMARY': [gr.getUniqueValue()], // getUniqueValue() retrieves sys_id, then put in an array (value MUST be put in an array)
'SECONDARY': [currentAlert.sys_id+''] // Retrieve sys_id, then put in an array (value MUST be put in an array)
};
}
}
return JSON.stringify(result);
})(currentAlert);Code for generic network correlation
If you desire to only process alerts that happen within a certain timeframe (like within 60 minutes of one another), I have left the code in place to do so, but you will have to uncomment out the "addQuery" line that evaluates the time values.
*** NOTE ***: This example should be expanded in a true production environment as it makes a couple of high-level assumptions that do not work in a networks. First, I'm only evaluating the "ip_address" attribute on the CI record. A more comprehensive approach would be to also cycle through any related records in the "cmdb_ci_ip_address" table and evaluate those as well. Second, this solution is looking at just the first 3 octets of the IP address, which would assume something like a /24 CIDR block (or a 255.255.255.0 netmask). Again, a more comprehensive solution would determine the true CIDR for the network(s) impacted and evaluate against the corresponding parts of the CI's IP address (maybe it's the first 2 octets instead of the first 3, etc).
To begin looking at the code, we initially see 3 variables being set. A time difference, a regular expression, and a description. The time difference will be used if you only want to evaluate alerts created within a certain time period of one another. The regular expression is complex looking, but it will find an IP address, either standalone or within a phrase like an alert description. It performs things like removing leading 0's or not evaluating them, and it is only attempting to get the first 3 octecs of an IP, so this is where you might want to have multiple variables that have a regular expression getting all 4 octets, or maybe just 2, etc. A description variable is being set so that you can control what type of message triggers the identification of a primary alert (like "network down"). This could be a "type" of event, or specific "resource" designation, etc, but the point is that you want to use something in the query that finds an alert representing the likely primary issue.
When the query executes, we simply compare the IP of the current configuration item to that of the alert noting the network is down, and then correlate them together if there is a match. Again, this is where you could have a "switch" statement based on some math that calculates the correct CIDR so you are comparing the correct set of octets.
The final steps are to add the records to the "results" object, which is then processed by the correlation engine.
The Outcome
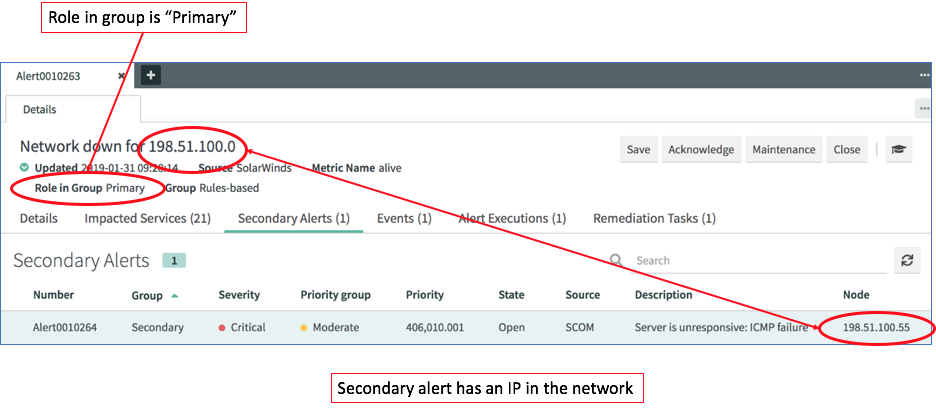
Below is the outcome of such a scenario where we have 2 alerts correlated based on this processing.

Outcome of correlated alerts
Conclusions
Machine learning can and will do great things for processing through mountains of data to find patterns that a human may not find or cannot process through due to volume, but it will require time and occurrences of the various alert combinations before it "learns" patterns that should be applied to meaningful correlation. And even when machines to start correlating alerts automatically, remember the maxim that "correlation does not imply causation". In other words, the root cause is not always determined from correlation of alerts or by humans voting on what they "think" is the likely issue in a war room situation where the goal is to just get things back up and running a quickly as possible. Correlation can definitely help reduce the noise to get to those answer faster, and creating your own correlation policies is a very effective way for addressing the needs of known scenarios sooner than later with an outcome being the purposeful assignment of something like a network device as the primary for devices that rely on the network device, leading to less wasted time sorting through all the alerts.
Labels:
- 9,977 Views
2 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}