- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-16-2019 02:33 PM
Hey everyone,
I wanted to check and see if anyone has successfully implemented the CMDB without using ServiceNow Discovery and Service Mapping and what did it look like?
- Do you manually create Business Services and Business applications?
- Do you automate the creation of some assets using the various data sources?
- Do you map the applications to the server it resides on and the network device it uses manually?
I am waiting on budget to approve the purchase of Discovery and Service Mapping, but I want to know my options if this is something that will not be approved? What is the minimal viable product that works for your organization?
Solved! Go to Solution.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-18-2019 08:30 AM
Hi Rodel -- Yes, I think it makes sense to map the services in a manner like this. BUT again, I fully believe automation and distributed ownership is necessary to keep it accurate. Its great to build business hierarchical relationships like this in the platform as they can provide a lot of value to ITSM processes. Keep in mind long-term sustainability. Who is going to keep this up to date? How? What about when they leave? retire? get bored with it? new boss takes over, whatever....
When I worked at Intel 10 years ago, the SN CMDB service model didn't exist -- so we built our own, which BTW looks very much like what ServiceNow just released as the Common Services Data Model 2.0. CSDM 2.0 is here But back years ago it had to be hand-wired together manually and maintained. Designated service owners had to A) understand B) buy-in to owning it C) maintain it It took a LOT of meetings, training, and management support to sustain it back then.
Why do i bring this up? because your original question inquired about using automation (i.e. Disco, SM, etc.) to populate CMDB. Not only is automation crucial for CMDB, but its also extremely important for higher level objectives like the service model you are considering.
I definitely do NOT suggest trying to do this without integrations and automation. Why? If the business leadership has not bought into the need to invest in automation, then this implies also:
A) They don't appreciate How complex the IT ecosystem truly is to support these services
B) They don't comprehend Service definitions need to be built with corresponding accountability
C) Tools/capabilities (automation) are needed to achieve A & B for long term sustainability
If these posts / replys are helpful, please acknowledge with Helpful buttons to encourage others to participate in the conversation too. Hope this helps! 🙂
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-22-2019 11:16 AM
Hey Dave,
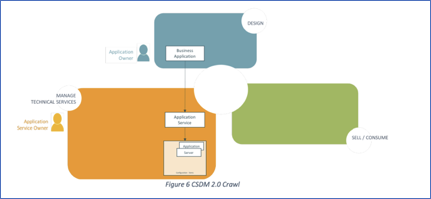
Thank you for sharing the CSDM 2.0 white paper. I started to mock up some hypothetical services for “Communications and Collaboration Services” and had some questions. I am working on the best approach to implement the “Crawl” method in the white paper that focuses primarily on Business Applications, Application Service and Application (Discoverable) and Server/Host (Discoverable). We plan on using SCCM to support the discovery of Server and Hosts without the relationship’s day 1.









- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-22-2019 11:17 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-17-2019 07:30 PM
I agree that some level of discovery is essential to the success of a CMDB. You can build processes to capture CI's if there is a central channel for provisioning, but inevitably someone will provision outside of the process and the holes in your data will grow.
From a service mapping point of view, I've had limited success in the past using provisioning and decommissioning processes to capture relationships, but again it is only valid if those processes are used consistently.
Whether you are using Discovery and Service Mapping, or relying on process to capture CI's, you should always ensure that the CI Class owners are well defined and that they regularly review the CI's that they own to validate the lists and ensure that the correct relationships are captured. By distributing the responsibility, the workload for CMDB Admins is reduced and the owners can no longer complain that the data is not accurate because it's their own fault. The CMDB Dashboards are great for keeping an eye on that too 🙂
So as per the above post, it's possible but so much more effort is required for a lower quality result.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-18-2019 08:10 AM
Agree 1000%. And your points about distributing the load of ownership (CI / classes / services, etc.) is spot on -- by putting ownership and responsibility in the hands of the people who have the strongest interest, this keeps data quality higher and therefore usefulness of the CMDB increases. Automation via Discovery is by far the best way to keep the core infrastructure data updated IMHO 🙂
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-20-2020 04:52 PM
Yes it is absolutely doable 🙂
I am building a CMDB basically from scratch without ServiceNow Discovery.
I do use MDR (Main Data Repositories) that I import into ServiceNow with a scheduled import.
If you are on Orlando then this feature looke really cool: https://youtu.be/YvsCY0M7JLw
You have to get into CI Class manager and start exploring all the classes and the subclasses that you need.
There multiple paths to take, but start simple..
Start from asset management and get your hardware created correctly (through Asset Management and Procurement). When you got the hardware done, then go on to virtual servers.
Underneath I have drawn an example of the CMDB for a Hyper-V topology.
Each box should have its own CI in the CMDB, however for assets you should create them first.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
If you would like to know more about assets and models (very important) I can recommend these articles:
https://community.servicenow.com/community?id=community_blog&sys_id=4fdd2ae9dbd0dbc01dcaf3231f9619ef
{kind=link}
{kind=link}