Laurent5

ServiceNow Employee
Options
- Post History
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
on 03-19-2021 10:14 AM
Working with customers on implementing classifications with Predictive Intelligence, a couple of questions that comes back often are “What is recall?" and "how do I use it?”.
Although there are many definitions and examples available online, I thought I’d build a little example using specifically a Service Management scenario.
But before we do, we first need to understand what a Confusion Matrix is. The aptly named Confusion Matrix is indeed… confusing!
At its most basic, a Confusion Matrix is a tool to help us understand how many of a given prediction turned out correct and how many did not.
By extension, it will help us measure metrics that will help us fine tune our model, depending on the outcome we want to achieve.
Let's say we want to use Predictive Intelligence to automatically assign the category of new incidents.
For illustration purposes, let's imagine we want to focus on 2 categories, Network and Security.
Now, if the category was assigned manually before, chances are a human might get it right 80% of the time, that is for every 100 incidents, they will assign the correct category 80 times, and for 20 they will get it wrong.
For example, today we have 100 incidents that have been raised.
28 security incidents
72 network incidents
An agent might do the following:
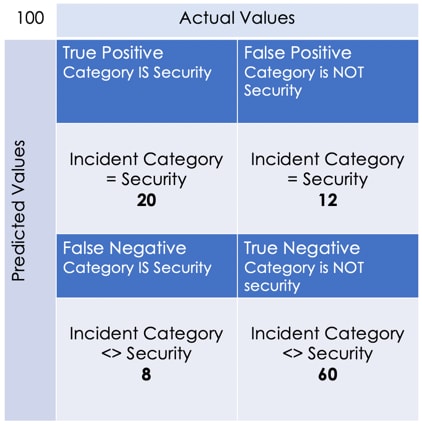
Correctly Categorise 20 as security incidents (True Positive, TP)
Correctly Categorise 60 as network incidents (True Negative, i.e NOT security incident, TN)
Mis-categorise 12 network incidents as security (False Positive, FP)
Mis-categorise 8 security incidents as network (False Negative, FN)
So the agent assigned correctly 80 out of the 100 incidents, and “missed” 20.
Now if we look at the 20 that were incorrectly categorised, 12 were categorised as security incidents when in fact they were network incidents (the False Positive) and 8 were categorised as network incidents when they were in fact security incidents (the False Negative)
Now, which do you think has the biggest business impact?
You could argue that categorising network incidents as security will not have a dramatic impact, but what about missing security incidents where time is critical?
The Confusion Matrix provides us with a representation of our predictions vs the actual. An example could look like this:

So, how do we measure these various scenarios?
That is when Precision and Recall come into play.
Precision is the measure of the % of records for which a correct prediction will be made, i.e it is indeed a security incident.
Its formula is
TP
TP + FP
Recall is the measure of the % of records for which a prediction will be made (including false negatives)
Its formula is
TP
TP + FN
So, in our little scenario, below would be the calculations:
Precision = TP/TP + FP = 20/(20+12) = .625
Recall = TP/TP + FN = 20/(20 + 😎 = .714
If the opposite had happened, i.e more security incidents were mis-categorised as network (i.e, we missed more security incidents), the metrics would be:
Precision = TP/TP + FP = 20/(20+8) = .714
Recall = TP/TP + FN = 20/(20 + 12) = .625
So as you can see, as the number of False Negative increases, Precision goes up and Recall goes down.
Conversely, if we decrease the number of False Negatives, Recall will go up.
We can think of it as a sensitivity threshold. If we set it high, only actual security incidents will be assigned to the Security category but some might be missed and be wrongly assigned to the Network Category. If we set it lower, we will catch all security incidents but we might also include some Network incidents.
In simple terms, higher Precision = less False Positives, higher Recall = less False Negatives!
Which is more desirable is entirely up to you depending on the outcome you want to achieve.
I hope the examples above haven’t left you more confused! Please feel free to share your thoughts in the comments!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- 3,129 Views