Shifting AI Security to the Left: Design-Time Defenses to Mitigate the Risks of Prompt Injections
Résumé
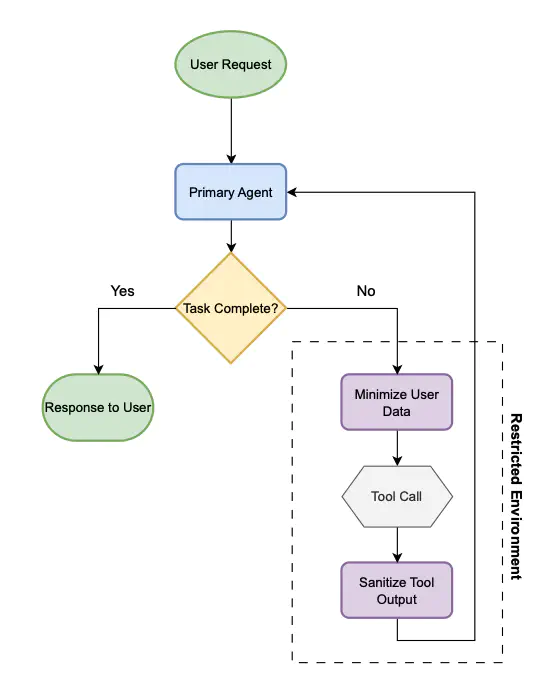
Prompt injections pose a critical weakness for modern Large Language Models, making it difficult for AI to distinguish between legitimate and malicious instructions. This vulnerability has significant implications for customers using AI on the ServiceNow platform. We present a case study on the Security Operations Now Assist (SecOps). This case study highlights how prompt injections can manipulate AI recommendations in SecOps. In this paper, we explore two complementary defense strategies against prompt injections—each representing a distinct form of airgapping, a security design pattern that isolates critical logic from potentially compromised model behavior. First, we introduce a strict airgapping approach using redaction-based preprocessing tailored to the structured nature of SecOps. By converting third-party inputs into structured representations, this method blocks all observed attacks while preserving recommendation quality. Second, we present a soft airgapping architecture for tool-using agents, inspired by dual-LLM and AirGap frameworks. It combines a minimizer to redact sensitive inputs, a quarantined LLM for isolated tool use, and a firewall LLM to sanitize outputs. This layered design restricts unsafe information flow while maintaining agent utility. Together, these strategies demonstrate that both strict and soft airgapping can reduce the attack surface of LLM-integrated systems. We advocate for a shift-left security approach, embedding these defenses early in the development lifecycle.
Abhay Puri
Applied Research Scientist
Applied Research Scientist at AI Research Deployment located at Montreal, QC, Canada.
Kiarash Mohammadi
Applied Research Scientist
Applied Research Scientist at AI Research Deployment located at Montreal, QC, Canada.
Georges Belanger Albarran
Applied Research Scientist
Applied Research Scientist at AI Research Deployment located at Montreal, QC, Canada.
Mihir Bansal
Machine Learning Engineer
Machine Learning Engineer at AI Research Deployment located at Santa Clara, CA, USA.
Marc-Etienne Brunet
Research Lead
Research Lead at AI Research Deployment located at Toronto, ON, Canada.
Jason Stanley
Head of AI Research Deployment
Head of AI Research Deployment at AI Research Deployment located at Montreal, QC, Canada.