Data Augmentation for Intent Classification with Off-the-shelf Large Language Models
Résumé
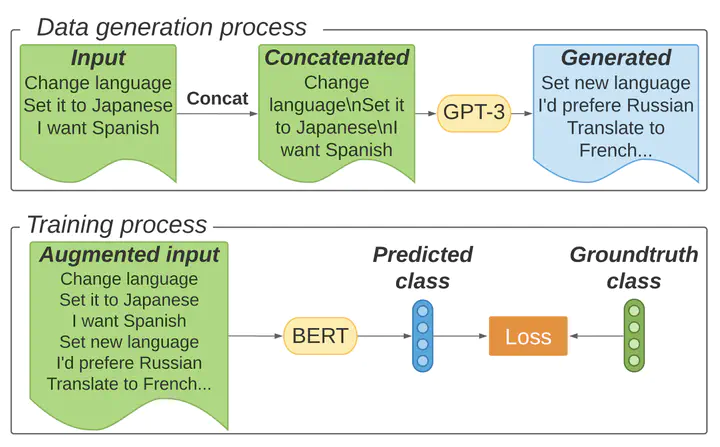
Data augmentation alleviates the problem of data scarcity when training language models (LMs) by generating new examples based on the existing data. A successful approach to generate new samples is to fine-tune a pretrained LM on the task-specific data and then sample from the label-conditioned LM. However, fine-tuning can be difficult when task-specific data is scarce. In this work, we explore whether large pretrained LMs can be used to generate new useful samples without fine-tuning. For a given class, we propose concatenating few examples and prompt them to GPT-3 to generate new examples. We evaluate this method for few-shot intent classification on CLINC150 and SNIPS and find that data generated by GPT-3 greatly improves the performance of the intent classifiers. Importantly, we find that, without any LM fine-tuning, the gains brought by data augmentation with GPT-3 are similar to those reported in prior work on LM-based data augmentation. Experiments with models of different sizes show that larger LMs generate higher quality samples that yield higher accuracy gains.
Issam H. Laradji
Research Scientist
Research Scientist at Agent Contextualization located at Vancouver, Canada.