Résumé
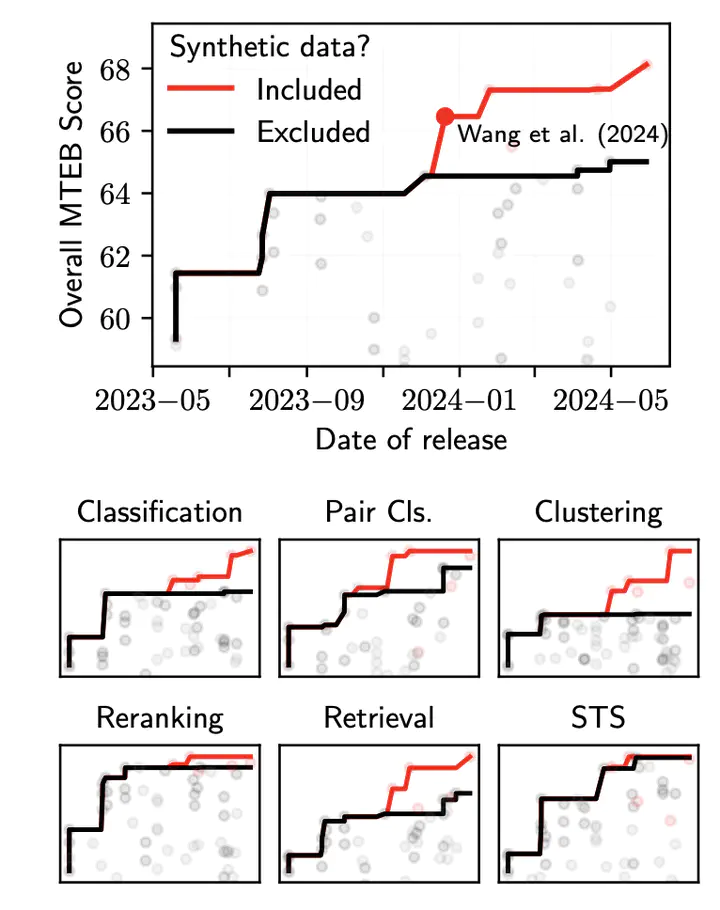
Recent progress in developing general-purpose text embedders has been driven by training on synthetic LLM-generated data. Nonetheless, no publicly available synthetic data exists, posing a barrier to studying its role for the generalization of embedding models. To address this issue, we first reproduce and publicly release the synthetic data proposed by Wang et al. (2024) (Mistral-E5). Our synthetic data is high quality and leads to consistent improvements in performance. Next, we critically examine where exactly synthetic data improves model generalization. Our analysis reveals that benefits from synthetic data are sparse and highly localized to individual datasets. Moreover, we observe trade-offs between the performance on different categories and data that benefits one task, degrades performance on another. Our findings highlight the limitations of current synthetic data approaches for building general-purpose embedders and challenge the notion that training on synthetic data leads to more robust embedding models across tasks.
Siva Reddy
Research Scientist
Research Scientist at AI Research Partnerships & Ecosystem located at Montreal, Canada.