Reinforcement Learning

A popular approach for sequential decision-making is to perform simulator-based search
guided with Machine Learning (ML) methods like …

Reinforcement Learning via Supervised Learning (RvS) only uses supervised techniques to learn desirable behaviors from large datasets. …
Inducing causal relationships from observations is a classic problem in machine learning. Most work in causality starts from the …

Action and observation delays commonly occur in many Reinforcement Learning applications, such as remote control scenarios. We study …
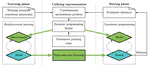
Combinatorial optimization has found applications in numerous fields, from aerospace to transportation planning and economics. The goal …

In multi-agent reinforcement learning, discovering successful collective behaviors is challenging as it requires exploring a joint …
As deep reinforcement learning driven by visual perception becomes more widely used there is a growing need to better understand and …
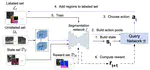
Learning-based approaches for semantic segmentation have two inherent challenges. First, acquiring pixel-wise labels is expensive and …
Reward Machines (RMs) provide a structured, automata-based representation of a reward function that enables a Reinforcement Learning …
Markov Decision Processes (MDPs), the mathematical framework underlying most algorithms in Reinforcement Learning (RL), are often used …