Multilingual Code Retrieval Without Paired Data: A New Benchmark and Experiments
Abstract
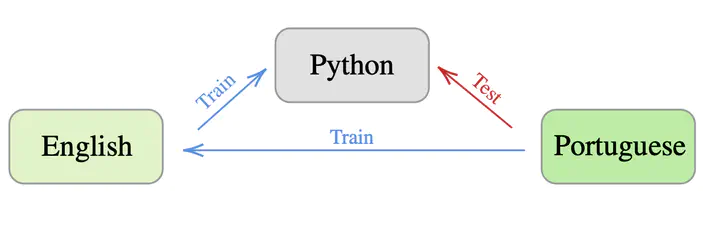
We seek to overcome limitations to code retrieval quality posed by the scarcity of data containing pairs of code snippets and natural language queries in languages other than English. We correspondingly test the following hypothesis: if a model can map from English to code, and from other natural languages to English, then how well can the model directly map from those non-English languages into representations of code? To do so, we introduce two new datasets. For training models, we build a corpus corresponding to paired English/Code data and combine it with existing translation datasets given by pairs of English and other natural languages. For evaluation, we make a new benchmark available, dubbed M2CRB, containing pairs of text and code, for multiple natural and programming language pairs - namely: Spanish, Portuguese, German, and French, each paired with code snippets for: Python, Java, and JavaScript. Evaluation on both our new benchmark tasks as well as on an existing code-to-code search task confirms our hypothesis: models are able to generalize to unseen source/target language pairs they indirectly observed during training. We examine models which both generate and retrieve natural and programming languages and through ablations, we further verify the influence of different design choices and training tasks in terms of whether or not they contribute to generalization with unseen language pairs.
Christopher Pal
Distinguished Scientist
Distinguished Scientist at AI Research Partnerships & Ecosystem located at Montreal, Canada.