- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-23-2018 01:20 PM
We are going through an implementation Event Management, and an open question is how to deal with outages that cause many incidents that may or may not be indicative of the root cause.
Our implementation will be quite simple at the onset:
- An event source will create events
- Those events will have event rules that create alert(s)
- Those alerts will mostly only have one action which is to create incidents
Scenario: A widespread outage where there is a network component, for example, down causing many downstream servers to be down as well. There is nothing wrong with the servers themselves other than being down because of the aforementioned network component. Many incidents will be generated - one for the network component and many for each server being down.
The specific question was posed: Given the above scenario this may be madness for our ops team managing a ballooning number of incidents. Is there an alternate way of handling this either using the machine learning engine or through more complex event rules to correlate these alerts to each other so that ServiceNow knows one is causing the other. The goal would be not to have to manage an exorbitant amount of incidents in this case. Thoughts?
Thanks in advance!
Scott
Solved! Go to Solution.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-24-2018 08:00 PM
Hi Scott,
You will need to configure an Alert Correlation Rule to ensure that only the causal alert is classified as a primary alert and the symptomatic alerts are classified as secondary alerts. You begin by first determining the criteria for identifying the primary and secondary alerts. For example, if the alerts are bound to CIs you can use the Configuration item.Class related field to check if the alert's CI is an IP Router. You might then include the alert's Type or Description field in the Primary alert condition to further match the primary alert. In the Secondary alert condition, you could use the Configuration item.Class related field to check if the alert's CI is a Server (or relevant CI class), and again use other fields to ensure you'll correlate the correct alerts.
You can also leverage relationships between CIs in the CMDB (see example in Create an alert correlation rule), so provided Alerts are bound to CIs and the CIs are related (e.g. you're using Discovery and have dependency relationships in the CMDB) you can specify a Relationship type, and then choose the relevant Relationship (Hint: find the Router CI in the CMDB, check the dependency map, and hover over a relationship link e.g. Depends on: Used By).

Using the example above, you'd select Primary is Parent for the Relationship type and then choose Depends on::Used by as the Relationship.
You can also set the Time difference to limit the window in which the rule can be applied to alerts arriving (default is 60 minutes).
The Alert Correlation Rule ends up looking like this:

You can also extend the example above to cater to other CI classes - use the OR operator for the Configuration item.Class field in the Secondary Alert condition.
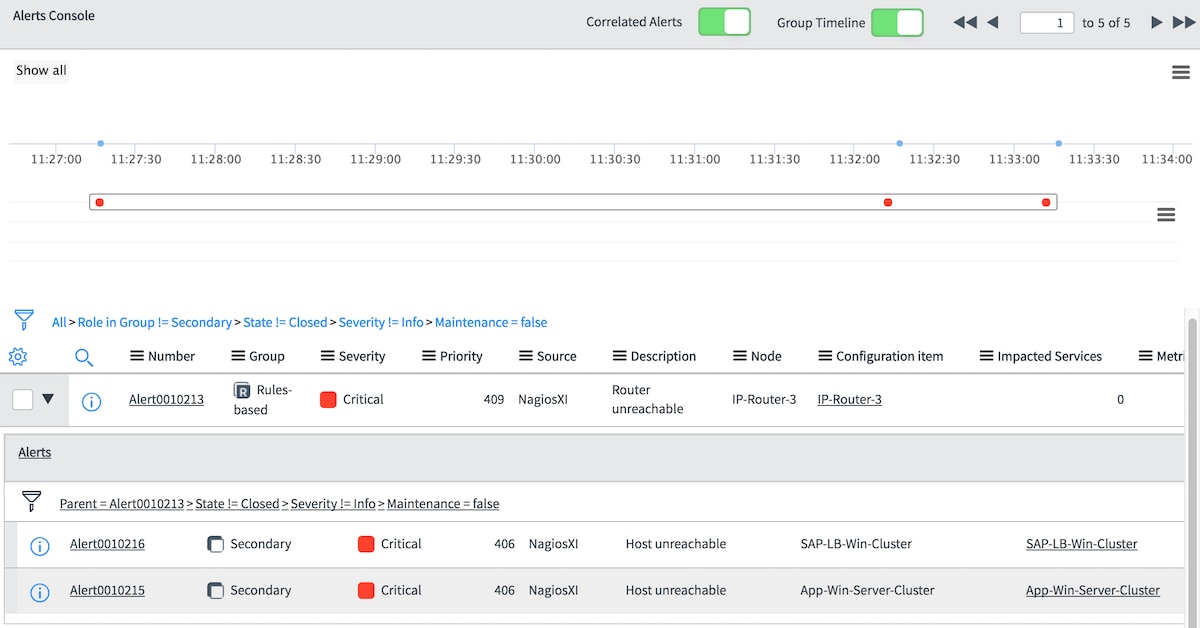
Now when an event arrives for the router and is followed within 60 minutes by another event for the Windows cluster (in this example), the Windows cluster alerts will be correlated to the router alert:

The final step is to create an Alert Action Rule and configure the filter condition to only create an Incident for an alert where the Role in Group field is set to Primary. You may also need to set the Order field to ensure the rule is triggered before other Alert Action Rules that may also create Incidents for alerts that are not using the Role in Group field.
An alternative to using Alert Correlation Rules is to use the Alert Aggregation feature in Event Management. This takes a machine-learning based approach to correlating alerts, using time-based analysis of alerts to create Automated alert groups and also CI relationships to create CMDB alert groups. This requires a dedicated MID Server to perform the processing and will require you to review and provide feedback on the initial grouping results so the learned patterns can be refined. Note that if you use this approach, you would still configure an Alert Action Rule as mentioned above.
Hope this helps.
{kind=link}
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-24-2018 08:00 PM
Hi Scott,
You will need to configure an Alert Correlation Rule to ensure that only the causal alert is classified as a primary alert and the symptomatic alerts are classified as secondary alerts. You begin by first determining the criteria for identifying the primary and secondary alerts. For example, if the alerts are bound to CIs you can use the Configuration item.Class related field to check if the alert's CI is an IP Router. You might then include the alert's Type or Description field in the Primary alert condition to further match the primary alert. In the Secondary alert condition, you could use the Configuration item.Class related field to check if the alert's CI is a Server (or relevant CI class), and again use other fields to ensure you'll correlate the correct alerts.
You can also leverage relationships between CIs in the CMDB (see example in Create an alert correlation rule), so provided Alerts are bound to CIs and the CIs are related (e.g. you're using Discovery and have dependency relationships in the CMDB) you can specify a Relationship type, and then choose the relevant Relationship (Hint: find the Router CI in the CMDB, check the dependency map, and hover over a relationship link e.g. Depends on: Used By).
Using the example above, you'd select Primary is Parent for the Relationship type and then choose Depends on::Used by as the Relationship.
You can also set the Time difference to limit the window in which the rule can be applied to alerts arriving (default is 60 minutes).
The Alert Correlation Rule ends up looking like this:
You can also extend the example above to cater to other CI classes - use the OR operator for the Configuration item.Class field in the Secondary Alert condition.
Now when an event arrives for the router and is followed within 60 minutes by another event for the Windows cluster (in this example), the Windows cluster alerts will be correlated to the router alert:
The final step is to create an Alert Action Rule and configure the filter condition to only create an Incident for an alert where the Role in Group field is set to Primary. You may also need to set the Order field to ensure the rule is triggered before other Alert Action Rules that may also create Incidents for alerts that are not using the Role in Group field.
An alternative to using Alert Correlation Rules is to use the Alert Aggregation feature in Event Management. This takes a machine-learning based approach to correlating alerts, using time-based analysis of alerts to create Automated alert groups and also CI relationships to create CMDB alert groups. This requires a dedicated MID Server to perform the processing and will require you to review and provide feedback on the initial grouping results so the learned patterns can be refined. Note that if you use this approach, you would still configure an Alert Action Rule as mentioned above.
Hope this helps.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-25-2018 05:35 AM
Wow. Thank you so much for the detailed response. Although, we are not at a point in the project where we can implement this yet, it will be extremely helpful to understand conceptually how SN handles these scenarios.
Cheers!
Scott