Implications of changing reference key
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-10-2014 04:41 PM
There is documentation that indicates (in Calgary and above) we can change a reference key for a reference column, as noted here:
Defining the Reference Key
By default, reference fields store the sys_id of the record in the database. By defining a reference key, you can identify a field other than sys_id to use as the unique identifier for the reference field. The value of the reference key field, instead of the sys_id, is stored in the database for that reference field. (Calgary release)
- Navigate to System Definition > Dictionary.
- Open the field record (for example, resolved_by" on the Incident table).
- In the Reference key field, enter a field name on the referenced table (for example, email on the sys_user table).
- Note: Always choose a field from the referenced table that is both required and unique.
- Click Update.
I understand that this is changing the underlying primary key reference, i.e. sys_id is no longer used as the unique identifier for the table. I understand why someone might want to do this but it seems like it would be a really bad idea to do on any deployment where you have existing data. It would take some careful planning and perhaps some export/import operations to keep things from breaking.
My question is this: has anyone ever tried to do this, and what were the circumstances and outcome?
Earl
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-03-2015 12:21 PM
So in the example you gave, you want to change the Reference key from seeing the Username who resolved the ticket to their email address? That's the result if you change the key.
What are you trying to accomplish? Maybe there is another way as my recommendation is to not change the key.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-03-2015 12:54 PM
Actually the example in my original post is directly from the documentation, it's not my example. All I was pointing out is that the documentation says it's possible and probably useful sometimes to change the reference key. And I'm trying to do just that.
What I'm trying to do is bring in data from another application, and there are several tables in that application that are all already related in my source database. What I need to be able to do is ensure that these existing table relationships are maintained once that data is imported into a new set of tables in SN.
To complicate things just a little bit, my application has several many-to-many relationships and of course I'm going to want to be able to setup the appropriate views into those "M2M" relationships so my users don't lose any functionality when this app is moved into SN.
For some context, I'm working with IP networks (subnets) in the CMDB. Right now we have a homegrown app that has the capability of assigning many contacts to each subnet. This is so that if we can't reach one contact for a particular subnet (when things go wrong, or we have questions, etc) then we have other contacts that we can reach out to. And the contacts can be different types (management, system admins, LAN admins, etc).
The way I understand the cmdb_ci_* tables, they all have an assignment column and you can assign one CI (in this case a subnet) to one person. This isn't going to cut it for our use case. Thus I'm wanting to supplement that CI info with additional contacts, like our source application has today. Thus, the "M2M" relationship, where each subnet can have many contacts and each contact can have many subnets. All of this works perfectly well in my source application (done in Oracle).
Here's what I've done so far (in a development sandbox):
Created two new tables, one for the M2M relationship and one for the network contacts.
Added one column to the IP networks table, so I can put my original subnet reference ID in it.
Created import sets and transform maps for three tables, the two above and one more for the built-in IP networks table.
Successfully imported and transformed into the target tables for the IP networks and the contacts, but not the M2M table.
There seem to be two distinct aspects of this and they probably need to be addressed separately. First is the definition of the reference columns in my M2M table. Is is sufficient to just say that a column is a reference to the target table and leave the reference key alone? My impression is that if you do this then the default will be to use the sys_id, which I don't want. I want my source system reference ID to be what is used to join the "one sides" of the M2M relationship.
The second part has to do with the transform mapping definition and how that is handled when a transform occurs. When you're importing into a reference column you have the option of specify a reference field for the table. So again, is it sufficient just to do this, without changing the reference key on the M2M column definitions, and will that give me what I need? So far the answer seems to be no.
If it's possible to have someone login to my development instance I'd be glad to set that up and let you have a look around to see if you can see anything that's amiss with my approach.
Earl
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-03-2015 01:17 PM
I can tell you in 4 yrs of doing SN, I've never changed the key once. I'm thinking changing the key could flag the dictionary entry for future updates to 'no'. Hence the reason I steered you away from changing it.
There are a lot of related lists available in SN. In the CMDB you could populate the 'assigned to' field, but that's one to one. In the related list User Relationships, you can define a primary and multiple secondary contacts.
For bringing data into SN quickly, check out Easy Import. The system will generate an excel spreadsheet for you. You populate the data, and import it in. done!
Not sure I answered all your questions, but maybe this info helps.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-03-2015 01:25 PM
Where is this "Easy Import" of which you speak? I don't find it when typing "easy" into the navigation filter.
Just curious, how much legacy application data, with existing relationships, have you had to import into SN? And how did you handle those existing relationships?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-03-2015 01:32 PM
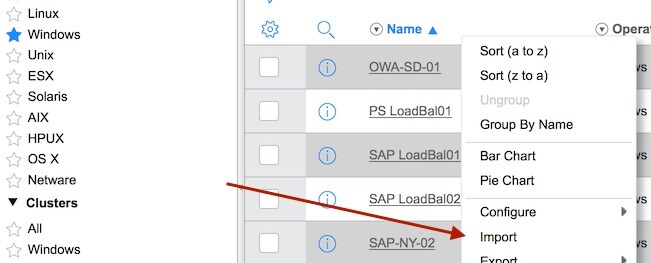
Right-click on column heading, Import is easy import. Example below is Windows cmdb.

I just recently finished a 9 month projecting doing what you're going through. It's time consuming, mapping every table. Some things just don't fit into anything! But you can't make the new look like the old. If you are going to do that, don't switch.
{kind=link}