




Bhanu Kiran

ServiceNow Employee
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
05-08-2020
08:10 AM
After troubleshooting and resolving several DataLoss cases for our customers, I and my co-workers thought why not write a blog and share with our customers so their production instances run seamlessly. DataLoss in specific is disruptive for Business and we would like to share more insights and few best practices to avoid DataLoss. That said, lets get into few best practices pertaining to DataLoss.
If you are looking for ways to prevent a DataLoss situation, here are few ServiceNow / ITIL Best Practices
Here's the thing: no one wants to delete their data from Production intentionally. I’ll bet you it's because of the Cascade delete rules or a Bad Query in the Script. It ends up being most painful when the instance gets to an unusable state for the end-users because of no data in the instance (tables).
When does a DataLoss occur?
- Cascade delete rules:
Do you know that as per the cascade delete rules configured, the related data may or may not be deleted? That sounds interesting, isn’t it!! It's very important to review the cascade delete rules before any data is deleted.
Here is some helpful documentation on Configuring Cascade Rules:
- Bad Query in the Script:
One of the common ways to manipulate data is through scripts. But if the query in the script is not correct, then it might end up manipulating all the data that is unintended to be deleted. In order to avoid this problem, we can check the number of records that will be processed with the query in the script before actually deleting the records.
An incorrectly constructed encoded query, such as including an invalid field name or a spelling error produces an invalid query. When the invalid query is run, the invalid part of the query condition is dropped, and the results are based on the valid part of the query, which may return all records from the table. Using an insert(), update(), deleteRecord(), or deleteMultiple() method on bad query results can result in data loss.
Caution: If you are manipulating the data using deleteMultiple() or updateMultiple(), make sure the script is not in a loop.
Lets understand the above with an example:
In the above scenario, the script would wrongly update all the records because of a spelling error in the 2nd line. This scenario could be avoided by doing a test run with the below script:
var count = 0;
var test = new GlideRecord('problem');
test.addEncodeddQuery('active=true');
test.query();
while(test.next()){
count++
test.active =false;
//test.update();
}
gs.print("Number of records : " + count);
If you are manipulating the data through a script, always have a test run with a confirmation on how many records will be manipulated. You can use getRowCount method for the same.
What are our alternatives for Deleting the Data?
Below are few techniques we would like to suggest from ServiceNow while we are sure you may have few others:
What are those unexpected consequences of Delete Operation?
Cascade Deletions
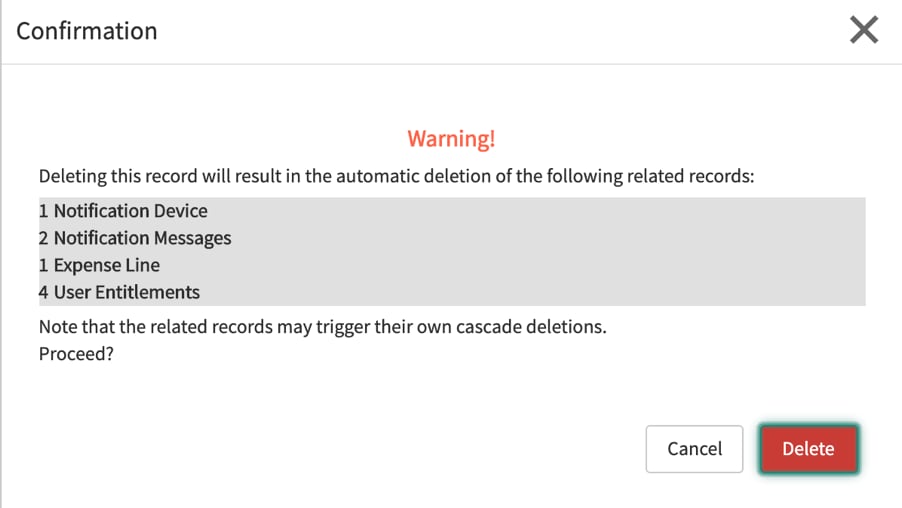
For example, when a Configuration Item record is deleted, all tasks referencing that CI are also deleted. To help us understand that a cascade delete is going to be executed, a Warning Message is displayed to the user. It captures all the tables where data will be deleted.
- Administrators and Developers should be able to recognize and understand the implications of that Warning message.
- Developers should keep in mind, the deletion activity will be added to the update set and will be promoted to production where it will delete all records that match the deletion criteria.
Here is a real-time example of Cascade Delete:
Unexpected Consequences when Catalog Variables are Deleted
References
When a single record is deleted, hundreds or even thousands of other records will be updated to remove any references to the deleted record. This is the most common scenario we see with almost all the data loss cases. The best policy is that data should never be deleted from the platform, whether it is through the UI or through a script. Use the Active Flag rather.
Workflows, Approvals & SLA’s
These are usually tied to task-type records. Unintended deletions can update them incorrectly. There is no direct method to correct these straight away. It requires multiple tables to be restored to bring the data back to the correct state. Manual restoration is followed with the help of SOT instances (scroll down to the end on what SOT means) which is time-consuming.
How do we recover the lost data?
If you are keen to track the deletes/ updates done on your instance and troubleshoot further before engaging us, please familiarize yourself with
Record Deletes/Updates, how to track, find and troubleshoot these issues.
Keep in mind to consider the references option as well when you undelete any record.
- Rollback and delete recovery
Starting from London, we have a new feature called Rollback and Delete Recovery which helps in restoring the data that has been manipulated. It is a more advanced version of the Undelete option. If you can find a related rollback context for your unintended data manipulation transaction, you can roll back the same. The tool is more advanced in New York and higher versions and you should be able to roll back directly in PROD.
Additional documentation can be found here:
- Restore a deleted record and its reference
Use this option with caution. The Delete Recovery option is always the quick, safest and best way to restore the data.
Additional documentation can be found here:
- Restore a deleted configuration record
If you were to run into this situation, contact Technical Support so they could best analyze and suggest the next steps before you start to do the restore yourselves.
Additional documentation can be found here:
Now, here comes a high-level insight into the restoration process followed by ServiceNow for Production instances.
A lot of you would have seen on your cases that we provision 2 new temporary instances
- One for a standard backup restore or 'Point in Time Restore' prior to the DataLoss to retrieve the missing/affected records. This will be referred to as the Source of Truth (SOT) instance. It will represent the state of the instance before the data manipulation occurred. This will be only available if the case is brought to our attention within 3 days of the DataLoss event.
- One to test the solution to restore data. This will be referred to as the Test Bed instance. This instance will be a copy of the affected PROD instance post deletion event.
By combing through the log files, we determine the exact time at which the data manipulation has occurred. This timestamp is used to request for the Point in Time Restore famously called as PIT instance. The time it takes to provision the two TEMP instances depends on your instance size. We have seen that instances which are too large take a day or more to get the TEMP instances provisioned.
Note: We do not restore data if DataLoss were to occur in a Sub-Prod instance.
Additional documentation can be found here:
- 2,026 Views
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}