BiXSE: Improving Dense Retrieval via Probabilistic Graded Relevance Distillation
Résumé
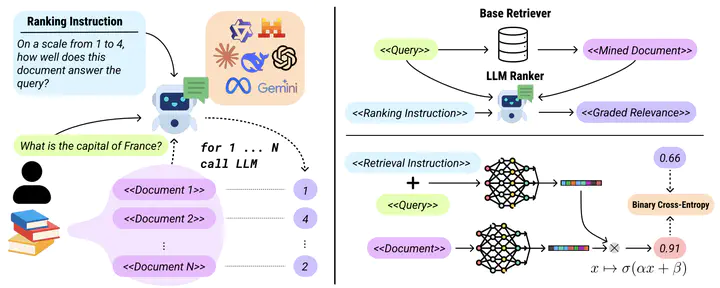
Neural sentence embedding models for dense retrieval typically rely on binary relevance labels, treating query-document pairs as strictly relevant or irrelevant. However, real-world retrieval tasks often distinguish among multiple grades of relevance. Training only based on binary relevance labels thus oversimplifies these nuanced relationships, leading to incomplete supervision and noisy datasets contaminated by false negatives. While obtaining large-scale annotated graded relevance data has traditionally been challenging and expensive, this process has been simplified using LLMs, paving the way for improved training methodologies.
In this work, we propose BiXSE, a simple yet effective method to train bi-encoders on graded-relevance query-document pairs. BiXSE optimizes the model to predict the relevance of query-document pair using binary cross-entropy (BCE) loss, effectively amortizing expensive LLM ranking costs into embedding models. Extensive experiments on sentence embedding (MMTEB) and retrieval benchmarks (BEIR & TREC-DL) demonstrate that BiXSE consistently outperforms the prevalent practice of using softmax-based contrastive learning objective (InfoNCE) across various base models. Furthermore, our analysis reveals that training with BCE improves robustness to label noise, and benefits from broader supervision without aggressive data filtering. Our findings affirm that with the newly achievable scalability of graded relevance supervision via LLMs, BiXSE provides a highly effective method to improve dense retrieval performance.