A Guide To Effectively Leveraging LLMs for Low-Resource Text Summarization: Data Augmentation and Semi-supervised Approaches
Résumé
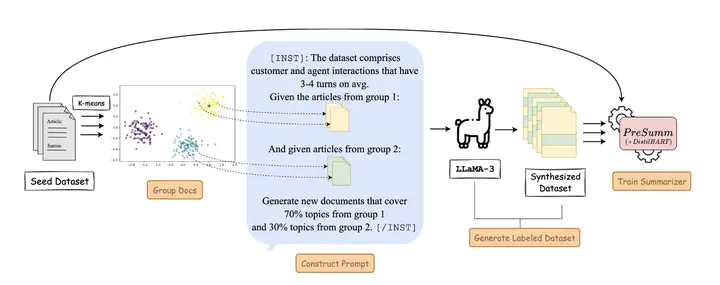
Existing approaches for low-resource text summarization primarily employ large language models (LLMs) like GPT-3 or GPT-4 at inference time to generate summaries directly; however, such approaches often suffer from inconsistent LLM outputs and are difficult to adapt to domain-specific data in low-resource scenarios. In this work, we propose two novel methods to effectively utilize LLMs for low-resource text summarization: \textbf{1)} {\method}, an LLM-based data augmentation regime that synthesizes high-quality documents (short and long) for \textit{few-shot text summarization}, and \textbf{2)} {\methodSSL}, a prompt-based pseudolabeling strategy for sample-efficient \textit{semi-supervised text summarization}. Specifically, {\method} leverages the open-source {\lmodel} model to generate new documents by mixing topical information derived from a small seed set, and {\methodSSL} leverages the {\lmodel} model to generate high-quality pseudo-labels in a semi-supervised learning setup. We evaluate our methods on the TweetSumm, WikiHow, and ArXiv/PubMed datasets and use L-Eval, a LLaMA-3-based evaluation metric, and ROUGE scores to measure the quality of generated summaries. Our experiments on extractive and abstractive summarization show that {\method} and {\methodSSL} achieve competitive ROUGE scores as a fully supervised method with 5% of the labeled data~\footnote{We will open-source our code upon acceptance for reproducibility.
Issam H. Laradji
Research Scientist
Research Scientist at Agent Contextualization located at Vancouver, Canada.