Few-Shot Learning
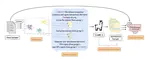
Existing approaches for low-resource text summarization primarily employ large language models (LLMs) like GPT-3 or GPT-4 at inference …
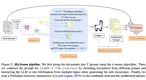
Low-resource extractive text summarization is a vital but heavily underexplored area of research. Prior literature either focuses on …
Data augmentation is a widely used technique to address the problem of
text classification when there is a limited amount of training …

Large pre-trained models have proved to be remarkable zero- and (prompt-based) few-shot learners in unimodal vision and language tasks. …

Agents that can learn to imitate given video observation – without direct access to state or action information are more …
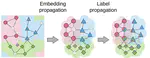
Supervised training of neural networks requires a large amount of manually annotated data and the resulting networks tend to be …
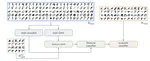
In this paper, we explore the use of GAN-based few-shot data augmentation as a method to improve few-shot classification performance. …
Labeling data is often expensive and time-consuming, especially for tasks such as object detection and instance segmentation, which …

Progress in the field of machine learning has been fueled by the introduction of benchmark datasets pushing the limits of existing …
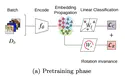
Few-shot classification is challenging because the data distribution of the training set can be widely different to the test set as …