Causal Differentiating Concepts: Interpreting LM Behavior via Causal Representation Learning
Résumé
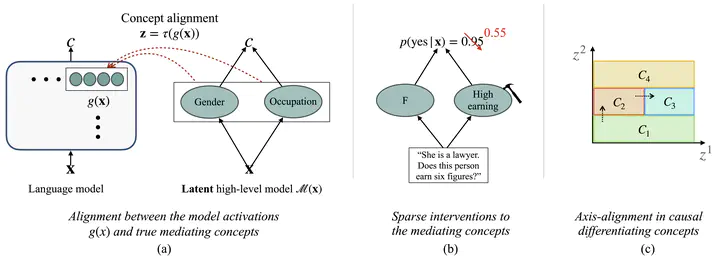
Language model activations entangle concepts that mediate their behavior, making it difficult to interpret these factors, which has implications for generalizability and robustness. We introduce an approach for disentangling these concepts without supervision. Existing methods for concept discovery often rely on external labels, contrastive prompts, or known causal structures, which limits their scalability and biases them toward predefined, easily annotatable features. In contrast, we propose a new unsupervised algorithm that identifies causal differentiating concepts—interpretable latent directions in LM activations that must be changed to elicit a different model behavior. These concepts are discovered using a constrained contrastive learning objective, guided by the insight that eliciting a target behavior requires only sparse changes to the underlying concepts. We formalize this notion and show that under a particular assumption about the sparsity of these causal differentiating concepts, our method learns disentangled representations that align with human-interpretable factors influencing LM decisions. We empirically show the ability of our method to recover ground-truth causal factors in synthetic and semi-synthetic settings. Additionally, we illustrate the utility of our method through a case study on refusal behavior in language models. Our approach offers a scalable and interpretable lens into the internal workings of LMs, providing a principled foundation for interpreting language model behavior.
Alexandre Drouin
Head of Frontier AI Research
Head of Frontier AI Research at AI Research Leadership located at Montreal, Canada.