Unifying Autoregressive and Diffusion-Based Sequence Generation
Résumé
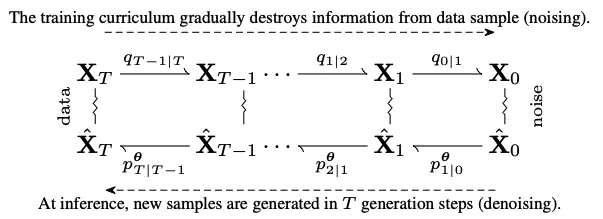
We present significant extensions to diffusion-based language models, blurring the line with autoregressive ones. We introduce hyperschedules, which assign distinct noise schedules to individual token positions, generalizing both autoregressive models (e.g., GPT) and conventional diffusion models (e.g., SEDD, MDLM) as special cases. Other innovations enable the model to fix past mistakes, and our attention masks allow for efficient training and inference (e.g., KV-caching). Our methods achieve state-of-the-art perplexity and generate diverse, high-quality sequences across standard benchmarks, suggesting a promising path for autoregressive diffusion-based language modeling.
Pierre-André Noël
Research Scientist
Research Scientist at Frontier AI Research located at Montreal, QC, Canada.