Using Scaling Laws for Data Source Utility Estimation in Domain-Specific Pre-Training
Résumé
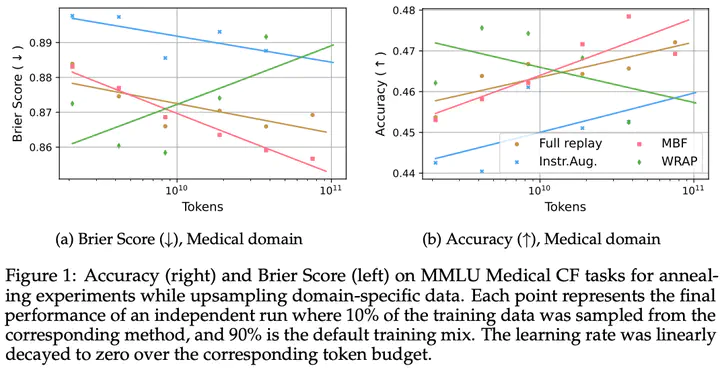
We introduce a framework for optimizing domain-specific dataset construction in foundation model training. Specifically, we seek a cost-efficient way to systematically allocate resources to data sources (e.g. synthetically generated or filtered web data, etc.) for the stage two pre-training phase, aka annealing, in order to specialize a generalist pre-trained model to specific domains. Our approach extends the usual point estimate approaches, aka micro-annealing, to estimating scaling laws by performing multiple annealing runs of varying compute spent on data curation and training. This addresses a key limitation in prior work, where reliance on point estimates for data scaling decisions can be misleading due to the lack of rank invariance across compute scales — a phenomenon we confirm in our experiments. By systematically analyzing performance gains relative to acquisition costs, we find that scaling curves can be estimated for different data sources. Such scaling laws can inform cost effective resource allocation across different data acquisition methods and available compute resources. We validate our approach through experiments on a pre-trained model with 7 billion parameters. We adapt it to: a domain well-represented in the pre-training data — the medical domain, and a domain underrepresented in the pretraining corpora — the math domain. We show that one can efficiently estimate the scaling behaviours of a data source by running multiple annealing runs, which can lead to different conclusions, had one used point estimates using the usual micro-annealing technique instead. This enables data-driven decision-making for selecting and optimizing data sources.
Oleksiy Ostapenko
Research Scientist
Research Scientist at Model Readiness located at Montreal, Canada.
Luke Kumar
Applied Research Scientist
Applied Research Scientist at Agentic Harness & Defenses located at Toronto, Canada.
Joel Lamy Poirier
Applied Research Scientist
Applied Research Scientist at Model Readiness located at Montreal, Canada.
Sébastien Paquet
Research Lead
Research Lead at Agent Contextualization located at Montreal, Canada.