Résumé
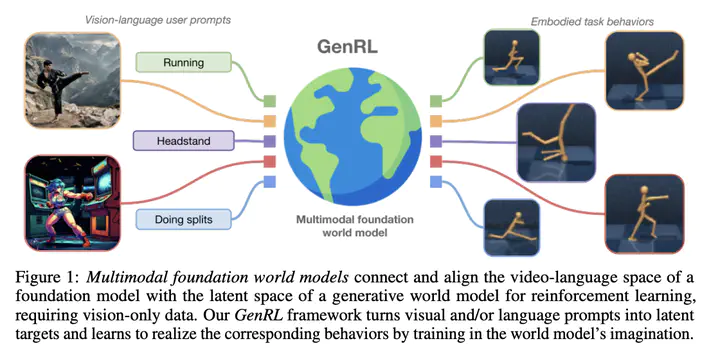
Learning generalist agents, able to solve multitudes of tasks in different domains is a long-standing problem. Reinforcement learning (RL) is hard to scale up as it requires a complex reward design for each task. In contrast, language allows specifying tasks in a more natural way, but the lack of multimodal data in embodied domains represents an obstacle toward developing foundation models for embodied applications, and current foundation vision-language models (VLMs) generally require domain-specific fine-tuning or prompt engineering techniques to be functional. In this work, we overcome these problems by presenting multimodal foundation world models, able to connect and align the representation of foundation VLMs with the latent space of generative world models for RL using unimodal vision-only. The resulting agent learning framework, GenRL, allows specifying tasks through vision and/or language prompts, grounding them in the embodied domain’s dynamics, and learning the corresponding behaviors in imagination. As assessed through a large-scale multi-task benchmarking, GenRL exhibits strong multi-task generalization performance in several locomotion and manipulation domains, and it enables great reusability of the agent’s component, by introducing a data-free RL strategy, laying the groundwork for generalist agents and foundation models in embodied domains.