Reinforcement Learning
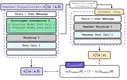
Training-time privileged information (PI) can enable language models to succeed on tasks they would otherwise fail, making it a …

I present diffusion models as part of a family of machine learning techniques that withhold information from a model’s input and train …

In order to be deployed safely, Large Language Models (LLMs) must be capable of dynamically adapting their behavior based on their …
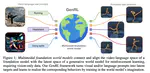
Learning generalist agents, able to solve multitudes of tasks in different domains is a long-standing problem. Reinforcement learning …

The ability to predict outcomes of interactions between embodied agents and objects is paramount in the robotic setting. While …

In order to safely deploy Large Language Models (LLMs), they must be capable of dynamically adapting their behavior based on their …
Target networks are at the core of recent success in Reinforcement Learning. They stabilize the training by using old parameters to …

In the presence of confounding, naively using off-the-shelf offline reinforcement learning (RL) algorithms leads to sub-optimal …
Controlling artificial agents from visual sensory data is an arduous task. Reinforcement learning (RL) algorithms can succeed but …