WebMMU: A Benchmark for Multimodal Multilingual Website Understanding and Code Generation
Résumé
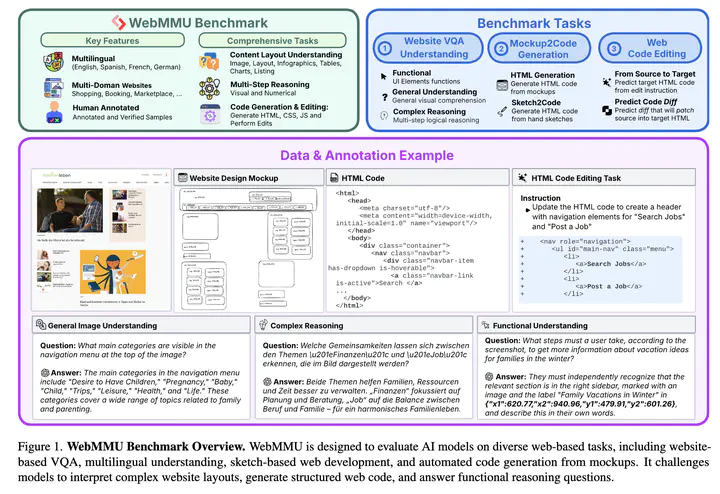
Understanding diverse web data and automating web development presents an exciting challenge for agentic multimodal models. While existing benchmarks address isolated web-based tasks such as website-based Visual Question Answering (VQA) and UI-to-code generation, they lack a unified evaluation suite for assessing web agents that interact with and reason about web environments. We introduce WebMMU, a large-scale benchmark for evaluating web agents across multilingual website understanding, HTML/CSS/JavaScript code editing, and mockup-to-code generation. WebMMU provides a comprehensive evaluation suite with real-world website data, multi-step reasoning tasks, and functional UI understanding. Benchmarking state-of-the-art multimodal models on \benchmark{} reveals significant limitations in web-based reasoning, layout understanding, and structured code generation, particularly in preserving UI hierarchy, handling multilingual content, and producing robust and functional code. While existing models are optimized for English settings, WebMMU highlights the challenges of cross-lingual adaptation in real-world web development. These findings expose critical gaps in current models’ ability to understand website structures, execute user instructions, and generate high-quality web code, underscoring the need for more advanced multimodal reasoning in AI-driven web understanding and development.
Christopher Pal
Distinguished Scientist
Distinguished Scientist at AI Research Partnerships & Ecosystem located at Montreal, Canada.
Spandana Gella
Research Lead
Research Lead at Agentic Harness & Defenses located at Montreal, Canada.