Optimization
Block coordinate descent (BCD) methods are widely used for large-scale numerical optimization because of their cheap iteration costs, …

We propose a stochastic variant of the classical Polyak step-size (Polyak, 1987) commonly used in the subgradient method. Although …
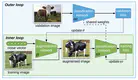
Data augmentation is a key practice in machine learning for improving generalization performance. However, finding the best data …
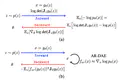
Entropy is ubiquitous in machine learning, but it is in general intractable to compute the entropy of the distribution of an arbitrary …

We consider stochastic second-order methods for minimizing smooth and strongly-convex functions under an interpolation condition …

Generative adversarial networks have been very successful in generative modeling, however they remain relatively challenging to train …
Recent works have shown that stochastic gradient descent (SGD) achieves the fast convergence rates of full-batch gradient descent for …

We study the effect of the stochastic gradient noise on the training of generative adversarial networks (GANs) and show that it can …
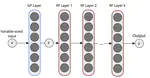
Deep Gaussian processes (DGP) have appealing Bayesian properties, can handle variable-sized data, and learn deep features. Their …

Finding tight bounds on the optimal solution is a critical element of practical solution methods for discrete optimization problems. In …