Optimization

We analyze the convergence of a novel policy gradient algorithm (referred to as SPMA) for multi-armed bandits and tabular Markov …

Strategic bidding problems have gained a lot of attention with the introduction of deregulated electricity markets where producers and …

Training large language models (LLMs) for pretraining or adapting to new tasks and domains has become increasingly critical as their …

We analyze the convergence of a novel policy gradient algorithm (referred to as SPMA) for multi-armed bandits and tabular Markov …

Direct Preference Optimization (DPO) is an effective technique that leverages pairwise preference data (usually one chosen and rejected …

Early Exiting (EE) is a promising technique for speeding up inference at the cost of limited performance loss. It adaptively allocates …
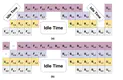
Optimizing large memory-intensive neural networks requires distributing its layers across multiple GPUs (referred to as model …

We investigate the convergence of stochastic mirror descent (SMD) under interpolation in relatively smooth and smooth convex …
Block coordinate descent (BCD) methods are widely used for large-scale numerical optimization because of their cheap iteration costs, …
We propose a continuous optimization framework for discovering a latent directed acyclic graph (DAG) from observational data. Our …