Abstract
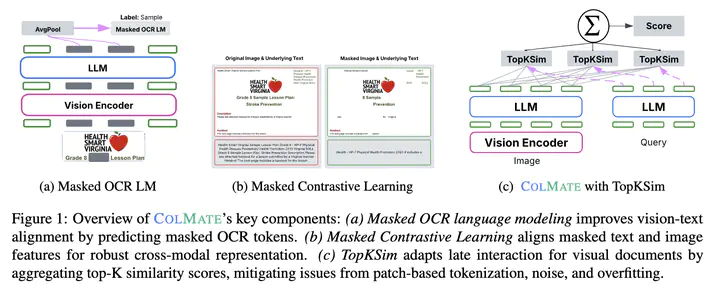
Retrieval-augmented generation has proven practical when models require specialized knowledge or access to the latest data. However, existing methods for multimodal document retrieval often replicate techniques developed for text-only retrieval, whether in how they encode documents, define training objectives, or structure the retrieval components. To address these limitations, we present ColMate, a document retrieval model that bridges the gap between multimodal representation learning and document retrieval. ColMate utilizes a novel OCR-based pretraining objective, a self-supervised masked contrastive learning objective, and a late interaction mechanism more relevant to multimodal document structures and visual characteristics. ColMate obtains 3.61% improvements over existing retrieval models, setting a new state-of-the-art on the ViDoRe V1 and V2 benchmarks.
Shambhavi Mishra
Visiting Researcher
Visiting Researcher at Agent Contextualization located at Montreal, Canada.
Spandana Gella
Research Lead
Research Lead at Agentic Harness & Defenses located at Montreal, Canada.