Multi-Modal Learning
Building reliable computer-use agents requires grounding: accurately connecting natural language instructions to the correct on-screen …

Workflows are a fundamental component of automation in enterprise platforms, enabling the orchestration of tasks, data processing, and …

Aligning visual features with language embeddings is a key challenge in vision-language models (VLMs). The performance of such models …
Scalable Vector Graphics (SVG) offer a powerful format for representing visual designs as interpretable code. Recent advances in …

While image generation techniques are now capable of producing high quality images that respect prompts which span multiple sentences, …

Retrieval-augmented generation has proven practical when models require specialized knowledge or access to the latest data. However, …

Understanding diverse web data and automating web development presents an exciting challenge for agentic multimodal models. While …

Charts are essential to data analysis, transforming raw data into clear visual representations that support human decision-making. …
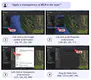
Developing autonomous agents that can navigate diverse Graphical User Interfaces (GUIs) and solve complex tasks is essential for …
Scalable Vector Graphics (SVGs) are vital for modern image rendering due to their scalability and versatility. Previous SVG generation …