Abstract
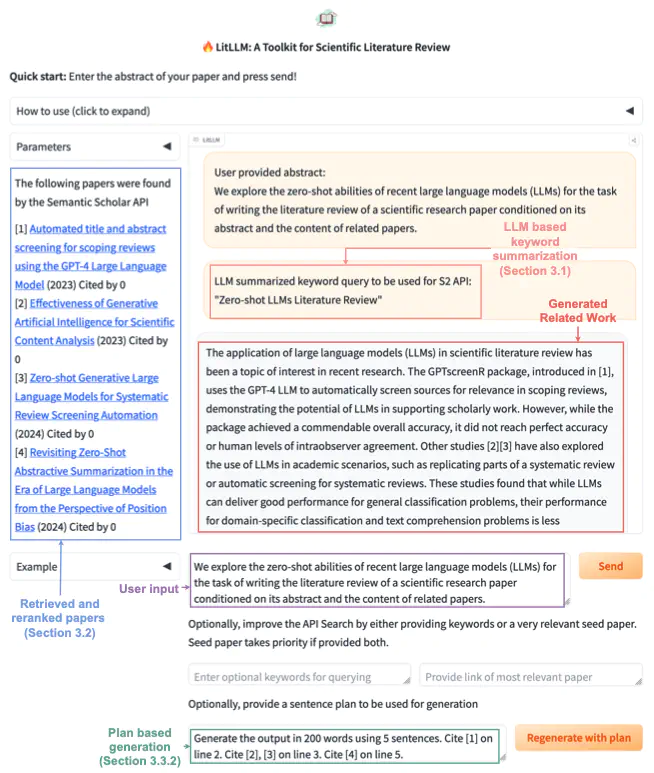
Literature reviews are an essential component of scientific research. We explore the zero-shot abilities of recent large language models (LLMs) for searching and writing the literature review of a scientific research paper based on its abstract. We decompose the task into two components: retrieval of related work and generation of a related work section. We examine the efficacy of different LLM-based strategies for both of these key tasks. First, we present a strategy to automate keyword-based search using LLMs. Second, we compare strategies for re-ranking the search results using LLMs and embeddings. Then, for generation, we propose and examine a novel strategy for literature review generation with LLMs. We first generate a plan for the review and then use it to generate the actual text. While modern LLMs can easily be trained or prompted to condition on all abstracts of papers to be cited to generate a literature review without such intermediate plans, our empirical study shows that these intermediate plans improve the quality of generated literature reviews over vanilla zero-shot generation. This strategy addresses a key problem arising when using more naive approaches plagued by hallucinated references. Furthermore, we also create a new test corpus consisting of recent arXiv papers (with full content) posted after both open-sourced and closed-sourced LLMs that were used in our study were released. This allows us to ensure that our zero-shot experiments do not suffer from test set contamination. Code at github.com
Abhay Puri
Applied Research Scientist
Applied Research Scientist at Agentic Harness & Defenses located at Montreal, Canada.
Issam H. Laradji
Research Scientist
Research Scientist at Agent Contextualization located at Vancouver, Canada.
Christopher Pal
Distinguished Scientist
Distinguished Scientist at AI Research Partnerships & Ecosystem located at Montreal, Canada.