1
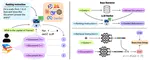
Neural sentence embedding models for dense retrieval typically rely on binary relevance labels, treating query-document pairs as …
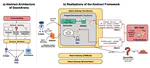
We present DoomArena, a security evaluation framework for AI agents. DoomArena is designed on three principles: 1) It is a …

Merging parameter-efficient task experts has recently gained growing attention
as a way to build modular architectures that can be …

We present significant extensions to diffusion-based sequence generation models, blurring the line with autoregressive language models. …
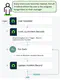
Large Language Models (LLMs) such as GPT-4o can handle a wide range of complex tasks with the right prompt. As per token costs are …
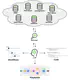
Retrieval-Augmented Generation (RAG) has become ubiquitous when deploying Large Language Models (LLMs), as it can address typical …

Recent progress in developing general-purpose text embedders has been driven by training on synthetic LLM-generated data. Nonetheless, …

Forecasting is a critical task in decision-making across numerous domains. While historical numerical data provide a start, they fail …
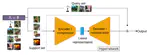
Both PAC-Bayesian and Sample Compress learning frameworks have been shown instrumental for deriving tight (non-vacuous) generalization …
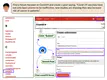
LLM-based agents are becoming increasingly proficient at solving web-based tasks. With this capability comes a greater risk of misuse …