In Defense of Uniform Convergence: Generalization via derandomization with an application to interpolating predictors
Abstract
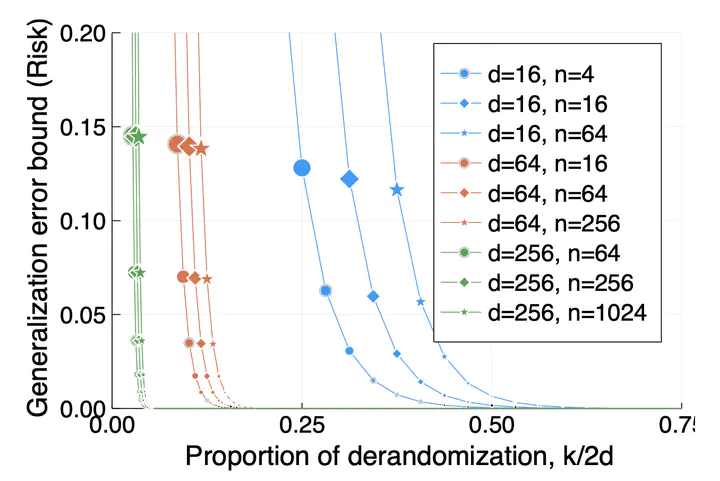
We propose to study the generalization error of a learned predictor ĥ in terms of that of a surrogate (potentially randomized) predictor that is coupled to ĥ and designed to trade empirical risk for control of generalization error. In the case where ĥ interpolates the data, it is interesting to consider theoretical surrogate classifiers that are partially derandomized or rerandomized, e.g., fit to the training data but with modified label noise. We also show that replacing ĥ by its conditional distribution with respect to an arbitrary σ-field is a convenient way to derandomize. We study two examples, inspired by the work of Nagarajan and Kolter (2019) and Bartlett et al. (2019), where the learned classifier ĥ interpolates the training data with high probability, has small risk, and, yet, does not belong to a nonrandom class with a tight uniform bound on two-sided generalization error. At the same time, we bound the risk of ĥ in terms of surrogates constructed by conditioning and denoising, respectively, and shown to belong to nonrandom classes with uniformly small generalization error.