Abstract
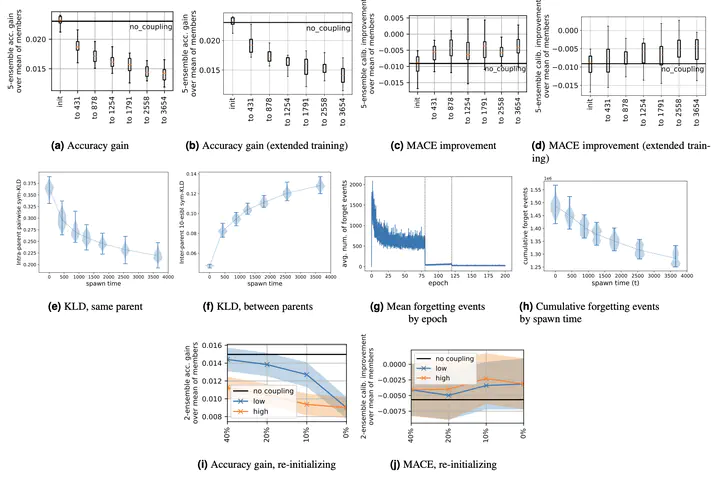
Deep ensembles offer consistent performance gains, both in terms of reduced generalization error and improved predictive uncertainty estimates. These performance gains are attributed to functional diversity among the components that make up the ensembles: ensemble performance increases with the diversity of the components. A standard way to generate a diversity of components from a single data set is to train multiple networks on the same data, but different minibatch orders (and augmentations, etc.). In this work, we study when and how this type of diversity decreases during deep neural network training. Using couplings of multiple training runs, we find that diversity rapidly decreases at the start of training, and that increased training time does not restore this lost diversity, implying that early stages of training make irreversible commitments. In particular, our findings provide further evidence that there is less diversity among functions once linear mode connectivity sets in. This motivates studying perturbations to training that upset linear mode connectivity. We then study how functional diversity is affected by retraining after reinitializing the weights in some layers. We find that we recover significantly more diversity by reinitializing layers closer to the input layer, compared to reinitializing layers closer to the output, also restoring the error barrier.
Marc-Etienne Brunet
Research Lead
Research Lead at Adversarial Testing & Risk Evaluation located at Remote.