StarVLM ReRank: Better UI Grounding via Enhanced Visual Input and Element Position Perception
Abstract
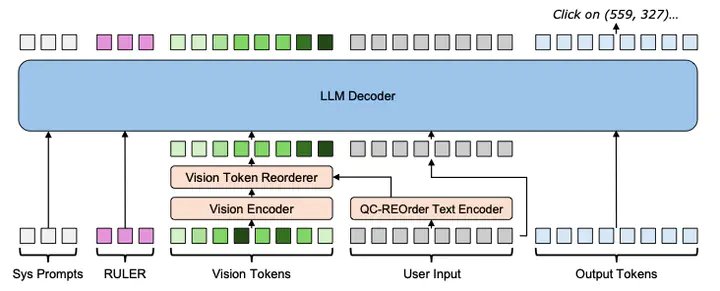
UI grounding is a fundamental task for enterprise workflow automation. This task maps natural language instructions to precise pixel coordinates in graphical interfaces. Current vision-language models fail to achieve the pixel-perfect accuracy required for production deployment, limiting their adoption in business-critical applications. We identify three architectural limitations: query-agnostic visual processing, imbalanced spatial position encodings, and implicit coordinate regression. To address these, we propose a unified framework called StarVLM ReRank, combining: (1) Query-Conditioned REOrder (QC-REOrder) that dynamically reorders image patches based on textual intent, (2) Interleaved MRoPE (I-MRoPE) that provides balanced frequency coverage across spatial dimensions, and (3) RULER tokens that transform coordinate prediction from regression to retrieval. Our approach reframes UI grounding as a spatial reasoning task rather than standard visual grounding. Extensive evaluation on ScreenSpot, Multimodal-Mind2Web, AndroidControl, and OmniACT benchmarks demonstrates consistent improvements across web, mobile, and desktop platforms. By treating pixel-level precision as a first-class architectural concern, our method enables reliable UI automation for enterprise customers demanding robust, resolution-agnostic performance.
Christopher Pal
Distinguished Scientist
Distinguished Scientist at AI Research Partnerships & Ecosystem located at Montreal, QC, Canada.
Perouz Taslakian
Research Lead
Research Lead at Frontier AI Research located at Montreal, QC, Canada.
Spandana Gella
Research Manager
Research Manager at Frontier AI Research located at Montreal, QC, Canada.