DRBench: A Comprehensive Benchmark for Enterprise Deep Research
Abstract
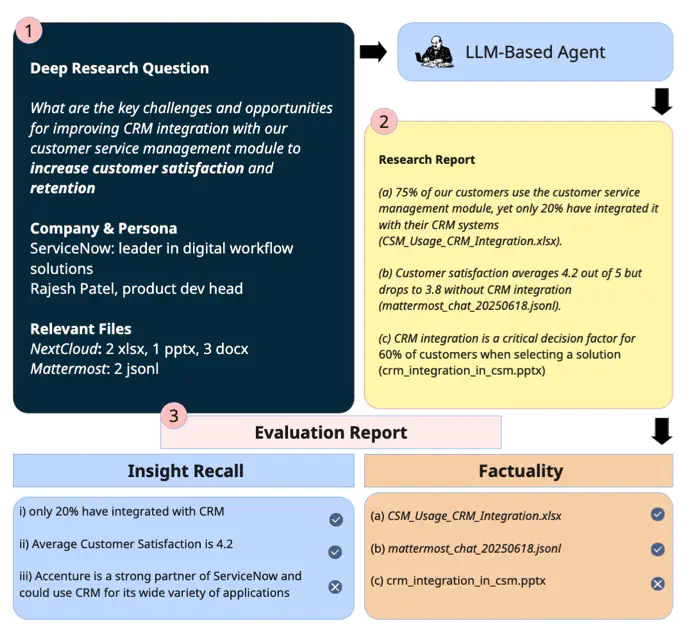
We introduce DRBench, a benchmark for evaluating AI agents on complex, open-ended enterprise deep research tasks. Unlike existing benchmarks focused on surface-level or web-only queries, DRBench assesses an agent’s ability to resolve deep research tasks, which includes resolving high-level queries such as “What changes should we make to our product roadmap to ensure compliance?’’ These tasks are grounded in specific user personas (e.g., product developer) and company contexts (e.g., the ServiceNow organization), and require agents to search across diverse applications accessing both public and private data, reason over heterogeneous formats like spreadsheets, PDFs, websites, and databases, and synthesize their findings into an insightful report. We contribute (1) a suite of complex deep research tasks inspired by ServiceNow spanning three domains: CRM, Strategic Portfolio Management, and Compliance; (2) a realistic enterprise environment composed of several common applications like chat, cloud file system, emails and more; (3) a task generation methodology to generate quality deep research questions and insights grounded on real world web facts and synthesized local facts; and (4) a lightweight evaluation mechanism to score agents’ reports in terms of whether the dominant insights have been extracted and whether the insights in the reports are well-cited. Our experiments benchmark current deep research agents across different methods, revealing performance gaps and observations that would inspire future enterprise deep research agents.
Tianyi Chen
Applied Research Scientist
Applied Research Scientist at AI Research Deployment located at Toronto, ON, Canada.
Miguel Muñoz-Mármol
AI Developer
AI Developer at AI Research Deployment located at Toronto, ON, Canada.
Amirhossein Abaskohi
Visiting Researcher
Visiting Researcher at Frontier AI Research located at Vancouver, BC, Canada.
David Vazquez
Director of AI Research
Director of AI Research at AI Research Management located at Montreal, QC, Canada.
Jason Stanley
Head of AI Research Deployment
Head of AI Research Deployment at AI Research Deployment located at Montreal, QC, Canada.
Alexandre Lacoste
Research Lead
Research Lead at Frontier AI Research located at Montreal, QC, Canada.
Daniel Tremblay
AI Developer
AI Developer at AI Research Deployment located at Montreal, QC, Canada.
Gabriel Huang
Research Scientist
Research Scientist at Frontier AI Research located at Montreal, QC, Canada.
Christopher Pal
Distinguished Scientist
Distinguished Scientist at AI Research Partnerships & Ecosystem located at Montreal, QC, Canada.
Alexandre Drouin
Head of Frontier AI Research
Head of Frontier AI Research at Frontier AI Research located at Montreal, QC, Canada.
Issam H. Laradji
Research Manager
Research Manager at Frontier AI Research located at Vancouver, BC, Canada.