


{kind=link}
{kind=link}
{kind=link}
{kind=link}

Arnoud Kooi

ServiceNow Employee
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
06-30-2017
07:25 AM
In Performance Analytics, Breakdowns are the way to slice and dice the results of your Indicators. They let you filter or group by your data, in order to enable the stakeholders to identify trends and take action on them.
Depending on the settings of your indicator you have 2 levels of breakdown, for example, the out of box Indicator Number of Closed Incidents has got the Breakdowns Priority and Assignment group by default.
This makes it easy to first narrow down the results to the Assignment group you're interested in, and then use the second breakdown to group them by priority.
No need to create an Indicator for a specific Assignment Group or Priority, or any other dimension you can create a breakdown for!
So much for the basics, let's look into a bit more advanced use case.
Creating a breakdown is best suited for structured data, If we stuck to the example of Assignment Group, this is a Reference field to the Group table. Priority is defined as a Choice list. Both examples are structured data.
However, there are examples where you want to breakdown on data in a string field.
There is a good explanation how you can do that in the community, but in this blog, I would like to take a step back and see how we can bring back the structure.
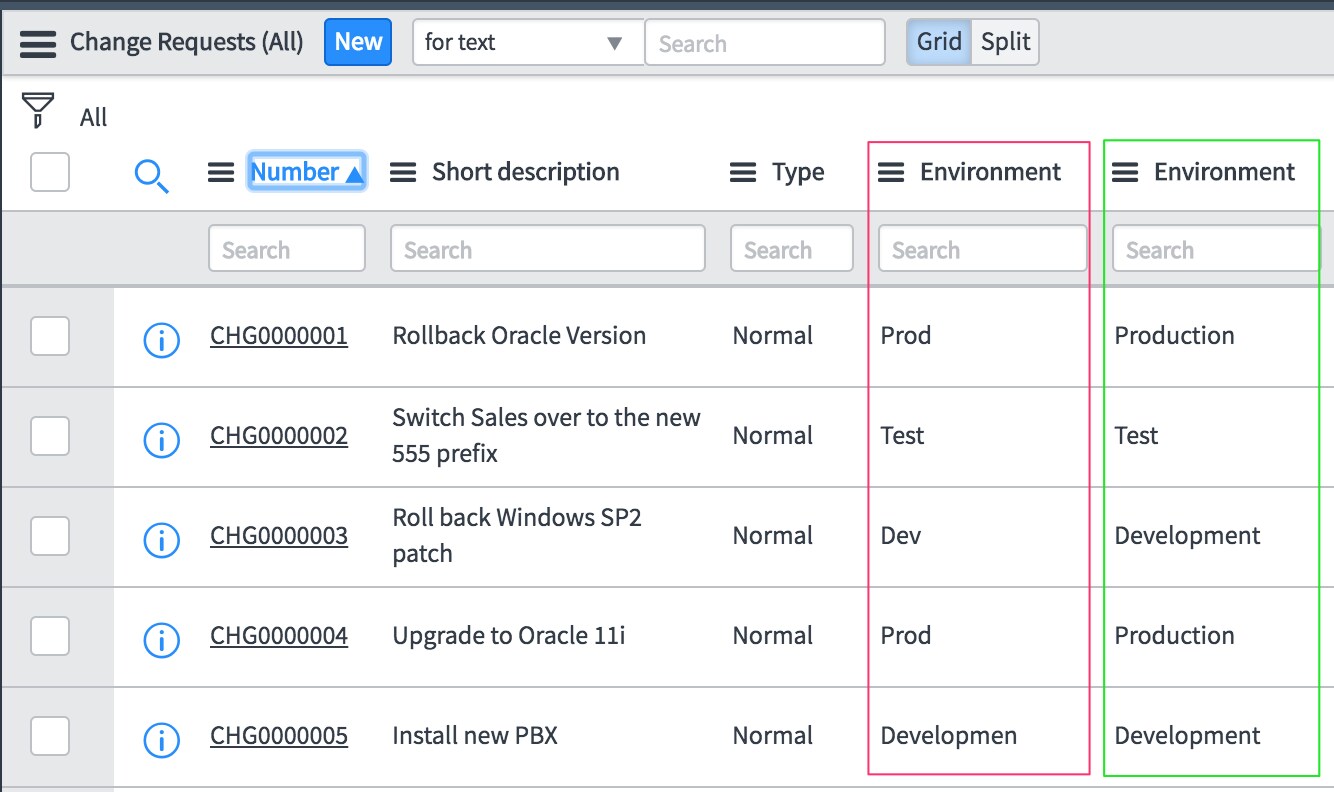
Let's say that your organization has added a field to the Change table called Environment. Goals of the field is to capture the environment the change affects, there should be three options, Development, Test and Production. But when we look at the data we see 7 distinct values. Creating a breakdown on this data results in a breakdown where we can select Pr, Prod and Production. Obviously not what we want, so let's work on the foundation!
The image below shows the situation we start with, and the desired, structured result.
To achieve this, we have two approaches:
- Create an Environment table which we Reference to
- Add the Environments to the Choice list
If we would like to store more information on environments, or plan to make other references to it, I would recommend the approach to create a dedicated table.
But in this example, I assume we only want to capture it in the Change, so I will further explain the way to convert to a choice list.
Create an updateset
You should not execute this on your Production Instance. Therefore, create a updateset that matches your companies naming convention, for example:
PA Breakdown Environment 1
and set it to current.
Add the new field
After that, we can go to the dictionary of the change table (change_request) and add the new Environment field by clicking New.
Type: Choice
Label: Environment
Name: u_environ (As u_environment is probably taken)
Choice: Dropdown with --None--
Right-click in the header and choose Save.
Add choices
After that, we can add the choices using the related list that appeared.
Value | Label | Sequence |
dev | Development | 10 |
test | Test | 20 |
prod | Production | 30 |
Fill the new column
The next step might be the hardest part; we are now ready for the actual data improvement. If you have a table with thousands of rows, you probably want to automate this.
Below you see an example script to do so.
Run this on your environment as a background script. Be aware that after testing you must also run this in your production environment, after deploying the updateset.
//example script to help convert unstructured data to sys choice options
//review and test before using this in your instance
//Set your variables
var myTable = "incident"; //change to your table
var myOldField = "u_caller_mood"; //change to your existing field;
var myNewField = "u_caller_emotion"; //change to your new field;
var automatch = true; //Set to false after first time you run this script
var myOldNewPairs =
[
["oldValue","newValue"]
];
// define old new values to replace example [["unhappy","angry"],["","new"]]]
//Review and alter following to your needs IF needed
var gr;
var vals = []; //To contain all values
var lbls = []; //To contain all labels
var au = new ArrayUtil(); //Contains helper fuinctions for arrays
//Fill the arrays form choicelist
var ch = new GlideRecord('sys_choice');
ch.addQuery("name",myTable);
ch.addQuery("element",myNewField);
ch.query();
while (ch.next()) {
vals.push(ch.getValue('value').toLowerCase());
lbls.push(ch.getValue('label').toLowerCase());
}
//set the new values based on matches on label or value in syschoice table
if (automatch){ //only needs to run first time
gr = new GlideRecord(myTable);
gr.addNullQuery(myNewField);
gr.query();
while (gr.next()) {
gr.setWorkflow(false); //dont trigger anything
if (au.indexOf(vals, gr[myOldField].toLowerCase()) >= 0){
//match on values, just copy
gr[myNewField] = vals[au.indexOf(vals, gr[myOldField].toLowerCase())];
gr.update();
}
if (au.indexOf(lbls, gr[myOldField].toLowerCase()) >= 0){
//match on label, grab index from values array
gr[myNewField] = vals[au.indexOf(lbls, gr[myOldField].toLowerCase())];
gr.update();
}
}
}
//loop over the old new value pairs
for (var i = 0; i< myOldNewPairs.length; i++){
gr = new GlideRecord(myTable);
gr.addQuery(myOldField, myOldNewPairs[i][0]);
gr.query();
while (gr.next()) {
gr.setWorkflow(false); //dont trigger anything
if (au.indexOf(vals, myOldNewPairs[i][1].toLowerCase()) >= 0){
//check if its a valid value
gr[myNewField] = myOldNewPairs[i][1];
gr.update();
}
}
}
//helper to output remaining unstructured values
var ga = new GlideAggregate(myTable);
ga.addNullQuery(myNewField);
ga.addAggregate('COUNT', myOldField );
ga.query();
var output = "\n// Helper Array (replace value with one of following choice list values)\n"+
"// Copy paste below to myOldNewPairs and adjust values \n\n// Possible new values: " +
vals.toString()
+'\n[\n ["oldValue","newValue"]';
while (ga.next()) {
if (ga[myOldField].toString().length > 0)
output += ',\n ["' + ga[myOldField]+ '","value"]'
}
output += "\n]";
gs.print(output);
After the script is run, the result is the following.

The values in the right Environment column are now the cleaned up version. This is the data quality we can build upon!
Please review the following video to check out a demonstration how these steps are executed in a demo instance.
Labels:
- 2,549 Views
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.