1
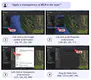
Developing autonomous agents that can navigate diverse Graphical User Interfaces (GUIs) and solve complex tasks is essential for …
Scalable Vector Graphics (SVGs) are vital for modern image rendering due to their scalability and versatility. Previous SVG generation …
Causal discovery aims to automatically uncover causal relationships from data, a capability with significant potential across many …

We analyze the convergence of a novel policy gradient algorithm (referred to as SPMA) for multi-armed bandits and tabular Markov …
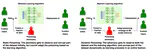
The rise of foundation models fine-tuned on human feedback from potentially untrusted users has increased the risk of adversarial data …

The sample compression theory provides generalization guarantees for predictors that can be fully defined using a subset of the …
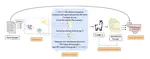
Existing approaches for low-resource text summarization primarily employ large language models (LLMs) like GPT-3 or GPT-4 at inference …

Graph databases like Neo4j are gaining popularity for handling complex, interconnected data, over traditional relational databases in …

Instruction finetuning (IFT) is critical for aligning Large Language Models (LLMs) to follow instructions. While many effective IFT …

Multilingual LLMs have achieved remarkable benchmark performance, but we find they continue to underperform on non-Latin script …